Zentropy theory: Bridging materials gene to materials properties
3
2024
... 合金设计是材料学领域永恒的热点话题,而随着大数据与人工智能时代的到来,基于数据驱动理念的材料基因工程更受到了业内的广泛关注与认可[1,2].数据驱动式的研究方法作为科学发展的“第四范式”[3],其变革性的研究理念对“第三范式”的物理模型与理论计算带来了巨大的冲击[4,5].首先,数据驱动(以人工智能为主)的主要优势在于无需先建立基于物理机制的本构方程,再进行模拟计算,因此其理论上可以规避金属结构材料中大量复杂难明的多尺度机制问题,直接形成可满足合金设计基本要求的成分、工艺与目标性能间的高精度计算方法,从而指导设计.但同时,上述优势也为数据驱动方法带来了相应的弊端,即众所周知的可解释性问题,一个“黑箱”式的模型会为合金设计过程带来诸多不确定的风险性.因此,目前基于集成计算的物理模型驱动理念和基于人工智能的数据驱动理念是材料基因工程领域中2个偏向于并行式关系的技术路线[5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
... 首先,物理模型与人工智能间的关系,其本质可归结于上述提到的模型“准确性”与“可解释性”之间的冲突,这种冲突一直存在并被广泛认知.由于本文后续的大多数论述会围绕“准确性”与“可解释性”展开,所以首先需要对这2个名词在本文中的定义与量化评价方法加以明确.“准确性”是模拟计算中的标准名词,在本文中是指模型对合金设计中关注的目标性能的预测准确性,可通过对比模型预测值与实验测定的性能实际值来量化计算(例如拟和优度(R2)或平均绝对误差(MAE)).“可解释性”一般在人工智能领域是指模型与人们普适性认知的客观规律相吻合,因而其计算过程或结果具有可被常人理解的能力.其常见的外在表现形式是模型不但对已有的训练样本适用,更可普适性反映更多新样本的规律与通用机制,但其目前并没有公认的标准量化评价方法,本文主要使用“域外扩展能力”(out-of-distribution generalization)来量化评价模型的“可解释性”,即认为2者之间是互为充要条件的关系.这一观点也在人工智能的“稳定学习”研究[7]中被证明,即一个在物理机制上更合理的模型必然促使其域外扩展能力增强,同时,一个模型的域外扩展能力变强,则也可以反推出该模型一定是找到了与现实更加吻合的物理机制,2者在本质上是一个概念.值得注意的是,“稳定学习”作为一个近年来新发展的理论方法,其通用性还有待进一步考证.但由于“可解释性”本身是一个极难量化的抽象概念,因此在缺少其他更为合理、直观的量化方式前提下,本文选择使用模型的域外扩展能力作为“可解释性”的量化评判标准.关于模型“准确性”与“可解释性”之间的冲突,Zhong等[8]已提及了类似的问题:人工智能模型往往存在准确性与可解释性之间的互斥关系(图1a),例如绝大多数深度学习模型有极强的数据拟合能力,可表现出高准确性,但其是典型的“黑箱”模型,可解释性低;而决策树等具有可解释性的人工智能模型的数据拟合能力要远低于深度学习网络,即模型准确性上存在劣势.这一互斥关系进一步扩展至计算材料宏观力学性能的多尺度物理模型中也依然适用,大多数长链条集成或宏观性能预测的物理模型具有强可解释性,但其数据拟合能力与准确度往往低于人工智能模型,这一观点已被诸多案例所证实[1,4,9]. ...
... 由此可见,物理冶金原理指导人工智能方法的核心为“指导”,而这个“指导”背后的数学理论基础是物理方程/机制提供的“弱约束”.只有物理模型/机制在人工智能训练中起到了这种“弱约束”的作用,才可达到打破域外扩展能力与准确性互斥关系的效果.反之,在与人工智能的结合过程中,如果物理模型/机制并不起到这种“弱约束”的“指导”作用,即使模型建立过程中同时用到了物理模型与人工智能算法,其也只能起到一加一等于二或者小于二的作用,无法打破上述互斥关系.例如,目前合金设计领域有大量的人工智能建模工作使用物理模型计算提供数据标签,包括通过物理模型计算合金成分、工艺方案所对应的性能值,再通过人工智能直接学习这些“成分-工艺-性能”间的数学关联并指导合金设计等.此类型的工作虽然也有物理模型与人工智能模型的共同参与,但实际上2者的结合并不紧密,物理模型在提供数据时依然要独立面对机制扰动带来的准确性问题,人工智能也依然独立进行数据学习,难以获得域外扩展过程中的约束指导.因此,虽然该类型工作目前已在合金设计领域形成系统而全面的研究进展[1,2],但本文后续并不以该类型工作为论述重点,而是主要聚焦于物理冶金原理指导人工智能方法分别在数值数据指导、图像数据指导和机制指导3个层次的应用示范案例. ...
叠熵理论: 从材料基因到材料性能
3
2024
... 合金设计是材料学领域永恒的热点话题,而随着大数据与人工智能时代的到来,基于数据驱动理念的材料基因工程更受到了业内的广泛关注与认可[1,2].数据驱动式的研究方法作为科学发展的“第四范式”[3],其变革性的研究理念对“第三范式”的物理模型与理论计算带来了巨大的冲击[4,5].首先,数据驱动(以人工智能为主)的主要优势在于无需先建立基于物理机制的本构方程,再进行模拟计算,因此其理论上可以规避金属结构材料中大量复杂难明的多尺度机制问题,直接形成可满足合金设计基本要求的成分、工艺与目标性能间的高精度计算方法,从而指导设计.但同时,上述优势也为数据驱动方法带来了相应的弊端,即众所周知的可解释性问题,一个“黑箱”式的模型会为合金设计过程带来诸多不确定的风险性.因此,目前基于集成计算的物理模型驱动理念和基于人工智能的数据驱动理念是材料基因工程领域中2个偏向于并行式关系的技术路线[5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
... 首先,物理模型与人工智能间的关系,其本质可归结于上述提到的模型“准确性”与“可解释性”之间的冲突,这种冲突一直存在并被广泛认知.由于本文后续的大多数论述会围绕“准确性”与“可解释性”展开,所以首先需要对这2个名词在本文中的定义与量化评价方法加以明确.“准确性”是模拟计算中的标准名词,在本文中是指模型对合金设计中关注的目标性能的预测准确性,可通过对比模型预测值与实验测定的性能实际值来量化计算(例如拟和优度(R2)或平均绝对误差(MAE)).“可解释性”一般在人工智能领域是指模型与人们普适性认知的客观规律相吻合,因而其计算过程或结果具有可被常人理解的能力.其常见的外在表现形式是模型不但对已有的训练样本适用,更可普适性反映更多新样本的规律与通用机制,但其目前并没有公认的标准量化评价方法,本文主要使用“域外扩展能力”(out-of-distribution generalization)来量化评价模型的“可解释性”,即认为2者之间是互为充要条件的关系.这一观点也在人工智能的“稳定学习”研究[7]中被证明,即一个在物理机制上更合理的模型必然促使其域外扩展能力增强,同时,一个模型的域外扩展能力变强,则也可以反推出该模型一定是找到了与现实更加吻合的物理机制,2者在本质上是一个概念.值得注意的是,“稳定学习”作为一个近年来新发展的理论方法,其通用性还有待进一步考证.但由于“可解释性”本身是一个极难量化的抽象概念,因此在缺少其他更为合理、直观的量化方式前提下,本文选择使用模型的域外扩展能力作为“可解释性”的量化评判标准.关于模型“准确性”与“可解释性”之间的冲突,Zhong等[8]已提及了类似的问题:人工智能模型往往存在准确性与可解释性之间的互斥关系(图1a),例如绝大多数深度学习模型有极强的数据拟合能力,可表现出高准确性,但其是典型的“黑箱”模型,可解释性低;而决策树等具有可解释性的人工智能模型的数据拟合能力要远低于深度学习网络,即模型准确性上存在劣势.这一互斥关系进一步扩展至计算材料宏观力学性能的多尺度物理模型中也依然适用,大多数长链条集成或宏观性能预测的物理模型具有强可解释性,但其数据拟合能力与准确度往往低于人工智能模型,这一观点已被诸多案例所证实[1,4,9]. ...
... 由此可见,物理冶金原理指导人工智能方法的核心为“指导”,而这个“指导”背后的数学理论基础是物理方程/机制提供的“弱约束”.只有物理模型/机制在人工智能训练中起到了这种“弱约束”的作用,才可达到打破域外扩展能力与准确性互斥关系的效果.反之,在与人工智能的结合过程中,如果物理模型/机制并不起到这种“弱约束”的“指导”作用,即使模型建立过程中同时用到了物理模型与人工智能算法,其也只能起到一加一等于二或者小于二的作用,无法打破上述互斥关系.例如,目前合金设计领域有大量的人工智能建模工作使用物理模型计算提供数据标签,包括通过物理模型计算合金成分、工艺方案所对应的性能值,再通过人工智能直接学习这些“成分-工艺-性能”间的数学关联并指导合金设计等.此类型的工作虽然也有物理模型与人工智能模型的共同参与,但实际上2者的结合并不紧密,物理模型在提供数据时依然要独立面对机制扰动带来的准确性问题,人工智能也依然独立进行数据学习,难以获得域外扩展过程中的约束指导.因此,虽然该类型工作目前已在合金设计领域形成系统而全面的研究进展[1,2],但本文后续并不以该类型工作为论述重点,而是主要聚焦于物理冶金原理指导人工智能方法分别在数值数据指导、图像数据指导和机制指导3个层次的应用示范案例. ...
Machine learning for materials research and development
2
2021
... 合金设计是材料学领域永恒的热点话题,而随着大数据与人工智能时代的到来,基于数据驱动理念的材料基因工程更受到了业内的广泛关注与认可[1,2].数据驱动式的研究方法作为科学发展的“第四范式”[3],其变革性的研究理念对“第三范式”的物理模型与理论计算带来了巨大的冲击[4,5].首先,数据驱动(以人工智能为主)的主要优势在于无需先建立基于物理机制的本构方程,再进行模拟计算,因此其理论上可以规避金属结构材料中大量复杂难明的多尺度机制问题,直接形成可满足合金设计基本要求的成分、工艺与目标性能间的高精度计算方法,从而指导设计.但同时,上述优势也为数据驱动方法带来了相应的弊端,即众所周知的可解释性问题,一个“黑箱”式的模型会为合金设计过程带来诸多不确定的风险性.因此,目前基于集成计算的物理模型驱动理念和基于人工智能的数据驱动理念是材料基因工程领域中2个偏向于并行式关系的技术路线[5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
... 由此可见,物理冶金原理指导人工智能方法的核心为“指导”,而这个“指导”背后的数学理论基础是物理方程/机制提供的“弱约束”.只有物理模型/机制在人工智能训练中起到了这种“弱约束”的作用,才可达到打破域外扩展能力与准确性互斥关系的效果.反之,在与人工智能的结合过程中,如果物理模型/机制并不起到这种“弱约束”的“指导”作用,即使模型建立过程中同时用到了物理模型与人工智能算法,其也只能起到一加一等于二或者小于二的作用,无法打破上述互斥关系.例如,目前合金设计领域有大量的人工智能建模工作使用物理模型计算提供数据标签,包括通过物理模型计算合金成分、工艺方案所对应的性能值,再通过人工智能直接学习这些“成分-工艺-性能”间的数学关联并指导合金设计等.此类型的工作虽然也有物理模型与人工智能模型的共同参与,但实际上2者的结合并不紧密,物理模型在提供数据时依然要独立面对机制扰动带来的准确性问题,人工智能也依然独立进行数据学习,难以获得域外扩展过程中的约束指导.因此,虽然该类型工作目前已在合金设计领域形成系统而全面的研究进展[1,2],但本文后续并不以该类型工作为论述重点,而是主要聚焦于物理冶金原理指导人工智能方法分别在数值数据指导、图像数据指导和机制指导3个层次的应用示范案例. ...
机器学习在材料研发中的应用
2
2021
... 合金设计是材料学领域永恒的热点话题,而随着大数据与人工智能时代的到来,基于数据驱动理念的材料基因工程更受到了业内的广泛关注与认可[1,2].数据驱动式的研究方法作为科学发展的“第四范式”[3],其变革性的研究理念对“第三范式”的物理模型与理论计算带来了巨大的冲击[4,5].首先,数据驱动(以人工智能为主)的主要优势在于无需先建立基于物理机制的本构方程,再进行模拟计算,因此其理论上可以规避金属结构材料中大量复杂难明的多尺度机制问题,直接形成可满足合金设计基本要求的成分、工艺与目标性能间的高精度计算方法,从而指导设计.但同时,上述优势也为数据驱动方法带来了相应的弊端,即众所周知的可解释性问题,一个“黑箱”式的模型会为合金设计过程带来诸多不确定的风险性.因此,目前基于集成计算的物理模型驱动理念和基于人工智能的数据驱动理念是材料基因工程领域中2个偏向于并行式关系的技术路线[5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
... 由此可见,物理冶金原理指导人工智能方法的核心为“指导”,而这个“指导”背后的数学理论基础是物理方程/机制提供的“弱约束”.只有物理模型/机制在人工智能训练中起到了这种“弱约束”的作用,才可达到打破域外扩展能力与准确性互斥关系的效果.反之,在与人工智能的结合过程中,如果物理模型/机制并不起到这种“弱约束”的“指导”作用,即使模型建立过程中同时用到了物理模型与人工智能算法,其也只能起到一加一等于二或者小于二的作用,无法打破上述互斥关系.例如,目前合金设计领域有大量的人工智能建模工作使用物理模型计算提供数据标签,包括通过物理模型计算合金成分、工艺方案所对应的性能值,再通过人工智能直接学习这些“成分-工艺-性能”间的数学关联并指导合金设计等.此类型的工作虽然也有物理模型与人工智能模型的共同参与,但实际上2者的结合并不紧密,物理模型在提供数据时依然要独立面对机制扰动带来的准确性问题,人工智能也依然独立进行数据学习,难以获得域外扩展过程中的约束指导.因此,虽然该类型工作目前已在合金设计领域形成系统而全面的研究进展[1,2],但本文后续并不以该类型工作为论述重点,而是主要聚焦于物理冶金原理指导人工智能方法分别在数值数据指导、图像数据指导和机制指导3个层次的应用示范案例. ...
Perspective: Materials informatics and big data: Realization of the “fourth paradigm” of science in materials science
1
2016
... 合金设计是材料学领域永恒的热点话题,而随着大数据与人工智能时代的到来,基于数据驱动理念的材料基因工程更受到了业内的广泛关注与认可[1,2].数据驱动式的研究方法作为科学发展的“第四范式”[3],其变革性的研究理念对“第三范式”的物理模型与理论计算带来了巨大的冲击[4,5].首先,数据驱动(以人工智能为主)的主要优势在于无需先建立基于物理机制的本构方程,再进行模拟计算,因此其理论上可以规避金属结构材料中大量复杂难明的多尺度机制问题,直接形成可满足合金设计基本要求的成分、工艺与目标性能间的高精度计算方法,从而指导设计.但同时,上述优势也为数据驱动方法带来了相应的弊端,即众所周知的可解释性问题,一个“黑箱”式的模型会为合金设计过程带来诸多不确定的风险性.因此,目前基于集成计算的物理模型驱动理念和基于人工智能的数据驱动理念是材料基因工程领域中2个偏向于并行式关系的技术路线[5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
Multiscale modeling meets machine learning: What can we learn?
2
2021
... 合金设计是材料学领域永恒的热点话题,而随着大数据与人工智能时代的到来,基于数据驱动理念的材料基因工程更受到了业内的广泛关注与认可[1,2].数据驱动式的研究方法作为科学发展的“第四范式”[3],其变革性的研究理念对“第三范式”的物理模型与理论计算带来了巨大的冲击[4,5].首先,数据驱动(以人工智能为主)的主要优势在于无需先建立基于物理机制的本构方程,再进行模拟计算,因此其理论上可以规避金属结构材料中大量复杂难明的多尺度机制问题,直接形成可满足合金设计基本要求的成分、工艺与目标性能间的高精度计算方法,从而指导设计.但同时,上述优势也为数据驱动方法带来了相应的弊端,即众所周知的可解释性问题,一个“黑箱”式的模型会为合金设计过程带来诸多不确定的风险性.因此,目前基于集成计算的物理模型驱动理念和基于人工智能的数据驱动理念是材料基因工程领域中2个偏向于并行式关系的技术路线[5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
... 首先,物理模型与人工智能间的关系,其本质可归结于上述提到的模型“准确性”与“可解释性”之间的冲突,这种冲突一直存在并被广泛认知.由于本文后续的大多数论述会围绕“准确性”与“可解释性”展开,所以首先需要对这2个名词在本文中的定义与量化评价方法加以明确.“准确性”是模拟计算中的标准名词,在本文中是指模型对合金设计中关注的目标性能的预测准确性,可通过对比模型预测值与实验测定的性能实际值来量化计算(例如拟和优度(R2)或平均绝对误差(MAE)).“可解释性”一般在人工智能领域是指模型与人们普适性认知的客观规律相吻合,因而其计算过程或结果具有可被常人理解的能力.其常见的外在表现形式是模型不但对已有的训练样本适用,更可普适性反映更多新样本的规律与通用机制,但其目前并没有公认的标准量化评价方法,本文主要使用“域外扩展能力”(out-of-distribution generalization)来量化评价模型的“可解释性”,即认为2者之间是互为充要条件的关系.这一观点也在人工智能的“稳定学习”研究[7]中被证明,即一个在物理机制上更合理的模型必然促使其域外扩展能力增强,同时,一个模型的域外扩展能力变强,则也可以反推出该模型一定是找到了与现实更加吻合的物理机制,2者在本质上是一个概念.值得注意的是,“稳定学习”作为一个近年来新发展的理论方法,其通用性还有待进一步考证.但由于“可解释性”本身是一个极难量化的抽象概念,因此在缺少其他更为合理、直观的量化方式前提下,本文选择使用模型的域外扩展能力作为“可解释性”的量化评判标准.关于模型“准确性”与“可解释性”之间的冲突,Zhong等[8]已提及了类似的问题:人工智能模型往往存在准确性与可解释性之间的互斥关系(图1a),例如绝大多数深度学习模型有极强的数据拟合能力,可表现出高准确性,但其是典型的“黑箱”模型,可解释性低;而决策树等具有可解释性的人工智能模型的数据拟合能力要远低于深度学习网络,即模型准确性上存在劣势.这一互斥关系进一步扩展至计算材料宏观力学性能的多尺度物理模型中也依然适用,大多数长链条集成或宏观性能预测的物理模型具有强可解释性,但其数据拟合能力与准确度往往低于人工智能模型,这一观点已被诸多案例所证实[1,4,9]. ...
Progress in materials genome engineering in China
2
2020
... 合金设计是材料学领域永恒的热点话题,而随着大数据与人工智能时代的到来,基于数据驱动理念的材料基因工程更受到了业内的广泛关注与认可[1,2].数据驱动式的研究方法作为科学发展的“第四范式”[3],其变革性的研究理念对“第三范式”的物理模型与理论计算带来了巨大的冲击[4,5].首先,数据驱动(以人工智能为主)的主要优势在于无需先建立基于物理机制的本构方程,再进行模拟计算,因此其理论上可以规避金属结构材料中大量复杂难明的多尺度机制问题,直接形成可满足合金设计基本要求的成分、工艺与目标性能间的高精度计算方法,从而指导设计.但同时,上述优势也为数据驱动方法带来了相应的弊端,即众所周知的可解释性问题,一个“黑箱”式的模型会为合金设计过程带来诸多不确定的风险性.因此,目前基于集成计算的物理模型驱动理念和基于人工智能的数据驱动理念是材料基因工程领域中2个偏向于并行式关系的技术路线[5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
... [5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
中国材料基因工程研究进展
2
2020
... 合金设计是材料学领域永恒的热点话题,而随着大数据与人工智能时代的到来,基于数据驱动理念的材料基因工程更受到了业内的广泛关注与认可[1,2].数据驱动式的研究方法作为科学发展的“第四范式”[3],其变革性的研究理念对“第三范式”的物理模型与理论计算带来了巨大的冲击[4,5].首先,数据驱动(以人工智能为主)的主要优势在于无需先建立基于物理机制的本构方程,再进行模拟计算,因此其理论上可以规避金属结构材料中大量复杂难明的多尺度机制问题,直接形成可满足合金设计基本要求的成分、工艺与目标性能间的高精度计算方法,从而指导设计.但同时,上述优势也为数据驱动方法带来了相应的弊端,即众所周知的可解释性问题,一个“黑箱”式的模型会为合金设计过程带来诸多不确定的风险性.因此,目前基于集成计算的物理模型驱动理念和基于人工智能的数据驱动理念是材料基因工程领域中2个偏向于并行式关系的技术路线[5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
... [5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
Artificial intelligence for science in quantum, atomistic, and continuum systems
3
2023
... 合金设计是材料学领域永恒的热点话题,而随着大数据与人工智能时代的到来,基于数据驱动理念的材料基因工程更受到了业内的广泛关注与认可[1,2].数据驱动式的研究方法作为科学发展的“第四范式”[3],其变革性的研究理念对“第三范式”的物理模型与理论计算带来了巨大的冲击[4,5].首先,数据驱动(以人工智能为主)的主要优势在于无需先建立基于物理机制的本构方程,再进行模拟计算,因此其理论上可以规避金属结构材料中大量复杂难明的多尺度机制问题,直接形成可满足合金设计基本要求的成分、工艺与目标性能间的高精度计算方法,从而指导设计.但同时,上述优势也为数据驱动方法带来了相应的弊端,即众所周知的可解释性问题,一个“黑箱”式的模型会为合金设计过程带来诸多不确定的风险性.因此,目前基于集成计算的物理模型驱动理念和基于人工智能的数据驱动理念是材料基因工程领域中2个偏向于并行式关系的技术路线[5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
... [6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
... 如果上述例子有助于研究者理解GAN的不稳定性及其在材料学小数据环境下应用的局限性,那本文后续推荐另一种算法替代GAN的原因也就很清晰了,这种算法就是变分自编码器(variational autoencoder,VAE)[88,89],其也是AI4Sci领域中受到广泛关注的算法之一[6].与GAN的区别是,VAE是自监督学习算法.在小样本环境下,VAE不容易像GAN一样过度发散而导致一些图像无法生成或生成的图像不合理的问题(图9[73,76,87,90]).当然,数据量不足会导致VAE生成的图像模糊.但在分析组织与性能关系时,一个模糊的组织图片也基本不影响使用,可以权当拍摄组织照片时焦距未能调好,其总比一张错误的组织照片要有价值.因此,VAE在基于真实组织图像的合金设计中已有成功的案例.Pei等[89]通过对钢铁材料组织的自监督学习建立了可进行钢铁材料组织生成的VAE模型,该模型可以为开发更优力学性能的钢铁材料提供定性的搜索方向指导.虽然该工作没能给出可进行精准定量化合金设计的模型,但其对于VAE算法在合金设计方向上的应用具有里程碑式的意义.而Ma等[90]则以双相钢为研究对象,提供了一个更具参考价值的合金设计案例,其使用22个合金样本获得组织照片,照片经裁剪后为700余条图像样本,建立了双相钢下的VAE模型,并且真正实现了显微组织图像与成分、工艺、性能间的全链条预测,并且基于该全链条预测模型定量化设计了多种高性能双相钢,实验验证结果良好.模型所提方案无论在显微组织图像还是最终力学性能的预测结果方面都与实际制备出的钢种吻合,充分证明了该方法的有效性,而且22个合金获得的700余条组织图片样本需求显然比GAN所需的5000,甚至上万图片样本要更为人性化.当然,虽然VAE算法在双相钢中实现了“成分-工艺-组织图像-性能”全链条预测与指导合金设计的理想模式,但其稳定性如何,在预测的组织图像信息指导下模型的域外扩展能力是否得到了切实的改善,是否打破了准确性与域外扩展能力的互斥关系,以及在更多合金体系下VAE算法是否依然适用,诸多问题都尚待探索与解答,基于“成分-工艺-组织图像-性能”全链条预测理念的合金设计方法刚刚迈出历史性的第一步,仍然任重而道远. ...
Stable learning establishes some common ground between causal inference and machine learning
3
2022
... 合金设计是材料学领域永恒的热点话题,而随着大数据与人工智能时代的到来,基于数据驱动理念的材料基因工程更受到了业内的广泛关注与认可[1,2].数据驱动式的研究方法作为科学发展的“第四范式”[3],其变革性的研究理念对“第三范式”的物理模型与理论计算带来了巨大的冲击[4,5].首先,数据驱动(以人工智能为主)的主要优势在于无需先建立基于物理机制的本构方程,再进行模拟计算,因此其理论上可以规避金属结构材料中大量复杂难明的多尺度机制问题,直接形成可满足合金设计基本要求的成分、工艺与目标性能间的高精度计算方法,从而指导设计.但同时,上述优势也为数据驱动方法带来了相应的弊端,即众所周知的可解释性问题,一个“黑箱”式的模型会为合金设计过程带来诸多不确定的风险性.因此,目前基于集成计算的物理模型驱动理念和基于人工智能的数据驱动理念是材料基因工程领域中2个偏向于并行式关系的技术路线[5].基于数据驱动理念的研究工作经常以物理模型为对比,以体现其模型的计算精度与计算效率优势[6],而基于物理模型驱动理念的工作则以人工智能模型为对比,以体现其在可解释性与合理性方面的优势[7].上述争论也间接驱动了近年来基于AI4Sci理念的“第五范式”在合金设计领域的发展[6].因此,本文的主旨是通过对目前材料基因工程领域部分代表性工作的综述,在合金设计领域范围内,阐明分别代表第三、四、五科学范式的物理模型、人工智能与AI4Sci之间的协同、替代和发展关系,并为各方向提出可供参考的未来研究思路与技术方法指导.需要特别强调的是,本文并非在全科学领域探讨3个科学范式的优劣性.本文所有讨论仅局限在合金设计范畴,以关注宏观力学性能的块体金属结构材料为主,不涉及陶瓷、半导体、无机非等非合金功能材料设计领域,更不涉及非合金设计的更广泛研究领域. ...
... 首先,物理模型与人工智能间的关系,其本质可归结于上述提到的模型“准确性”与“可解释性”之间的冲突,这种冲突一直存在并被广泛认知.由于本文后续的大多数论述会围绕“准确性”与“可解释性”展开,所以首先需要对这2个名词在本文中的定义与量化评价方法加以明确.“准确性”是模拟计算中的标准名词,在本文中是指模型对合金设计中关注的目标性能的预测准确性,可通过对比模型预测值与实验测定的性能实际值来量化计算(例如拟和优度(R2)或平均绝对误差(MAE)).“可解释性”一般在人工智能领域是指模型与人们普适性认知的客观规律相吻合,因而其计算过程或结果具有可被常人理解的能力.其常见的外在表现形式是模型不但对已有的训练样本适用,更可普适性反映更多新样本的规律与通用机制,但其目前并没有公认的标准量化评价方法,本文主要使用“域外扩展能力”(out-of-distribution generalization)来量化评价模型的“可解释性”,即认为2者之间是互为充要条件的关系.这一观点也在人工智能的“稳定学习”研究[7]中被证明,即一个在物理机制上更合理的模型必然促使其域外扩展能力增强,同时,一个模型的域外扩展能力变强,则也可以反推出该模型一定是找到了与现实更加吻合的物理机制,2者在本质上是一个概念.值得注意的是,“稳定学习”作为一个近年来新发展的理论方法,其通用性还有待进一步考证.但由于“可解释性”本身是一个极难量化的抽象概念,因此在缺少其他更为合理、直观的量化方式前提下,本文选择使用模型的域外扩展能力作为“可解释性”的量化评判标准.关于模型“准确性”与“可解释性”之间的冲突,Zhong等[8]已提及了类似的问题:人工智能模型往往存在准确性与可解释性之间的互斥关系(图1a),例如绝大多数深度学习模型有极强的数据拟合能力,可表现出高准确性,但其是典型的“黑箱”模型,可解释性低;而决策树等具有可解释性的人工智能模型的数据拟合能力要远低于深度学习网络,即模型准确性上存在劣势.这一互斥关系进一步扩展至计算材料宏观力学性能的多尺度物理模型中也依然适用,大多数长链条集成或宏观性能预测的物理模型具有强可解释性,但其数据拟合能力与准确度往往低于人工智能模型,这一观点已被诸多案例所证实[1,4,9]. ...
... (3) 数据驱动的大模型与小模型方向.目前人工智能技术的发展看似日新月异,但实质上越来越偏于一隅,绝大多数学者均集中在大模型领域.虽然也有吴恩达、崔鹏等知名学者一直呼吁对小模型的关注[7],但大模型的研究惯性与吸引力仍然非常强大.但合金设计不同于自然语言处理与自然图像识别,其数据获取成本注定其面临的问题多数具有小样本特点.因此,未来在合金设计领域,人工智能技术或许应适当弱化基于海量模拟数据样本开展的大模型研究,而更应侧重于基于小样本实验数据的可解释性小模型开发,例如本文在图像数据应用部分提到的基于小样本的多模态算法.而大模型的开发也应充分考虑材料学数据量限制,通过丰富样本信息与模态,调整模型构架,降低大模型对样本量的硬性需求度,开发基于小样本的图像生成算法,甚至小样本下的文本与图像数据联合分析算法等,上述算法均是在合金设计领域中有迫切需求的高潜力技术.更进一步来说,目前针对小样本数据的算法也是种类多样,每一个问题使用的算法构架或自定义的超参数均不同,这也会大大限制方法的迁移推广.因此更需要一个可普适性指导小样本算法构建或选择的理论体系,这样才能更贴近应用层面,为解决合金设计等更为现实的科学问题提供方法论指导.同时,基于AI4Sci的理念,普适性物理机制永远是指导科学决策的核心,其价值无法被数据驱动所取代,因此基于人工智能的强大数据分析能力,反向揭示物理机制或发现具有普适性价值的新物理方程描述也是非常值得关注的方向,该方向已有了诸多代表性的工作成果[33].同样,上述观点也仅是针对合金设计的需求而提出的可行发展方向,在具有更多数据的工业大数据分析领域,端对端的大模型开发依然具有长久的生命力与发展潜力. ...
Explainable machine learning in materials science
2
2022
... 首先,物理模型与人工智能间的关系,其本质可归结于上述提到的模型“准确性”与“可解释性”之间的冲突,这种冲突一直存在并被广泛认知.由于本文后续的大多数论述会围绕“准确性”与“可解释性”展开,所以首先需要对这2个名词在本文中的定义与量化评价方法加以明确.“准确性”是模拟计算中的标准名词,在本文中是指模型对合金设计中关注的目标性能的预测准确性,可通过对比模型预测值与实验测定的性能实际值来量化计算(例如拟和优度(R2)或平均绝对误差(MAE)).“可解释性”一般在人工智能领域是指模型与人们普适性认知的客观规律相吻合,因而其计算过程或结果具有可被常人理解的能力.其常见的外在表现形式是模型不但对已有的训练样本适用,更可普适性反映更多新样本的规律与通用机制,但其目前并没有公认的标准量化评价方法,本文主要使用“域外扩展能力”(out-of-distribution generalization)来量化评价模型的“可解释性”,即认为2者之间是互为充要条件的关系.这一观点也在人工智能的“稳定学习”研究[7]中被证明,即一个在物理机制上更合理的模型必然促使其域外扩展能力增强,同时,一个模型的域外扩展能力变强,则也可以反推出该模型一定是找到了与现实更加吻合的物理机制,2者在本质上是一个概念.值得注意的是,“稳定学习”作为一个近年来新发展的理论方法,其通用性还有待进一步考证.但由于“可解释性”本身是一个极难量化的抽象概念,因此在缺少其他更为合理、直观的量化方式前提下,本文选择使用模型的域外扩展能力作为“可解释性”的量化评判标准.关于模型“准确性”与“可解释性”之间的冲突,Zhong等[8]已提及了类似的问题:人工智能模型往往存在准确性与可解释性之间的互斥关系(图1a),例如绝大多数深度学习模型有极强的数据拟合能力,可表现出高准确性,但其是典型的“黑箱”模型,可解释性低;而决策树等具有可解释性的人工智能模型的数据拟合能力要远低于深度学习网络,即模型准确性上存在劣势.这一互斥关系进一步扩展至计算材料宏观力学性能的多尺度物理模型中也依然适用,大多数长链条集成或宏观性能预测的物理模型具有强可解释性,但其数据拟合能力与准确度往往低于人工智能模型,这一观点已被诸多案例所证实[1,4,9]. ...
... 实质上,可解释性机器学习(XAI)[8,25,26]本身就是人工智能领域中的一个重要研究分支,但是人工智能策略的基础思路就是基于数据的算法训练,将统计学理论作为人工智能的数学根基,其本身也是一个统计大量数据并进行综合分析的学科门类.因此,目前大多数可解释性机器学习算法的开发都是通过进一步扩展算法构架,以形成更接近人类复杂思考过程的计算策略,而算法构架扩展所带来的问题就是需要更大量的数据进行模型训练,甚至很多算法在开发伊始的基本假设就是在数据无限多的理想空间中应用,因此这些大模型的应用背景也自然更多面向交通、医疗、财政等大数据环境[26].例如目前被广为使用的Transformer构架[27],与传统循环神经网络(RNN)相比引入了更符合人类在理解文本内容时全局思考模式的自注意力机制,提升了模型性能,但其所需的训练数据量也相应提升了.然而在合金设计领域,面对大量长时服役或复杂工况的性能设计需求,往往高质量数据的获取极为困难[28].受到合金设计领域小样本困境的限制,目前尚很难见到人工智能领域可解释性机器学习大模型在此方面的成功应用.当然,人工智能领域也经常使用多种降维处理手段来实现小样本条件下的模型准确性提升,但这种处理方式同样是以牺牲物理可解释性为代价的.图2[29~32]量化对比了常见的多种降维处理方式对模型性能的提升作用.可以看到,主成分分析(principal components analysis,PCA)算法[29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
Discovery of marageing steels: Machine learning vs. physical metallurgical modelling
1
2021
... 首先,物理模型与人工智能间的关系,其本质可归结于上述提到的模型“准确性”与“可解释性”之间的冲突,这种冲突一直存在并被广泛认知.由于本文后续的大多数论述会围绕“准确性”与“可解释性”展开,所以首先需要对这2个名词在本文中的定义与量化评价方法加以明确.“准确性”是模拟计算中的标准名词,在本文中是指模型对合金设计中关注的目标性能的预测准确性,可通过对比模型预测值与实验测定的性能实际值来量化计算(例如拟和优度(R2)或平均绝对误差(MAE)).“可解释性”一般在人工智能领域是指模型与人们普适性认知的客观规律相吻合,因而其计算过程或结果具有可被常人理解的能力.其常见的外在表现形式是模型不但对已有的训练样本适用,更可普适性反映更多新样本的规律与通用机制,但其目前并没有公认的标准量化评价方法,本文主要使用“域外扩展能力”(out-of-distribution generalization)来量化评价模型的“可解释性”,即认为2者之间是互为充要条件的关系.这一观点也在人工智能的“稳定学习”研究[7]中被证明,即一个在物理机制上更合理的模型必然促使其域外扩展能力增强,同时,一个模型的域外扩展能力变强,则也可以反推出该模型一定是找到了与现实更加吻合的物理机制,2者在本质上是一个概念.值得注意的是,“稳定学习”作为一个近年来新发展的理论方法,其通用性还有待进一步考证.但由于“可解释性”本身是一个极难量化的抽象概念,因此在缺少其他更为合理、直观的量化方式前提下,本文选择使用模型的域外扩展能力作为“可解释性”的量化评判标准.关于模型“准确性”与“可解释性”之间的冲突,Zhong等[8]已提及了类似的问题:人工智能模型往往存在准确性与可解释性之间的互斥关系(图1a),例如绝大多数深度学习模型有极强的数据拟合能力,可表现出高准确性,但其是典型的“黑箱”模型,可解释性低;而决策树等具有可解释性的人工智能模型的数据拟合能力要远低于深度学习网络,即模型准确性上存在劣势.这一互斥关系进一步扩展至计算材料宏观力学性能的多尺度物理模型中也依然适用,大多数长链条集成或宏观性能预测的物理模型具有强可解释性,但其数据拟合能力与准确度往往低于人工智能模型,这一观点已被诸多案例所证实[1,4,9]. ...
Physical metallurgy-guided machine learning and artificial intelligent design of ultrahigh-strength stainless steel
8
2019
... 综上可知,合金设计实质上需要准确性与域外扩展能力2者兼得.因此,为了突破上述互斥关系问题,一个很自然的理念就逐步形成了:需要将物理模型与人工智能模型相结合,实现物理模型可解释性/域外扩展能力与人工智能模型准确性的优势互补,这就是近年来被广泛提及的物理冶金原理指导人工智能方法理念[10,11]. ...
... 物理冶金原理指导人工智能方法一词的正式提出始于2019年[10],彼时图像相关的人工智能算法尚未在合金设计领域受到广泛的关注,绝大多数工作仍集中于对纯数值型数据的分析.由于在基于材料基因理念的合金设计方面,热力学与相图一直起到至关重要的核心作用,因此最早的物理冶金原理指导人工智能方法案例也是使用热力学物理模型为核心,进行与人工智能算法的融合.基于上述原因,本小节的论述以热力学数值信息指导人工智能的案例为主体,并延伸至更多尺度下的物理数值信息层面. ...
... 在直接针对合金性能设计的研究方面,虽然很难找到像上述Ms预测一样系统性对比物理模型、人工智能及物理冶金原理指导人工智能方法的案例,但也有一些值得关注的结果从另一个角度证明了物理冶金原理指导人工智能方法的本质.Shen等[10]在超高强不锈钢体系下分别使用人工智能和物理冶金原理指导人工智能方法进行了针对硬度的单目标设计.该研究与Ms预测的案例相似,先基于不同钢种的成分信息,使用热力学模型计算了不同钢种中主要析出相的化学驱动力与平衡态相体积分数,然后将这些热力学机制数据与成分工艺信息一起作为输入特征训练SVM模型用以预测硬度,该热力学机制信息指导的SVM模型被命名为物理冶金原理指导的支持向量机(physical metallurgy-guided support vector machine,PM-SVM).而后,该工作通过对比PM-SVM与传统SVM算法(直接建立成分、工艺与硬度间的关系,不加入热力学机制信息),非常直观地展示了其在合金设计中的区别.首先,PM-SVM与传统SVM模型对已知数据的拟合能力没有任何差别,都达到90%以上,说明从准确性的角度来看,2个模型似乎都没有任何问题,可以应用于后续设计.但当将2个模型分别连接优化算法,进行新合金方案的发现时,2个模型的设计结果出现明显差别.传统SVM模型甚至可以提出硬度提升10 HRC的“超强”方案,但该方案的合理性却非常低,其提出的时效温度甚至低到300 ℃以下,根本不可能生成合理的强化型析出相,而实际的实验验证结果也证实该“超强”方案的实际硬度不但没有提升,反而比原有合金下降了接近20 HRC.而PM-SVM模型的设计方案则具有较高的合理性,虽然其预测的硬度提升效果并没有夸张式的增长,但其预测结果与最终的实验验证结果吻合良好,说明其可以切实地指导合金设计. ...
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
... [10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
... [
10,
46~
54]
Paradigm of thermodynamic mechanism information-guided artificial intelligence for alloy design<sup>[<xref ref-type="bibr" rid="R10">10</xref>,<xref ref-type="bibr" rid="R46">46</xref>-<xref ref-type="bibr" rid="R54">54</xref>]</sup> (ANN—artificial neural network)Fig.5![]() <strong>2.3</strong> 其他尺度数值数据指导人工智能的设计
<strong>2.3</strong> 其他尺度数值数据指导人工智能的设计与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
... [
10,
46-
54] (ANN—artificial neural network)
Fig.5![]() <strong>2.3</strong> 其他尺度数值数据指导人工智能的设计
<strong>2.3</strong> 其他尺度数值数据指导人工智能的设计与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
... 与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
Biomedical applications of the powder‐based 3D printed titanium alloys: A review
1
2022
... 综上可知,合金设计实质上需要准确性与域外扩展能力2者兼得.因此,为了突破上述互斥关系问题,一个很自然的理念就逐步形成了:需要将物理模型与人工智能模型相结合,实现物理模型可解释性/域外扩展能力与人工智能模型准确性的优势互补,这就是近年来被广泛提及的物理冶金原理指导人工智能方法理念[10,11]. ...
Trends in modeling, design, and optimization of multiphase systems in minerals processing
1
2020
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
A review of uncertainty quantification in medical image analysis: Probabilistic and non-probabilistic methods
1
2024
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
An autonomous laboratory for the accelerated synthesis of novel materials
1
2023
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
Accelerated search for materials with targeted properties by adaptive design
1
2016
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
Composition refinement of 6061 aluminum alloy using active machine learning model based on Bayesian optimization sampling
1
2021
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
基于Bayesian采样主动机器学习模型的6061铝合金成分精细优化
1
2021
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
A survey of uncertainty in deep neural networks
1
2023
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
Uncertainty estimation in medical image classification: Systematic review
1
2022
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
Hands-on Bayesian neural networks—A tutorial for deep learning users
1
2022
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
Reduced-order models for ranking damage initiation in dual-phase composites using Bayesian neural networks
1
2020
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
Development of constitutive models for extrapolative prediction of Nb-Ti micro alloyed steel
1
2017
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
Neighborhood spatial correlations and machine learning classification of fatigue hot-spots in Ti-6Al-4V
1
2023
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
Data-driven approach to characterize and optimize properties of carbon fiber non-woven composite materials
1
2022
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
Uncertainty quantification and propagation in lithium-ion battery electrodes using Bayesian convolutional neural networks
1
2024
... 首先,针对人工智能方法,以最为常见的人工神经网络为例,理论上其一个模型中包含的神经元数量可以进行无限制的扩充,神经元间可选择的组合模式也基本处于无限制的状态,这种高自由度的计算方式自然可以为其带来强大的数据拟合能力,从而保证其对已有数据的高吻合性,但其带来的弊端即是在域外扩展时面临的高度不确定性问题.如图1b所示,针对同一个数据集,完全不受方程形式约束的高自由度人工智能算法完全可以通过训练获得2个不一样的模型,如图1b中蓝色线和黄色线所示.2个模型均有很好的准确性,而且也均无明显的过拟合现象,但其域外扩展方向可以完全不同,这就是人工智能领域经典的认知不确定性问题[12,13].而针对此问题,人工智能领域相关学者也在持续地探索解决手段.例如:只需要在域外空间补充少量的数据点,这些数据点本身就可以成为模型扩展方向的判别性约束,无法与补充数据吻合的模型自然代表其不具备域外扩展能力,从而被摒弃.这种思想就是被大量应用于功能及化学材料设计中的主动学习算法[14,15].该方法目前在合金设计中也有成功案例[16],但针对合金设计,通过补充数据提升模型域外扩展能力的方法也有一定的风险性,其成功与否取决于2个核心因素:(1) 补充的数据本身是否准确;(2) 新数据所在空间位置是否具有足够代表性.针对疲劳、蠕变等本身就有较大实验误差的性能来说,每补充一个准确的数据点都是一个费时、费力的工程.而对于大多数多组元合金设计来说,需补充的数据点是否具有代表性往往也很难抉择.而针对此问题,主动学习算法中也常使用不确定性估计算法[17,18]来进行数据补充方向的合理决策,最具代表性的材料学应用范例是Bayesian不确定性计算方法[19].该方法已在钢铁材料[20,21]、钛合金[22]、复合材料[23]、锂电池[24]等多种材料体系中得到广泛应用.当然,不确定性算法也可以脱离主动学习框架,在合金设计过程中成为独立的数据处理方式,受篇幅所限本文未做介绍.但无论是主动学习还是不确定性估算方法,都属于一种相对冗长的先发现问题再解决问题的循环迭代流程,其通过评估模型的外推能力,施行“亡羊补牢”式的逐步改进处理,一旦这种补救的循环次数过多,依然会导致时间及资金成本问题.因此,更一劳永逸的思路是尝试直接开发本身就具有可解释性的机器学习模型,其自然就会具有良好的域外扩展能力. ...
Explainable Artificial Intelligence (XAI): What we know and what is left to attain Trustworthy Artificial Intelligence
1
2023
... 实质上,可解释性机器学习(XAI)[8,25,26]本身就是人工智能领域中的一个重要研究分支,但是人工智能策略的基础思路就是基于数据的算法训练,将统计学理论作为人工智能的数学根基,其本身也是一个统计大量数据并进行综合分析的学科门类.因此,目前大多数可解释性机器学习算法的开发都是通过进一步扩展算法构架,以形成更接近人类复杂思考过程的计算策略,而算法构架扩展所带来的问题就是需要更大量的数据进行模型训练,甚至很多算法在开发伊始的基本假设就是在数据无限多的理想空间中应用,因此这些大模型的应用背景也自然更多面向交通、医疗、财政等大数据环境[26].例如目前被广为使用的Transformer构架[27],与传统循环神经网络(RNN)相比引入了更符合人类在理解文本内容时全局思考模式的自注意力机制,提升了模型性能,但其所需的训练数据量也相应提升了.然而在合金设计领域,面对大量长时服役或复杂工况的性能设计需求,往往高质量数据的获取极为困难[28].受到合金设计领域小样本困境的限制,目前尚很难见到人工智能领域可解释性机器学习大模型在此方面的成功应用.当然,人工智能领域也经常使用多种降维处理手段来实现小样本条件下的模型准确性提升,但这种处理方式同样是以牺牲物理可解释性为代价的.图2[29~32]量化对比了常见的多种降维处理方式对模型性能的提升作用.可以看到,主成分分析(principal components analysis,PCA)算法[29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
Interpreting black-box models: A review on explainable artificial intelligence
2
2024
... 实质上,可解释性机器学习(XAI)[8,25,26]本身就是人工智能领域中的一个重要研究分支,但是人工智能策略的基础思路就是基于数据的算法训练,将统计学理论作为人工智能的数学根基,其本身也是一个统计大量数据并进行综合分析的学科门类.因此,目前大多数可解释性机器学习算法的开发都是通过进一步扩展算法构架,以形成更接近人类复杂思考过程的计算策略,而算法构架扩展所带来的问题就是需要更大量的数据进行模型训练,甚至很多算法在开发伊始的基本假设就是在数据无限多的理想空间中应用,因此这些大模型的应用背景也自然更多面向交通、医疗、财政等大数据环境[26].例如目前被广为使用的Transformer构架[27],与传统循环神经网络(RNN)相比引入了更符合人类在理解文本内容时全局思考模式的自注意力机制,提升了模型性能,但其所需的训练数据量也相应提升了.然而在合金设计领域,面对大量长时服役或复杂工况的性能设计需求,往往高质量数据的获取极为困难[28].受到合金设计领域小样本困境的限制,目前尚很难见到人工智能领域可解释性机器学习大模型在此方面的成功应用.当然,人工智能领域也经常使用多种降维处理手段来实现小样本条件下的模型准确性提升,但这种处理方式同样是以牺牲物理可解释性为代价的.图2[29~32]量化对比了常见的多种降维处理方式对模型性能的提升作用.可以看到,主成分分析(principal components analysis,PCA)算法[29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
... [26].例如目前被广为使用的Transformer构架[27],与传统循环神经网络(RNN)相比引入了更符合人类在理解文本内容时全局思考模式的自注意力机制,提升了模型性能,但其所需的训练数据量也相应提升了.然而在合金设计领域,面对大量长时服役或复杂工况的性能设计需求,往往高质量数据的获取极为困难[28].受到合金设计领域小样本困境的限制,目前尚很难见到人工智能领域可解释性机器学习大模型在此方面的成功应用.当然,人工智能领域也经常使用多种降维处理手段来实现小样本条件下的模型准确性提升,但这种处理方式同样是以牺牲物理可解释性为代价的.图2[29~32]量化对比了常见的多种降维处理方式对模型性能的提升作用.可以看到,主成分分析(principal components analysis,PCA)算法[29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
Attention is all you need
1
2017
... 实质上,可解释性机器学习(XAI)[8,25,26]本身就是人工智能领域中的一个重要研究分支,但是人工智能策略的基础思路就是基于数据的算法训练,将统计学理论作为人工智能的数学根基,其本身也是一个统计大量数据并进行综合分析的学科门类.因此,目前大多数可解释性机器学习算法的开发都是通过进一步扩展算法构架,以形成更接近人类复杂思考过程的计算策略,而算法构架扩展所带来的问题就是需要更大量的数据进行模型训练,甚至很多算法在开发伊始的基本假设就是在数据无限多的理想空间中应用,因此这些大模型的应用背景也自然更多面向交通、医疗、财政等大数据环境[26].例如目前被广为使用的Transformer构架[27],与传统循环神经网络(RNN)相比引入了更符合人类在理解文本内容时全局思考模式的自注意力机制,提升了模型性能,但其所需的训练数据量也相应提升了.然而在合金设计领域,面对大量长时服役或复杂工况的性能设计需求,往往高质量数据的获取极为困难[28].受到合金设计领域小样本困境的限制,目前尚很难见到人工智能领域可解释性机器学习大模型在此方面的成功应用.当然,人工智能领域也经常使用多种降维处理手段来实现小样本条件下的模型准确性提升,但这种处理方式同样是以牺牲物理可解释性为代价的.图2[29~32]量化对比了常见的多种降维处理方式对模型性能的提升作用.可以看到,主成分分析(principal components analysis,PCA)算法[29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
Small data machine learning in materials science
1
2023
... 实质上,可解释性机器学习(XAI)[8,25,26]本身就是人工智能领域中的一个重要研究分支,但是人工智能策略的基础思路就是基于数据的算法训练,将统计学理论作为人工智能的数学根基,其本身也是一个统计大量数据并进行综合分析的学科门类.因此,目前大多数可解释性机器学习算法的开发都是通过进一步扩展算法构架,以形成更接近人类复杂思考过程的计算策略,而算法构架扩展所带来的问题就是需要更大量的数据进行模型训练,甚至很多算法在开发伊始的基本假设就是在数据无限多的理想空间中应用,因此这些大模型的应用背景也自然更多面向交通、医疗、财政等大数据环境[26].例如目前被广为使用的Transformer构架[27],与传统循环神经网络(RNN)相比引入了更符合人类在理解文本内容时全局思考模式的自注意力机制,提升了模型性能,但其所需的训练数据量也相应提升了.然而在合金设计领域,面对大量长时服役或复杂工况的性能设计需求,往往高质量数据的获取极为困难[28].受到合金设计领域小样本困境的限制,目前尚很难见到人工智能领域可解释性机器学习大模型在此方面的成功应用.当然,人工智能领域也经常使用多种降维处理手段来实现小样本条件下的模型准确性提升,但这种处理方式同样是以牺牲物理可解释性为代价的.图2[29~32]量化对比了常见的多种降维处理方式对模型性能的提升作用.可以看到,主成分分析(principal components analysis,PCA)算法[29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
Improving accuracy of intrusion detection model using PCA and optimized SVM
4
2016
... 实质上,可解释性机器学习(XAI)[8,25,26]本身就是人工智能领域中的一个重要研究分支,但是人工智能策略的基础思路就是基于数据的算法训练,将统计学理论作为人工智能的数学根基,其本身也是一个统计大量数据并进行综合分析的学科门类.因此,目前大多数可解释性机器学习算法的开发都是通过进一步扩展算法构架,以形成更接近人类复杂思考过程的计算策略,而算法构架扩展所带来的问题就是需要更大量的数据进行模型训练,甚至很多算法在开发伊始的基本假设就是在数据无限多的理想空间中应用,因此这些大模型的应用背景也自然更多面向交通、医疗、财政等大数据环境[26].例如目前被广为使用的Transformer构架[27],与传统循环神经网络(RNN)相比引入了更符合人类在理解文本内容时全局思考模式的自注意力机制,提升了模型性能,但其所需的训练数据量也相应提升了.然而在合金设计领域,面对大量长时服役或复杂工况的性能设计需求,往往高质量数据的获取极为困难[28].受到合金设计领域小样本困境的限制,目前尚很难见到人工智能领域可解释性机器学习大模型在此方面的成功应用.当然,人工智能领域也经常使用多种降维处理手段来实现小样本条件下的模型准确性提升,但这种处理方式同样是以牺牲物理可解释性为代价的.图2[29~32]量化对比了常见的多种降维处理方式对模型性能的提升作用.可以看到,主成分分析(principal components analysis,PCA)算法[29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
... [29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
... [
29~
32]
Quantitative effect of dimensionality reduction methods on model accuracy<sup>[<xref ref-type="bibr" rid="R29">29</xref>-<xref ref-type="bibr" rid="R32">32</xref>]</sup> (PCA—principal components analysis, KPCA—kernel based principal component analysis, t-SNE—t-distributed stochastic neighbor embedding, ISOMAP—Isometric Mapping)Fig.2![]()
物理模型(本文中的物理模型不涉及人工智能概念,其与材料学领域普遍认知的物理模型定义一致,是指基于物理机制的数学公式模型)则与人工智能模型截然相反,其数学理论基础是具有更强固定性的微积分学,如图1c所示,由于各物理场适用的偏微分方程组直接固定了计算的确切方程形式,因此物理模型一般会具有非常稳定的域外扩展能力,不会遇到人工智能算法所涉及的域外不确定性问题.但这种低自由度的算法稳定有余、变通不足,一旦其面对一些细小的机制变化问题,偏离了其预定理想的方程形式,物理模型就会出现明显的准确性问题.例如图1c中蓝色线所代表的模型为典型的ln型方程形式,当黄色箭头所标注的数据点明显偏离ln型曲线的行进路径时,则该模型无法与之吻合.因此,大多数物理模型,尤其是与力学性能预测相关的本构模型(例如Hall-Petch公式[33,34]),在合金设计过程中往往只能给予半定量甚至定性化的指导[35,36].然而从纯数学的角度看,突破准确性问题比解决域外扩展问题要相对简单,因为只要赋予模型更高的拟合自由度,则自然可以提升对已知数据的吻合性.而物理模型领域常用的提高模型自由度的方法就是“模型修正”,这一类型的工作不胜枚举[34,35],但问题是多数“模型修正”类工作往往只依据一个独立研究体系中的少量数据,研究者很少会对这种优化是否适用于其他体系进行广泛验证,因此这种修正并不是为模型引入了一个普适性的通用机制,而是为了提升模型对已知数据的吻合性,加入了一个不具备普适性扩展价值的拟合项.这其实与人工智能方法中不包含物理机制的纯数据拟合没有本质的区别,甚至相比之下人工智能方法可能更具价值,因为毕竟人工智能拟合得到的模型是基于更大量数据的.而更可怕的是,现今合金材料的内部机制越来越复杂,针对一个复杂性能,尤其是宏观力学性能的预测,往往会使用链式串联结构的多尺度物理模型[35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
... [
29-
32] (PCA—principal components analysis, KPCA—kernel based principal component analysis, t-SNE—t-distributed stochastic neighbor embedding, ISOMAP—Isometric Mapping)
Fig.2![]()
物理模型(本文中的物理模型不涉及人工智能概念,其与材料学领域普遍认知的物理模型定义一致,是指基于物理机制的数学公式模型)则与人工智能模型截然相反,其数学理论基础是具有更强固定性的微积分学,如图1c所示,由于各物理场适用的偏微分方程组直接固定了计算的确切方程形式,因此物理模型一般会具有非常稳定的域外扩展能力,不会遇到人工智能算法所涉及的域外不确定性问题.但这种低自由度的算法稳定有余、变通不足,一旦其面对一些细小的机制变化问题,偏离了其预定理想的方程形式,物理模型就会出现明显的准确性问题.例如图1c中蓝色线所代表的模型为典型的ln型方程形式,当黄色箭头所标注的数据点明显偏离ln型曲线的行进路径时,则该模型无法与之吻合.因此,大多数物理模型,尤其是与力学性能预测相关的本构模型(例如Hall-Petch公式[33,34]),在合金设计过程中往往只能给予半定量甚至定性化的指导[35,36].然而从纯数学的角度看,突破准确性问题比解决域外扩展问题要相对简单,因为只要赋予模型更高的拟合自由度,则自然可以提升对已知数据的吻合性.而物理模型领域常用的提高模型自由度的方法就是“模型修正”,这一类型的工作不胜枚举[34,35],但问题是多数“模型修正”类工作往往只依据一个独立研究体系中的少量数据,研究者很少会对这种优化是否适用于其他体系进行广泛验证,因此这种修正并不是为模型引入了一个普适性的通用机制,而是为了提升模型对已知数据的吻合性,加入了一个不具备普适性扩展价值的拟合项.这其实与人工智能方法中不包含物理机制的纯数据拟合没有本质的区别,甚至相比之下人工智能方法可能更具价值,因为毕竟人工智能拟合得到的模型是基于更大量数据的.而更可怕的是,现今合金材料的内部机制越来越复杂,针对一个复杂性能,尤其是宏观力学性能的预测,往往会使用链式串联结构的多尺度物理模型[35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
Prediction model of end-point phosphorus content in BOF steelmaking process based on PCA and BP neural network
2
2018
... 实质上,可解释性机器学习(XAI)[8,25,26]本身就是人工智能领域中的一个重要研究分支,但是人工智能策略的基础思路就是基于数据的算法训练,将统计学理论作为人工智能的数学根基,其本身也是一个统计大量数据并进行综合分析的学科门类.因此,目前大多数可解释性机器学习算法的开发都是通过进一步扩展算法构架,以形成更接近人类复杂思考过程的计算策略,而算法构架扩展所带来的问题就是需要更大量的数据进行模型训练,甚至很多算法在开发伊始的基本假设就是在数据无限多的理想空间中应用,因此这些大模型的应用背景也自然更多面向交通、医疗、财政等大数据环境[26].例如目前被广为使用的Transformer构架[27],与传统循环神经网络(RNN)相比引入了更符合人类在理解文本内容时全局思考模式的自注意力机制,提升了模型性能,但其所需的训练数据量也相应提升了.然而在合金设计领域,面对大量长时服役或复杂工况的性能设计需求,往往高质量数据的获取极为困难[28].受到合金设计领域小样本困境的限制,目前尚很难见到人工智能领域可解释性机器学习大模型在此方面的成功应用.当然,人工智能领域也经常使用多种降维处理手段来实现小样本条件下的模型准确性提升,但这种处理方式同样是以牺牲物理可解释性为代价的.图2[29~32]量化对比了常见的多种降维处理方式对模型性能的提升作用.可以看到,主成分分析(principal components analysis,PCA)算法[29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
... [30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
Classification and identification of unknown network protocols based on CNN and T-SNE
1
2020
... 实质上,可解释性机器学习(XAI)[8,25,26]本身就是人工智能领域中的一个重要研究分支,但是人工智能策略的基础思路就是基于数据的算法训练,将统计学理论作为人工智能的数学根基,其本身也是一个统计大量数据并进行综合分析的学科门类.因此,目前大多数可解释性机器学习算法的开发都是通过进一步扩展算法构架,以形成更接近人类复杂思考过程的计算策略,而算法构架扩展所带来的问题就是需要更大量的数据进行模型训练,甚至很多算法在开发伊始的基本假设就是在数据无限多的理想空间中应用,因此这些大模型的应用背景也自然更多面向交通、医疗、财政等大数据环境[26].例如目前被广为使用的Transformer构架[27],与传统循环神经网络(RNN)相比引入了更符合人类在理解文本内容时全局思考模式的自注意力机制,提升了模型性能,但其所需的训练数据量也相应提升了.然而在合金设计领域,面对大量长时服役或复杂工况的性能设计需求,往往高质量数据的获取极为困难[28].受到合金设计领域小样本困境的限制,目前尚很难见到人工智能领域可解释性机器学习大模型在此方面的成功应用.当然,人工智能领域也经常使用多种降维处理手段来实现小样本条件下的模型准确性提升,但这种处理方式同样是以牺牲物理可解释性为代价的.图2[29~32]量化对比了常见的多种降维处理方式对模型性能的提升作用.可以看到,主成分分析(principal components analysis,PCA)算法[29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
ISOMAP and machine learning algorithms for the construction of embedded functional connectivity networks of anatomically separated brain regions from resting state fMRI data of patients with Schizophrenia
4
2021
... 实质上,可解释性机器学习(XAI)[8,25,26]本身就是人工智能领域中的一个重要研究分支,但是人工智能策略的基础思路就是基于数据的算法训练,将统计学理论作为人工智能的数学根基,其本身也是一个统计大量数据并进行综合分析的学科门类.因此,目前大多数可解释性机器学习算法的开发都是通过进一步扩展算法构架,以形成更接近人类复杂思考过程的计算策略,而算法构架扩展所带来的问题就是需要更大量的数据进行模型训练,甚至很多算法在开发伊始的基本假设就是在数据无限多的理想空间中应用,因此这些大模型的应用背景也自然更多面向交通、医疗、财政等大数据环境[26].例如目前被广为使用的Transformer构架[27],与传统循环神经网络(RNN)相比引入了更符合人类在理解文本内容时全局思考模式的自注意力机制,提升了模型性能,但其所需的训练数据量也相应提升了.然而在合金设计领域,面对大量长时服役或复杂工况的性能设计需求,往往高质量数据的获取极为困难[28].受到合金设计领域小样本困境的限制,目前尚很难见到人工智能领域可解释性机器学习大模型在此方面的成功应用.当然,人工智能领域也经常使用多种降维处理手段来实现小样本条件下的模型准确性提升,但这种处理方式同样是以牺牲物理可解释性为代价的.图2[29~32]量化对比了常见的多种降维处理方式对模型性能的提升作用.可以看到,主成分分析(principal components analysis,PCA)算法[29,30]作为最为常用的降维处理方式,可以使模型预测精度得到显著提升,提升效果可接近20%[30].同样,其他降维处理方式(例如t-随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[31]、等距映射(Isometric Mapping,ISOMAP)[32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
... [32]等)也可使模型得到不同程度的精度提升,但获得的新特征均为原始特征经过数学处理后的无物理意义特征,会不同程度降低模型的可解释性与域外扩展能力.综上,前述内容充分论述了人工智能算法因其高自由度属性而带来的域外扩展问题,而该问题又受到合金设计领域小样本特点的进一步限制,很难在统计数学自身的理论框架内寻求突破. ...
... ~
32]
Quantitative effect of dimensionality reduction methods on model accuracy<sup>[<xref ref-type="bibr" rid="R29">29</xref>-<xref ref-type="bibr" rid="R32">32</xref>]</sup> (PCA—principal components analysis, KPCA—kernel based principal component analysis, t-SNE—t-distributed stochastic neighbor embedding, ISOMAP—Isometric Mapping)Fig.2![]()
物理模型(本文中的物理模型不涉及人工智能概念,其与材料学领域普遍认知的物理模型定义一致,是指基于物理机制的数学公式模型)则与人工智能模型截然相反,其数学理论基础是具有更强固定性的微积分学,如图1c所示,由于各物理场适用的偏微分方程组直接固定了计算的确切方程形式,因此物理模型一般会具有非常稳定的域外扩展能力,不会遇到人工智能算法所涉及的域外不确定性问题.但这种低自由度的算法稳定有余、变通不足,一旦其面对一些细小的机制变化问题,偏离了其预定理想的方程形式,物理模型就会出现明显的准确性问题.例如图1c中蓝色线所代表的模型为典型的ln型方程形式,当黄色箭头所标注的数据点明显偏离ln型曲线的行进路径时,则该模型无法与之吻合.因此,大多数物理模型,尤其是与力学性能预测相关的本构模型(例如Hall-Petch公式[33,34]),在合金设计过程中往往只能给予半定量甚至定性化的指导[35,36].然而从纯数学的角度看,突破准确性问题比解决域外扩展问题要相对简单,因为只要赋予模型更高的拟合自由度,则自然可以提升对已知数据的吻合性.而物理模型领域常用的提高模型自由度的方法就是“模型修正”,这一类型的工作不胜枚举[34,35],但问题是多数“模型修正”类工作往往只依据一个独立研究体系中的少量数据,研究者很少会对这种优化是否适用于其他体系进行广泛验证,因此这种修正并不是为模型引入了一个普适性的通用机制,而是为了提升模型对已知数据的吻合性,加入了一个不具备普适性扩展价值的拟合项.这其实与人工智能方法中不包含物理机制的纯数据拟合没有本质的区别,甚至相比之下人工智能方法可能更具价值,因为毕竟人工智能拟合得到的模型是基于更大量数据的.而更可怕的是,现今合金材料的内部机制越来越复杂,针对一个复杂性能,尤其是宏观力学性能的预测,往往会使用链式串联结构的多尺度物理模型[35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
... -
32] (PCA—principal components analysis, KPCA—kernel based principal component analysis, t-SNE—t-distributed stochastic neighbor embedding, ISOMAP—Isometric Mapping)
Fig.2![]()
物理模型(本文中的物理模型不涉及人工智能概念,其与材料学领域普遍认知的物理模型定义一致,是指基于物理机制的数学公式模型)则与人工智能模型截然相反,其数学理论基础是具有更强固定性的微积分学,如图1c所示,由于各物理场适用的偏微分方程组直接固定了计算的确切方程形式,因此物理模型一般会具有非常稳定的域外扩展能力,不会遇到人工智能算法所涉及的域外不确定性问题.但这种低自由度的算法稳定有余、变通不足,一旦其面对一些细小的机制变化问题,偏离了其预定理想的方程形式,物理模型就会出现明显的准确性问题.例如图1c中蓝色线所代表的模型为典型的ln型方程形式,当黄色箭头所标注的数据点明显偏离ln型曲线的行进路径时,则该模型无法与之吻合.因此,大多数物理模型,尤其是与力学性能预测相关的本构模型(例如Hall-Petch公式[33,34]),在合金设计过程中往往只能给予半定量甚至定性化的指导[35,36].然而从纯数学的角度看,突破准确性问题比解决域外扩展问题要相对简单,因为只要赋予模型更高的拟合自由度,则自然可以提升对已知数据的吻合性.而物理模型领域常用的提高模型自由度的方法就是“模型修正”,这一类型的工作不胜枚举[34,35],但问题是多数“模型修正”类工作往往只依据一个独立研究体系中的少量数据,研究者很少会对这种优化是否适用于其他体系进行广泛验证,因此这种修正并不是为模型引入了一个普适性的通用机制,而是为了提升模型对已知数据的吻合性,加入了一个不具备普适性扩展价值的拟合项.这其实与人工智能方法中不包含物理机制的纯数据拟合没有本质的区别,甚至相比之下人工智能方法可能更具价值,因为毕竟人工智能拟合得到的模型是基于更大量数据的.而更可怕的是,现今合金材料的内部机制越来越复杂,针对一个复杂性能,尤其是宏观力学性能的预测,往往会使用链式串联结构的多尺度物理模型[35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
Physical mechanism interpretation of polycrystalline metals' yield strength via a data-driven method: A novel Hall-Petch relationship
2
2022
... 物理模型(本文中的物理模型不涉及人工智能概念,其与材料学领域普遍认知的物理模型定义一致,是指基于物理机制的数学公式模型)则与人工智能模型截然相反,其数学理论基础是具有更强固定性的微积分学,如图1c所示,由于各物理场适用的偏微分方程组直接固定了计算的确切方程形式,因此物理模型一般会具有非常稳定的域外扩展能力,不会遇到人工智能算法所涉及的域外不确定性问题.但这种低自由度的算法稳定有余、变通不足,一旦其面对一些细小的机制变化问题,偏离了其预定理想的方程形式,物理模型就会出现明显的准确性问题.例如图1c中蓝色线所代表的模型为典型的ln型方程形式,当黄色箭头所标注的数据点明显偏离ln型曲线的行进路径时,则该模型无法与之吻合.因此,大多数物理模型,尤其是与力学性能预测相关的本构模型(例如Hall-Petch公式[33,34]),在合金设计过程中往往只能给予半定量甚至定性化的指导[35,36].然而从纯数学的角度看,突破准确性问题比解决域外扩展问题要相对简单,因为只要赋予模型更高的拟合自由度,则自然可以提升对已知数据的吻合性.而物理模型领域常用的提高模型自由度的方法就是“模型修正”,这一类型的工作不胜枚举[34,35],但问题是多数“模型修正”类工作往往只依据一个独立研究体系中的少量数据,研究者很少会对这种优化是否适用于其他体系进行广泛验证,因此这种修正并不是为模型引入了一个普适性的通用机制,而是为了提升模型对已知数据的吻合性,加入了一个不具备普适性扩展价值的拟合项.这其实与人工智能方法中不包含物理机制的纯数据拟合没有本质的区别,甚至相比之下人工智能方法可能更具价值,因为毕竟人工智能拟合得到的模型是基于更大量数据的.而更可怕的是,现今合金材料的内部机制越来越复杂,针对一个复杂性能,尤其是宏观力学性能的预测,往往会使用链式串联结构的多尺度物理模型[35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
... (3) 数据驱动的大模型与小模型方向.目前人工智能技术的发展看似日新月异,但实质上越来越偏于一隅,绝大多数学者均集中在大模型领域.虽然也有吴恩达、崔鹏等知名学者一直呼吁对小模型的关注[7],但大模型的研究惯性与吸引力仍然非常强大.但合金设计不同于自然语言处理与自然图像识别,其数据获取成本注定其面临的问题多数具有小样本特点.因此,未来在合金设计领域,人工智能技术或许应适当弱化基于海量模拟数据样本开展的大模型研究,而更应侧重于基于小样本实验数据的可解释性小模型开发,例如本文在图像数据应用部分提到的基于小样本的多模态算法.而大模型的开发也应充分考虑材料学数据量限制,通过丰富样本信息与模态,调整模型构架,降低大模型对样本量的硬性需求度,开发基于小样本的图像生成算法,甚至小样本下的文本与图像数据联合分析算法等,上述算法均是在合金设计领域中有迫切需求的高潜力技术.更进一步来说,目前针对小样本数据的算法也是种类多样,每一个问题使用的算法构架或自定义的超参数均不同,这也会大大限制方法的迁移推广.因此更需要一个可普适性指导小样本算法构建或选择的理论体系,这样才能更贴近应用层面,为解决合金设计等更为现实的科学问题提供方法论指导.同时,基于AI4Sci的理念,普适性物理机制永远是指导科学决策的核心,其价值无法被数据驱动所取代,因此基于人工智能的强大数据分析能力,反向揭示物理机制或发现具有普适性价值的新物理方程描述也是非常值得关注的方向,该方向已有了诸多代表性的工作成果[33].同样,上述观点也仅是针对合金设计的需求而提出的可行发展方向,在具有更多数据的工业大数据分析领域,端对端的大模型开发依然具有长久的生命力与发展潜力. ...
The status role of modeling and simulation in materials science and engineering
2
1999
... 物理模型(本文中的物理模型不涉及人工智能概念,其与材料学领域普遍认知的物理模型定义一致,是指基于物理机制的数学公式模型)则与人工智能模型截然相反,其数学理论基础是具有更强固定性的微积分学,如图1c所示,由于各物理场适用的偏微分方程组直接固定了计算的确切方程形式,因此物理模型一般会具有非常稳定的域外扩展能力,不会遇到人工智能算法所涉及的域外不确定性问题.但这种低自由度的算法稳定有余、变通不足,一旦其面对一些细小的机制变化问题,偏离了其预定理想的方程形式,物理模型就会出现明显的准确性问题.例如图1c中蓝色线所代表的模型为典型的ln型方程形式,当黄色箭头所标注的数据点明显偏离ln型曲线的行进路径时,则该模型无法与之吻合.因此,大多数物理模型,尤其是与力学性能预测相关的本构模型(例如Hall-Petch公式[33,34]),在合金设计过程中往往只能给予半定量甚至定性化的指导[35,36].然而从纯数学的角度看,突破准确性问题比解决域外扩展问题要相对简单,因为只要赋予模型更高的拟合自由度,则自然可以提升对已知数据的吻合性.而物理模型领域常用的提高模型自由度的方法就是“模型修正”,这一类型的工作不胜枚举[34,35],但问题是多数“模型修正”类工作往往只依据一个独立研究体系中的少量数据,研究者很少会对这种优化是否适用于其他体系进行广泛验证,因此这种修正并不是为模型引入了一个普适性的通用机制,而是为了提升模型对已知数据的吻合性,加入了一个不具备普适性扩展价值的拟合项.这其实与人工智能方法中不包含物理机制的纯数据拟合没有本质的区别,甚至相比之下人工智能方法可能更具价值,因为毕竟人工智能拟合得到的模型是基于更大量数据的.而更可怕的是,现今合金材料的内部机制越来越复杂,针对一个复杂性能,尤其是宏观力学性能的预测,往往会使用链式串联结构的多尺度物理模型[35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
... [34,35],但问题是多数“模型修正”类工作往往只依据一个独立研究体系中的少量数据,研究者很少会对这种优化是否适用于其他体系进行广泛验证,因此这种修正并不是为模型引入了一个普适性的通用机制,而是为了提升模型对已知数据的吻合性,加入了一个不具备普适性扩展价值的拟合项.这其实与人工智能方法中不包含物理机制的纯数据拟合没有本质的区别,甚至相比之下人工智能方法可能更具价值,因为毕竟人工智能拟合得到的模型是基于更大量数据的.而更可怕的是,现今合金材料的内部机制越来越复杂,针对一个复杂性能,尤其是宏观力学性能的预测,往往会使用链式串联结构的多尺度物理模型[35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
Novel approaches to multiscale modelling in materials science
3
2011
... 物理模型(本文中的物理模型不涉及人工智能概念,其与材料学领域普遍认知的物理模型定义一致,是指基于物理机制的数学公式模型)则与人工智能模型截然相反,其数学理论基础是具有更强固定性的微积分学,如图1c所示,由于各物理场适用的偏微分方程组直接固定了计算的确切方程形式,因此物理模型一般会具有非常稳定的域外扩展能力,不会遇到人工智能算法所涉及的域外不确定性问题.但这种低自由度的算法稳定有余、变通不足,一旦其面对一些细小的机制变化问题,偏离了其预定理想的方程形式,物理模型就会出现明显的准确性问题.例如图1c中蓝色线所代表的模型为典型的ln型方程形式,当黄色箭头所标注的数据点明显偏离ln型曲线的行进路径时,则该模型无法与之吻合.因此,大多数物理模型,尤其是与力学性能预测相关的本构模型(例如Hall-Petch公式[33,34]),在合金设计过程中往往只能给予半定量甚至定性化的指导[35,36].然而从纯数学的角度看,突破准确性问题比解决域外扩展问题要相对简单,因为只要赋予模型更高的拟合自由度,则自然可以提升对已知数据的吻合性.而物理模型领域常用的提高模型自由度的方法就是“模型修正”,这一类型的工作不胜枚举[34,35],但问题是多数“模型修正”类工作往往只依据一个独立研究体系中的少量数据,研究者很少会对这种优化是否适用于其他体系进行广泛验证,因此这种修正并不是为模型引入了一个普适性的通用机制,而是为了提升模型对已知数据的吻合性,加入了一个不具备普适性扩展价值的拟合项.这其实与人工智能方法中不包含物理机制的纯数据拟合没有本质的区别,甚至相比之下人工智能方法可能更具价值,因为毕竟人工智能拟合得到的模型是基于更大量数据的.而更可怕的是,现今合金材料的内部机制越来越复杂,针对一个复杂性能,尤其是宏观力学性能的预测,往往会使用链式串联结构的多尺度物理模型[35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
... ,35],但问题是多数“模型修正”类工作往往只依据一个独立研究体系中的少量数据,研究者很少会对这种优化是否适用于其他体系进行广泛验证,因此这种修正并不是为模型引入了一个普适性的通用机制,而是为了提升模型对已知数据的吻合性,加入了一个不具备普适性扩展价值的拟合项.这其实与人工智能方法中不包含物理机制的纯数据拟合没有本质的区别,甚至相比之下人工智能方法可能更具价值,因为毕竟人工智能拟合得到的模型是基于更大量数据的.而更可怕的是,现今合金材料的内部机制越来越复杂,针对一个复杂性能,尤其是宏观力学性能的预测,往往会使用链式串联结构的多尺度物理模型[35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
... [35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
On different facets of regularization theory
2
2002
... 物理模型(本文中的物理模型不涉及人工智能概念,其与材料学领域普遍认知的物理模型定义一致,是指基于物理机制的数学公式模型)则与人工智能模型截然相反,其数学理论基础是具有更强固定性的微积分学,如图1c所示,由于各物理场适用的偏微分方程组直接固定了计算的确切方程形式,因此物理模型一般会具有非常稳定的域外扩展能力,不会遇到人工智能算法所涉及的域外不确定性问题.但这种低自由度的算法稳定有余、变通不足,一旦其面对一些细小的机制变化问题,偏离了其预定理想的方程形式,物理模型就会出现明显的准确性问题.例如图1c中蓝色线所代表的模型为典型的ln型方程形式,当黄色箭头所标注的数据点明显偏离ln型曲线的行进路径时,则该模型无法与之吻合.因此,大多数物理模型,尤其是与力学性能预测相关的本构模型(例如Hall-Petch公式[33,34]),在合金设计过程中往往只能给予半定量甚至定性化的指导[35,36].然而从纯数学的角度看,突破准确性问题比解决域外扩展问题要相对简单,因为只要赋予模型更高的拟合自由度,则自然可以提升对已知数据的吻合性.而物理模型领域常用的提高模型自由度的方法就是“模型修正”,这一类型的工作不胜枚举[34,35],但问题是多数“模型修正”类工作往往只依据一个独立研究体系中的少量数据,研究者很少会对这种优化是否适用于其他体系进行广泛验证,因此这种修正并不是为模型引入了一个普适性的通用机制,而是为了提升模型对已知数据的吻合性,加入了一个不具备普适性扩展价值的拟合项.这其实与人工智能方法中不包含物理机制的纯数据拟合没有本质的区别,甚至相比之下人工智能方法可能更具价值,因为毕竟人工智能拟合得到的模型是基于更大量数据的.而更可怕的是,现今合金材料的内部机制越来越复杂,针对一个复杂性能,尤其是宏观力学性能的预测,往往会使用链式串联结构的多尺度物理模型[35].可以想象,多个上述经过修正的物理模型串联到一起后,各模型的域外扩展误差逐层累积,其会对模型最终的域外扩展能力造成灾难性的削弱,导致其根本无法应用于实际合金设计.基于上述限制,目前绝大多数集成式物理模型实际上只是“局部多尺度”模型,而并不能贯通成为真正意义上的“全局跨尺度”模型.由此可见,物理模型作为一种低自由度算法,很难在其固定式偏微分方程的理论根基框架下,在合金设计领域打破其域外扩展能力与准确性的互斥关系. ...
... 综上,域外扩展能力与准确性的互斥关系本质上是受模型的拟合自由度决定的,多数普适性物理模型机制明确,所以方程与参数均固定,基本无自由度,所以拟合能力差;人工智能自由度高,就有更强的数据拟合能力,但其可解释性就不足.而算法自由度的高低实际上是受其使用的本质数学理论决定的,统计数学算法通常自由度高,需大量数据拟合,而偏微分方程则形式固定.因此,物理冶金原理指导人工智能方法的数学理论本质就是综合统计学与微积分各自的优势,建立一个受固定偏微分方程形式约束的统计学算法,如图1d所示,模型建立过程中依然保持统计学算法对数据的自由拟合能力,但要规定一个稳定的方程形式来约束其拟合的宏观方向,在这一综合算法体系中,高自由度的统计学算法用以补足偏微分方程的数据拟合能力,以应对偏离主体物理机制的其他扰动因素,而低自由度的偏微分方程则给予统计学算法一个弱约束,提示统计学算法正确的训练方向,这种提示性的弱约束不但可以帮助模型规避在域外扩展中的不确定性问题,而且可以大幅减少模型训练所需的数据量,从而更适应合金设计领域面临的小样本特点.这个思想实质上比较接近于人工智能中常用的“正则化”处理方法[36],通过向人工智能模型中引入一个函数项,来约束模型的复杂度,从而避免过拟合及域外泛化能力差的问题,因此物理冶金原理指导人工智能方法其实也可以变为更华丽的名字,例如“物理机制正则化”方法. ...
The design of a compositionally robust martensitic creep-resistant steel with an optimized combination of precipitation hardening and solid-solution strengthening for high-temperature use
1
2014
... 已有的合金设计工作均提出:合金设计可以不以最终性能为设计目标,而以组织特征为目标的合金设计可以减少设计过程中的模型建立流程,从而提高设计效率与稳定性[37].但实际上,目前大多数合金设计工作仍然是以最终性能为直接设计目标的,甚至部分工作在数据驱动理念的指引下直接跳过了对组织因素的考虑[38].而本小节的论述依然以固态相变预测为起始,并不完全因为多数材料方向学者高度认可相变在合金设计中所起到的重要作用,更是因为固态相变作为金属材料领域数据最为全面的方向之一,可以更充分地展示与证实上述对物理冶金原理指导人工智能方法理论基础论述的正确性,以及该方法对模型准确性和域外扩展能力的同时提升作用. ...
High-throughput map design of creep life in low-alloy steels by integrating machine learning with a genetic algorithm
1
2022
... 已有的合金设计工作均提出:合金设计可以不以最终性能为设计目标,而以组织特征为目标的合金设计可以减少设计过程中的模型建立流程,从而提高设计效率与稳定性[37].但实际上,目前大多数合金设计工作仍然是以最终性能为直接设计目标的,甚至部分工作在数据驱动理念的指引下直接跳过了对组织因素的考虑[38].而本小节的论述依然以固态相变预测为起始,并不完全因为多数材料方向学者高度认可相变在合金设计中所起到的重要作用,更是因为固态相变作为金属材料领域数据最为全面的方向之一,可以更充分地展示与证实上述对物理冶金原理指导人工智能方法理论基础论述的正确性,以及该方法对模型准确性和域外扩展能力的同时提升作用. ...
A review of the thermal stability of metastable austenite in steels: Martensite formation
1
2021
... 首先,在固态相变领域,热力学理论模型虽然可以基本解决奥氏体相变等扩散型相变的温度点预测问题,但对于切变型马氏体相变开始温度(Ms)的普适性预测一直是领域内的难点问题,而Ms的预测对于淬火-配分(Q&P)钢等高性能钢种的设计至关重要.实际上多年来已经积累了大量的Ms预测模型[39],包括热动力学机理模型[40]、经验公式[41]以及人工智能模型[42]等.图4[43]充分展示了各类型模型准确性与域外扩展能力间的关系.对于已知的511条数据的拟合准确性方面,具有物理可解释性的热力学算法Olson-Cohen模型[44]的拟合准确性最低(MAE = 36.3 K),而完全放弃了物理意义的人工智能模型支持向量机(support vector machine,SVM)则展现出明显更优的拟合准确性(优于物理模型约一倍).而对于域外扩展能力来说则完全相反,在面对新数据的预测时,具有物理意义的Olson-Cohen模型的预测精度甚至出现了略微提升(MAE = 30.3 K),充分体现出其稳定的域外扩展能力,但SVM模型对新数据的预测精度降低了6倍,暴露出其在域外扩展能力方面的问题.而作为物理冶金原理指导人工智能方法的代表,深度数据挖掘指导的卷积神经网络(deep data mining guided convolutional neural network,DDM-CNN)模型对已知数据的拟合准确性与SVM模型基本持平(MAE = 14.7 K),同时,其在高Cr、高Mn的超广域外体系下的大量验证结果中,均体现出良好的稳定性,模型预测精度一直保持在MAE ≈ 24 K的水平.与物理模型和人工智能相比,DDM-CNN模型显然打破了准确性与域外扩展能力的互斥关系.DDM-CNN模型并未基于纯统计数学分析直接建立成分与Ms间的数据关联,而是先基于成分数据信息,使用被高度认可的普适性热力学模型计算了对Ms有主要机制贡献的化学驱动力、形核驱动力等能量项数值,而后将这些包含热力学模型机制的信息通过卷积神经网络的卷积操作引入至人工智能中,与成分信息一起作为输入特征,进行模型训练.因此,在训练过程中,这些能量信息带给了人工智能具有可解释性的热力学机制的同时,约束了其训练与扩展方向,从而助力该模型突破了准确性与域外扩展能力的互斥关系.由此可见,对于Ms的预测案例虽然不是直接针对合金性能设计的典型示范应用,但其是系统性证明物理冶金原理指导人工智能方法理论基础正确性的良好案例.目前该方法在其他固态相变领域的研究工作中也有了广泛应用[45]. ...
Thermodynamically based prediction of the martensite start temperature for commercial steels
1
2012
... 首先,在固态相变领域,热力学理论模型虽然可以基本解决奥氏体相变等扩散型相变的温度点预测问题,但对于切变型马氏体相变开始温度(Ms)的普适性预测一直是领域内的难点问题,而Ms的预测对于淬火-配分(Q&P)钢等高性能钢种的设计至关重要.实际上多年来已经积累了大量的Ms预测模型[39],包括热动力学机理模型[40]、经验公式[41]以及人工智能模型[42]等.图4[43]充分展示了各类型模型准确性与域外扩展能力间的关系.对于已知的511条数据的拟合准确性方面,具有物理可解释性的热力学算法Olson-Cohen模型[44]的拟合准确性最低(MAE = 36.3 K),而完全放弃了物理意义的人工智能模型支持向量机(support vector machine,SVM)则展现出明显更优的拟合准确性(优于物理模型约一倍).而对于域外扩展能力来说则完全相反,在面对新数据的预测时,具有物理意义的Olson-Cohen模型的预测精度甚至出现了略微提升(MAE = 30.3 K),充分体现出其稳定的域外扩展能力,但SVM模型对新数据的预测精度降低了6倍,暴露出其在域外扩展能力方面的问题.而作为物理冶金原理指导人工智能方法的代表,深度数据挖掘指导的卷积神经网络(deep data mining guided convolutional neural network,DDM-CNN)模型对已知数据的拟合准确性与SVM模型基本持平(MAE = 14.7 K),同时,其在高Cr、高Mn的超广域外体系下的大量验证结果中,均体现出良好的稳定性,模型预测精度一直保持在MAE ≈ 24 K的水平.与物理模型和人工智能相比,DDM-CNN模型显然打破了准确性与域外扩展能力的互斥关系.DDM-CNN模型并未基于纯统计数学分析直接建立成分与Ms间的数据关联,而是先基于成分数据信息,使用被高度认可的普适性热力学模型计算了对Ms有主要机制贡献的化学驱动力、形核驱动力等能量项数值,而后将这些包含热力学模型机制的信息通过卷积神经网络的卷积操作引入至人工智能中,与成分信息一起作为输入特征,进行模型训练.因此,在训练过程中,这些能量信息带给了人工智能具有可解释性的热力学机制的同时,约束了其训练与扩展方向,从而助力该模型突破了准确性与域外扩展能力的互斥关系.由此可见,对于Ms的预测案例虽然不是直接针对合金性能设计的典型示范应用,但其是系统性证明物理冶金原理指导人工智能方法理论基础正确性的良好案例.目前该方法在其他固态相变领域的研究工作中也有了广泛应用[45]. ...
Prediction of martensite start temperature in alloy steels with different grain sizes
1
2013
... 首先,在固态相变领域,热力学理论模型虽然可以基本解决奥氏体相变等扩散型相变的温度点预测问题,但对于切变型马氏体相变开始温度(Ms)的普适性预测一直是领域内的难点问题,而Ms的预测对于淬火-配分(Q&P)钢等高性能钢种的设计至关重要.实际上多年来已经积累了大量的Ms预测模型[39],包括热动力学机理模型[40]、经验公式[41]以及人工智能模型[42]等.图4[43]充分展示了各类型模型准确性与域外扩展能力间的关系.对于已知的511条数据的拟合准确性方面,具有物理可解释性的热力学算法Olson-Cohen模型[44]的拟合准确性最低(MAE = 36.3 K),而完全放弃了物理意义的人工智能模型支持向量机(support vector machine,SVM)则展现出明显更优的拟合准确性(优于物理模型约一倍).而对于域外扩展能力来说则完全相反,在面对新数据的预测时,具有物理意义的Olson-Cohen模型的预测精度甚至出现了略微提升(MAE = 30.3 K),充分体现出其稳定的域外扩展能力,但SVM模型对新数据的预测精度降低了6倍,暴露出其在域外扩展能力方面的问题.而作为物理冶金原理指导人工智能方法的代表,深度数据挖掘指导的卷积神经网络(deep data mining guided convolutional neural network,DDM-CNN)模型对已知数据的拟合准确性与SVM模型基本持平(MAE = 14.7 K),同时,其在高Cr、高Mn的超广域外体系下的大量验证结果中,均体现出良好的稳定性,模型预测精度一直保持在MAE ≈ 24 K的水平.与物理模型和人工智能相比,DDM-CNN模型显然打破了准确性与域外扩展能力的互斥关系.DDM-CNN模型并未基于纯统计数学分析直接建立成分与Ms间的数据关联,而是先基于成分数据信息,使用被高度认可的普适性热力学模型计算了对Ms有主要机制贡献的化学驱动力、形核驱动力等能量项数值,而后将这些包含热力学模型机制的信息通过卷积神经网络的卷积操作引入至人工智能中,与成分信息一起作为输入特征,进行模型训练.因此,在训练过程中,这些能量信息带给了人工智能具有可解释性的热力学机制的同时,约束了其训练与扩展方向,从而助力该模型突破了准确性与域外扩展能力的互斥关系.由此可见,对于Ms的预测案例虽然不是直接针对合金性能设计的典型示范应用,但其是系统性证明物理冶金原理指导人工智能方法理论基础正确性的良好案例.目前该方法在其他固态相变领域的研究工作中也有了广泛应用[45]. ...
Machine learning to predict the martensite start temperature in steels
1
2019
... 首先,在固态相变领域,热力学理论模型虽然可以基本解决奥氏体相变等扩散型相变的温度点预测问题,但对于切变型马氏体相变开始温度(Ms)的普适性预测一直是领域内的难点问题,而Ms的预测对于淬火-配分(Q&P)钢等高性能钢种的设计至关重要.实际上多年来已经积累了大量的Ms预测模型[39],包括热动力学机理模型[40]、经验公式[41]以及人工智能模型[42]等.图4[43]充分展示了各类型模型准确性与域外扩展能力间的关系.对于已知的511条数据的拟合准确性方面,具有物理可解释性的热力学算法Olson-Cohen模型[44]的拟合准确性最低(MAE = 36.3 K),而完全放弃了物理意义的人工智能模型支持向量机(support vector machine,SVM)则展现出明显更优的拟合准确性(优于物理模型约一倍).而对于域外扩展能力来说则完全相反,在面对新数据的预测时,具有物理意义的Olson-Cohen模型的预测精度甚至出现了略微提升(MAE = 30.3 K),充分体现出其稳定的域外扩展能力,但SVM模型对新数据的预测精度降低了6倍,暴露出其在域外扩展能力方面的问题.而作为物理冶金原理指导人工智能方法的代表,深度数据挖掘指导的卷积神经网络(deep data mining guided convolutional neural network,DDM-CNN)模型对已知数据的拟合准确性与SVM模型基本持平(MAE = 14.7 K),同时,其在高Cr、高Mn的超广域外体系下的大量验证结果中,均体现出良好的稳定性,模型预测精度一直保持在MAE ≈ 24 K的水平.与物理模型和人工智能相比,DDM-CNN模型显然打破了准确性与域外扩展能力的互斥关系.DDM-CNN模型并未基于纯统计数学分析直接建立成分与Ms间的数据关联,而是先基于成分数据信息,使用被高度认可的普适性热力学模型计算了对Ms有主要机制贡献的化学驱动力、形核驱动力等能量项数值,而后将这些包含热力学模型机制的信息通过卷积神经网络的卷积操作引入至人工智能中,与成分信息一起作为输入特征,进行模型训练.因此,在训练过程中,这些能量信息带给了人工智能具有可解释性的热力学机制的同时,约束了其训练与扩展方向,从而助力该模型突破了准确性与域外扩展能力的互斥关系.由此可见,对于Ms的预测案例虽然不是直接针对合金性能设计的典型示范应用,但其是系统性证明物理冶金原理指导人工智能方法理论基础正确性的良好案例.目前该方法在其他固态相变领域的研究工作中也有了广泛应用[45]. ...
A generic and extensible model for the martensite start temperature incorporating thermodynamic data mining and deep learning framework
3
2022
... 首先,在固态相变领域,热力学理论模型虽然可以基本解决奥氏体相变等扩散型相变的温度点预测问题,但对于切变型马氏体相变开始温度(Ms)的普适性预测一直是领域内的难点问题,而Ms的预测对于淬火-配分(Q&P)钢等高性能钢种的设计至关重要.实际上多年来已经积累了大量的Ms预测模型[39],包括热动力学机理模型[40]、经验公式[41]以及人工智能模型[42]等.图4[43]充分展示了各类型模型准确性与域外扩展能力间的关系.对于已知的511条数据的拟合准确性方面,具有物理可解释性的热力学算法Olson-Cohen模型[44]的拟合准确性最低(MAE = 36.3 K),而完全放弃了物理意义的人工智能模型支持向量机(support vector machine,SVM)则展现出明显更优的拟合准确性(优于物理模型约一倍).而对于域外扩展能力来说则完全相反,在面对新数据的预测时,具有物理意义的Olson-Cohen模型的预测精度甚至出现了略微提升(MAE = 30.3 K),充分体现出其稳定的域外扩展能力,但SVM模型对新数据的预测精度降低了6倍,暴露出其在域外扩展能力方面的问题.而作为物理冶金原理指导人工智能方法的代表,深度数据挖掘指导的卷积神经网络(deep data mining guided convolutional neural network,DDM-CNN)模型对已知数据的拟合准确性与SVM模型基本持平(MAE = 14.7 K),同时,其在高Cr、高Mn的超广域外体系下的大量验证结果中,均体现出良好的稳定性,模型预测精度一直保持在MAE ≈ 24 K的水平.与物理模型和人工智能相比,DDM-CNN模型显然打破了准确性与域外扩展能力的互斥关系.DDM-CNN模型并未基于纯统计数学分析直接建立成分与Ms间的数据关联,而是先基于成分数据信息,使用被高度认可的普适性热力学模型计算了对Ms有主要机制贡献的化学驱动力、形核驱动力等能量项数值,而后将这些包含热力学模型机制的信息通过卷积神经网络的卷积操作引入至人工智能中,与成分信息一起作为输入特征,进行模型训练.因此,在训练过程中,这些能量信息带给了人工智能具有可解释性的热力学机制的同时,约束了其训练与扩展方向,从而助力该模型突破了准确性与域外扩展能力的互斥关系.由此可见,对于Ms的预测案例虽然不是直接针对合金性能设计的典型示范应用,但其是系统性证明物理冶金原理指导人工智能方法理论基础正确性的良好案例.目前该方法在其他固态相变领域的研究工作中也有了广泛应用[45]. ...
... [
43]
Comparisons of accuracy and extensibility of martensite transformation start temperature (<i>M</i><sub>s</sub>) computation models<sup>[<xref ref-type="bibr" rid="R43">43</xref>]</sup> (MAE—mean absolute error, SVM—support vector machine, DDM-CNN—deep data mining guided convolutional neural network)Fig.4![]() <strong>2.2</strong> 热力学信息指导人工智能的合金设计
<strong>2.2</strong> 热力学信息指导人工智能的合金设计在直接针对合金性能设计的研究方面,虽然很难找到像上述Ms预测一样系统性对比物理模型、人工智能及物理冶金原理指导人工智能方法的案例,但也有一些值得关注的结果从另一个角度证明了物理冶金原理指导人工智能方法的本质.Shen等[10]在超高强不锈钢体系下分别使用人工智能和物理冶金原理指导人工智能方法进行了针对硬度的单目标设计.该研究与Ms预测的案例相似,先基于不同钢种的成分信息,使用热力学模型计算了不同钢种中主要析出相的化学驱动力与平衡态相体积分数,然后将这些热力学机制数据与成分工艺信息一起作为输入特征训练SVM模型用以预测硬度,该热力学机制信息指导的SVM模型被命名为物理冶金原理指导的支持向量机(physical metallurgy-guided support vector machine,PM-SVM).而后,该工作通过对比PM-SVM与传统SVM算法(直接建立成分、工艺与硬度间的关系,不加入热力学机制信息),非常直观地展示了其在合金设计中的区别.首先,PM-SVM与传统SVM模型对已知数据的拟合能力没有任何差别,都达到90%以上,说明从准确性的角度来看,2个模型似乎都没有任何问题,可以应用于后续设计.但当将2个模型分别连接优化算法,进行新合金方案的发现时,2个模型的设计结果出现明显差别.传统SVM模型甚至可以提出硬度提升10 HRC的“超强”方案,但该方案的合理性却非常低,其提出的时效温度甚至低到300 ℃以下,根本不可能生成合理的强化型析出相,而实际的实验验证结果也证实该“超强”方案的实际硬度不但没有提升,反而比原有合金下降了接近20 HRC.而PM-SVM模型的设计方案则具有较高的合理性,虽然其预测的硬度提升效果并没有夸张式的增长,但其预测结果与最终的实验验证结果吻合良好,说明其可以切实地指导合金设计. ...
... [
43] (MAE—mean absolute error, SVM—support vector machine, DDM-CNN—deep data mining guided convolutional neural network)
Fig.4![]() <strong>2.2</strong> 热力学信息指导人工智能的合金设计
<strong>2.2</strong> 热力学信息指导人工智能的合金设计在直接针对合金性能设计的研究方面,虽然很难找到像上述Ms预测一样系统性对比物理模型、人工智能及物理冶金原理指导人工智能方法的案例,但也有一些值得关注的结果从另一个角度证明了物理冶金原理指导人工智能方法的本质.Shen等[10]在超高强不锈钢体系下分别使用人工智能和物理冶金原理指导人工智能方法进行了针对硬度的单目标设计.该研究与Ms预测的案例相似,先基于不同钢种的成分信息,使用热力学模型计算了不同钢种中主要析出相的化学驱动力与平衡态相体积分数,然后将这些热力学机制数据与成分工艺信息一起作为输入特征训练SVM模型用以预测硬度,该热力学机制信息指导的SVM模型被命名为物理冶金原理指导的支持向量机(physical metallurgy-guided support vector machine,PM-SVM).而后,该工作通过对比PM-SVM与传统SVM算法(直接建立成分、工艺与硬度间的关系,不加入热力学机制信息),非常直观地展示了其在合金设计中的区别.首先,PM-SVM与传统SVM模型对已知数据的拟合能力没有任何差别,都达到90%以上,说明从准确性的角度来看,2个模型似乎都没有任何问题,可以应用于后续设计.但当将2个模型分别连接优化算法,进行新合金方案的发现时,2个模型的设计结果出现明显差别.传统SVM模型甚至可以提出硬度提升10 HRC的“超强”方案,但该方案的合理性却非常低,其提出的时效温度甚至低到300 ℃以下,根本不可能生成合理的强化型析出相,而实际的实验验证结果也证实该“超强”方案的实际硬度不但没有提升,反而比原有合金下降了接近20 HRC.而PM-SVM模型的设计方案则具有较高的合理性,虽然其预测的硬度提升效果并没有夸张式的增长,但其预测结果与最终的实验验证结果吻合良好,说明其可以切实地指导合金设计. ...
Kinetics of F.C.C. → B.C.C. heterogeneous martensitic nucleation—I. The critical driving force for athermal nucleation
1
1994
... 首先,在固态相变领域,热力学理论模型虽然可以基本解决奥氏体相变等扩散型相变的温度点预测问题,但对于切变型马氏体相变开始温度(Ms)的普适性预测一直是领域内的难点问题,而Ms的预测对于淬火-配分(Q&P)钢等高性能钢种的设计至关重要.实际上多年来已经积累了大量的Ms预测模型[39],包括热动力学机理模型[40]、经验公式[41]以及人工智能模型[42]等.图4[43]充分展示了各类型模型准确性与域外扩展能力间的关系.对于已知的511条数据的拟合准确性方面,具有物理可解释性的热力学算法Olson-Cohen模型[44]的拟合准确性最低(MAE = 36.3 K),而完全放弃了物理意义的人工智能模型支持向量机(support vector machine,SVM)则展现出明显更优的拟合准确性(优于物理模型约一倍).而对于域外扩展能力来说则完全相反,在面对新数据的预测时,具有物理意义的Olson-Cohen模型的预测精度甚至出现了略微提升(MAE = 30.3 K),充分体现出其稳定的域外扩展能力,但SVM模型对新数据的预测精度降低了6倍,暴露出其在域外扩展能力方面的问题.而作为物理冶金原理指导人工智能方法的代表,深度数据挖掘指导的卷积神经网络(deep data mining guided convolutional neural network,DDM-CNN)模型对已知数据的拟合准确性与SVM模型基本持平(MAE = 14.7 K),同时,其在高Cr、高Mn的超广域外体系下的大量验证结果中,均体现出良好的稳定性,模型预测精度一直保持在MAE ≈ 24 K的水平.与物理模型和人工智能相比,DDM-CNN模型显然打破了准确性与域外扩展能力的互斥关系.DDM-CNN模型并未基于纯统计数学分析直接建立成分与Ms间的数据关联,而是先基于成分数据信息,使用被高度认可的普适性热力学模型计算了对Ms有主要机制贡献的化学驱动力、形核驱动力等能量项数值,而后将这些包含热力学模型机制的信息通过卷积神经网络的卷积操作引入至人工智能中,与成分信息一起作为输入特征,进行模型训练.因此,在训练过程中,这些能量信息带给了人工智能具有可解释性的热力学机制的同时,约束了其训练与扩展方向,从而助力该模型突破了准确性与域外扩展能力的互斥关系.由此可见,对于Ms的预测案例虽然不是直接针对合金性能设计的典型示范应用,但其是系统性证明物理冶金原理指导人工智能方法理论基础正确性的良好案例.目前该方法在其他固态相变领域的研究工作中也有了广泛应用[45]. ...
Combination of thermodynamic knowledge and multilayer feedforward neural networks for accurate prediction of MS temperature in steels
1
2020
... 首先,在固态相变领域,热力学理论模型虽然可以基本解决奥氏体相变等扩散型相变的温度点预测问题,但对于切变型马氏体相变开始温度(Ms)的普适性预测一直是领域内的难点问题,而Ms的预测对于淬火-配分(Q&P)钢等高性能钢种的设计至关重要.实际上多年来已经积累了大量的Ms预测模型[39],包括热动力学机理模型[40]、经验公式[41]以及人工智能模型[42]等.图4[43]充分展示了各类型模型准确性与域外扩展能力间的关系.对于已知的511条数据的拟合准确性方面,具有物理可解释性的热力学算法Olson-Cohen模型[44]的拟合准确性最低(MAE = 36.3 K),而完全放弃了物理意义的人工智能模型支持向量机(support vector machine,SVM)则展现出明显更优的拟合准确性(优于物理模型约一倍).而对于域外扩展能力来说则完全相反,在面对新数据的预测时,具有物理意义的Olson-Cohen模型的预测精度甚至出现了略微提升(MAE = 30.3 K),充分体现出其稳定的域外扩展能力,但SVM模型对新数据的预测精度降低了6倍,暴露出其在域外扩展能力方面的问题.而作为物理冶金原理指导人工智能方法的代表,深度数据挖掘指导的卷积神经网络(deep data mining guided convolutional neural network,DDM-CNN)模型对已知数据的拟合准确性与SVM模型基本持平(MAE = 14.7 K),同时,其在高Cr、高Mn的超广域外体系下的大量验证结果中,均体现出良好的稳定性,模型预测精度一直保持在MAE ≈ 24 K的水平.与物理模型和人工智能相比,DDM-CNN模型显然打破了准确性与域外扩展能力的互斥关系.DDM-CNN模型并未基于纯统计数学分析直接建立成分与Ms间的数据关联,而是先基于成分数据信息,使用被高度认可的普适性热力学模型计算了对Ms有主要机制贡献的化学驱动力、形核驱动力等能量项数值,而后将这些包含热力学模型机制的信息通过卷积神经网络的卷积操作引入至人工智能中,与成分信息一起作为输入特征,进行模型训练.因此,在训练过程中,这些能量信息带给了人工智能具有可解释性的热力学机制的同时,约束了其训练与扩展方向,从而助力该模型突破了准确性与域外扩展能力的互斥关系.由此可见,对于Ms的预测案例虽然不是直接针对合金性能设计的典型示范应用,但其是系统性证明物理冶金原理指导人工智能方法理论基础正确性的良好案例.目前该方法在其他固态相变领域的研究工作中也有了广泛应用[45]. ...
Accelerated alloy discovery using synthetic data generation and data mining
5
2023
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
... ,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
... ,
46~
54]
Paradigm of thermodynamic mechanism information-guided artificial intelligence for alloy design<sup>[<xref ref-type="bibr" rid="R10">10</xref>,<xref ref-type="bibr" rid="R46">46</xref>-<xref ref-type="bibr" rid="R54">54</xref>]</sup> (ANN—artificial neural network)Fig.5![]() <strong>2.3</strong> 其他尺度数值数据指导人工智能的设计
<strong>2.3</strong> 其他尺度数值数据指导人工智能的设计与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
... ,
46-
54] (ANN—artificial neural network)
Fig.5![]() <strong>2.3</strong> 其他尺度数值数据指导人工智能的设计
<strong>2.3</strong> 其他尺度数值数据指导人工智能的设计与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
... 与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
Computer alloy design of Ti modified Al-Si-Mg-Sr casting alloys for achieving simultaneous enhancement in strength and ductility
1
2023
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
Integrating machine learning and CALPHAD method for exploring low-modulus near-β-Ti alloys
1
2024
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
Breaking hardness and electrical conductivity trade-off in Cu-Ti alloys through machine learning and Pareto front
1
2024
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
Determination of hardness and Young's modulus in fcc Cu-Ni-Sn-Al alloys via high-throughput experiments, CALPHAD approach and machine learning
1
2024
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
Machine learning for high-entropy alloys: Progress, challenges and opportunities
1
2023
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
Data-driven design of Ni-based turbine disc superalloys to improve yield strength
1
2023
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
Data-driven “cross-component” design and optimization of γ′-strengthened Co-based superalloys
1
2023
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
Data-driven shape memory alloy discovery using Artificial Intelligence Materials Selection (AIMS) framework
5
2022
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
... [54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
... ~
54]
Paradigm of thermodynamic mechanism information-guided artificial intelligence for alloy design<sup>[<xref ref-type="bibr" rid="R10">10</xref>,<xref ref-type="bibr" rid="R46">46</xref>-<xref ref-type="bibr" rid="R54">54</xref>]</sup> (ANN—artificial neural network)Fig.5![]() <strong>2.3</strong> 其他尺度数值数据指导人工智能的设计
<strong>2.3</strong> 其他尺度数值数据指导人工智能的设计与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
... -
54] (ANN—artificial neural network)
Fig.5![]() <strong>2.3</strong> 其他尺度数值数据指导人工智能的设计
<strong>2.3</strong> 其他尺度数值数据指导人工智能的设计与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
... 与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
Explore the full temperature-composition space of 20 quinary CCAs for FCC and BCC single-phases by an iterative machine learning + CALPHAD method
1
2022
... 而在应用技术层面,热力学机制信息指导人工智能也是一个非常容易被推广的合金设计范式(图5[10,46~54]).首先,该方法并不限定所使用的人工智能策略,其可以像Ms计算案例一样与深度学习结合,也可以像超高强钢硬度设计案例一样与相对简单的统计学算法结合,而热力学与相图计算本身更是合金设计中非常常用的技术手段.因此,该范式已在各合金体系下得到了广泛应用,例如其他种类钢铁材料[10,46]、铝合金[47]、钛合金[48]、铜合金[49,50]、高熵合金[51]、镍基高温合金[52]、钴基高温合金[53]、形状记忆合金[54]等.虽然以上列举的诸多案例并未像本小节论述的超高强钢硬度设计案例一样对该方法的理论本质进行深入探讨,但其实际设计效果均是显著的,这也侧面证明了该范式的普适性与可靠性.而这里还要特别提及一个完全区别于上述技术路线的思路:热力学机制信息计算与强化学习的结合[55].之所以称其为完全不同的技术路线,是因为其给予人工智能“约束”的方式完全不同于上述各案例.上述绝大多数案例在引入热力学机制信息的同时并不增加训练样本的数量,只是为训练样本引入了一个更符合物理机制的特征因素,所以这种处理方式是相当柔和的,只是用更符合物理机制的特征“暗示与规劝”人工智能走向一条正确的路.但强化学习的技术路线则是更为直接的“明示”,其通过热力学计算与强化学习结合的筛选机制,制造出更多符合物理冶金原理的“合理数据”,再使这些数据直接参与到模型训练中,获得新模型.实质上,人工智能模型经常会“找到一条错误道路”,其本质原因也可以理解为在正确道路上的数据点还不够多,自由度高的人工智能模型仍然有余力穿梭在各数据点间,走出一条七扭八歪的“邪路”.如果在正确道路上的数据点足够多,占据主导地位,则为了拟合更多的数据,人工智能算法自然会被钉死在这条正确的道路上.但这种“明示”的机制显然与物理冶金原理指导人工智能方法提倡的“正则化”思想有所不同.“正则化”思想更趋近于材料学科的思维模式,用机制去软性引导;而强化学习技术路线更趋近于人工智能思维模式,直接采取扩展数据量的手段硬性钉扎,趋近于上文提到的主动学习的思路.2种思想在合金设计领域孰优孰劣是一个值得在未来研究中进一步探讨的话题. ...
Data mining accelerated the design strategy of high-entropy alloys with the largest hardness based on genetic algorithm optimization
2
2024
... 与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
... [56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
Efficient machine-learning model for fast assessment of elastic properties of high-entropy alloys
0
2022
Modeling solid solution strengthening in high entropy alloys using machine learning
1
2021
... 与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
cardiGAN: A generative adversarial network model for design and discovery of multi principal element alloys
2
2022
... 与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
... [59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
Machine learning assisted composition effective design for precipitation strengthened copper alloys
4
2021
... 与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
... 除却原子尺度与热动力学尺度外,其他尺度数值信息指导合金设计的系统性案例并不多见.同时,部分大尺度下的模拟方法不仅生成数值型信息,更会生成图像型信息,例如晶体塑性有限元,因此其在与人工智能结合时需要使用多模态的图像处理技术,这部分内容会在下文详细论述.尽管如此,在部分特殊的研究体系下,分子动力学、有限元等物理计算方法依然可以通过提供数值型机制信息发挥良好的指导作用(图6[60~67]).例如,分子动力学可以模拟激光加工过程中的烧蚀羽流等分子层面数值机制信息,从而指导人工智能在极少量的训练数据支撑下进行包括激光打孔[63]、激光表面加工[64]在内的多种工艺设计.而对于增材制造这一热点方向,有限元也可以提供3D打印过程中的凝固、热传导等相关数值机制信息,从而指导人工智能在有限样本空间内进行精准的裂纹敏感性预测与设计[65]. ...
... [
60~
67]
Paradigm of multi-scale mechanism information-guided artificial intelligence for design<sup>[<xref ref-type="bibr" rid="R60">60</xref>-<xref ref-type="bibr" rid="R67">67</xref>]</sup> (DFT—density functional theory, FEM—finite element model)Fig.6![]()
综合上述全部案例可以发现,虽然用于指导人工智能的数值信息包含了从第一性原理到宏观有限元的多种尺度物理模型,但上述案例均只分别使用了一种特定尺度的数据,并没有涉及跨尺度数据的同时引入.但实质上,在此人工智能体系下,同时引入多个尺度的物理机制信息在技术方面并不难实现,例如Rao等[66]就在高熵合金设计中通过同时引入热力学与第一性原理数据来指导人工智能训练与合金设计.值得关注的是,该研究工作采用了一个对抗神经网络+传统神经网络+梯度提升树+主动学习的复杂计算流程,因此其使用的训练数据量多达700个样本.有趣的是,在本小节的高熵合金设计案例中,大多数工作仅将机制数据与简单的传统人工智能算法结合,也可优化设计出良好的合金,且其数据需求量大多不超过200条.而在钛合金的设计中,Zou等[67]也同时将包括原子尺度信息、相变尺度信息(层错能)、力学信息(体模量)在内的更多尺度的丰富信息引入相对简单的传统人工智能算法中,从而进行合金的强-塑性协同优化,而此设计中使用的训练数据样本为125条.因此,复杂的人工智能模型构架与算法流程是否真的有助于提升合金设计效率又是一个未来值得深入探讨的方向. ...
... [
60-
67] (DFT—density functional theory, FEM—finite element model)
Fig.6![]()
综合上述全部案例可以发现,虽然用于指导人工智能的数值信息包含了从第一性原理到宏观有限元的多种尺度物理模型,但上述案例均只分别使用了一种特定尺度的数据,并没有涉及跨尺度数据的同时引入.但实质上,在此人工智能体系下,同时引入多个尺度的物理机制信息在技术方面并不难实现,例如Rao等[66]就在高熵合金设计中通过同时引入热力学与第一性原理数据来指导人工智能训练与合金设计.值得关注的是,该研究工作采用了一个对抗神经网络+传统神经网络+梯度提升树+主动学习的复杂计算流程,因此其使用的训练数据量多达700个样本.有趣的是,在本小节的高熵合金设计案例中,大多数工作仅将机制数据与简单的传统人工智能算法结合,也可优化设计出良好的合金,且其数据需求量大多不超过200条.而在钛合金的设计中,Zou等[67]也同时将包括原子尺度信息、相变尺度信息(层错能)、力学信息(体模量)在内的更多尺度的丰富信息引入相对简单的传统人工智能算法中,从而进行合金的强-塑性协同优化,而此设计中使用的训练数据样本为125条.因此,复杂的人工智能模型构架与算法流程是否真的有助于提升合金设计效率又是一个未来值得深入探讨的方向. ...
Machine learning identified materials descriptors for ferroelectricity
1
2021
... 与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
Accelerated design of MTX alloys with targeted magnetostructural properties through interpretable machine learning
1
2022
... 与热力学相同,其他尺度的数值模拟结果也可以使用与2.2节相同的方式引入人工智能,并起到良好的指导作用.但需要特别注意的是,这种信息引入的效果与信息本身的准确性息息相关,可以想象,如果将错误或不准确的信息引入人工智能,则人工智能也自然会被其引入“歧途”,导致准确性与域外扩展能力降低.热力学理论在合金设计领域经过多年的广泛验证,其准确性已经达到很高程度,因此其完全可以胜任对人工智能的指导任务.而另一个可以想到的相对准确的物理机制信息,自然就是原子尺度的物理本征参数,因为这些参数大多都是已被准确测量的定值,或者可使用无自拟合参数的第一性原理算法计算得到.因此,除热力学机制信息之外,原子尺度信息是最多被用以指导人工智能的物理机制数据.而基于原子尺度数值信息指导人工智能的合金设计案例则大部分集中于高熵合金体系[56~59],其本质原因是高熵合金成分配比均衡的特点尤其有利于第一性原理建模,从而可以更为便捷地获得丰富的原子尺度机制数据.而大多数高熵合金设计的案例与上述超高强钢硬度设计案例所使用的技术路线相同,只是将其中的热力学机制信息替换为原子尺度机制信息,使用的人工智能方法根据其面向的不同数据特点可酌情选择SVM、随机森林、XGboost等统计或集成学习算法[56~58].无独有偶,在众多高熵合金设计工作中,也有一种完全不同的技术路线存在:Li等[59]将原子尺度机制信息引入生成对抗网络(generative adversarial networks,GAN)来生成更多的“合理数据”,进而将这些合理数据与原始数据结合,共同训练人工智能模型以进行高熵合金设计.显然,这个技术路线与2.2节中介绍的强化学习技术路线如出一辙,其核心思想完全一致,只是将数据生成过程中使用的人工智能策略由强化学习变为了对抗神经网络.由此可见,“正则化”思想与“数据增强”思想的差异化技术路线选择现象在多种合金设计方向上都存在,而目前为止尚鲜有人针对同一个合金设计问题对比2种技术路线的具体优劣势,更缺乏针对某一类型问题应该选择哪种技术路线的指导方针.因此,未来对此问题的系统性探索具有极高的理论与应用价值.当然,如图5[10,46~54]所示,与热力学机制数据指导相同,原子尺度信息指导人工智能的方法也不仅被应用于高熵合金,在铜合金[60]、铁电材料[61]、磁性材料[62]等合金设计中均有广泛应用,这些应用案例虽有算法上的细节差异,但主体技术路线与上述诸多高熵合金的案例基本相同,因此不再一一赘述. ...
Optimization of multistage femtosecond laser drilling process using machine learning coupled with molecular dynamics
1
2022
... 除却原子尺度与热动力学尺度外,其他尺度数值信息指导合金设计的系统性案例并不多见.同时,部分大尺度下的模拟方法不仅生成数值型信息,更会生成图像型信息,例如晶体塑性有限元,因此其在与人工智能结合时需要使用多模态的图像处理技术,这部分内容会在下文详细论述.尽管如此,在部分特殊的研究体系下,分子动力学、有限元等物理计算方法依然可以通过提供数值型机制信息发挥良好的指导作用(图6[60~67]).例如,分子动力学可以模拟激光加工过程中的烧蚀羽流等分子层面数值机制信息,从而指导人工智能在极少量的训练数据支撑下进行包括激光打孔[63]、激光表面加工[64]在内的多种工艺设计.而对于增材制造这一热点方向,有限元也可以提供3D打印过程中的凝固、热传导等相关数值机制信息,从而指导人工智能在有限样本空间内进行精准的裂纹敏感性预测与设计[65]. ...
Accelerating ultrashort pulse laser micromachining process comprehensive optimization using a machine learning cycle design strategy integrated with a physical model
1
2024
... 除却原子尺度与热动力学尺度外,其他尺度数值信息指导合金设计的系统性案例并不多见.同时,部分大尺度下的模拟方法不仅生成数值型信息,更会生成图像型信息,例如晶体塑性有限元,因此其在与人工智能结合时需要使用多模态的图像处理技术,这部分内容会在下文详细论述.尽管如此,在部分特殊的研究体系下,分子动力学、有限元等物理计算方法依然可以通过提供数值型机制信息发挥良好的指导作用(图6[60~67]).例如,分子动力学可以模拟激光加工过程中的烧蚀羽流等分子层面数值机制信息,从而指导人工智能在极少量的训练数据支撑下进行包括激光打孔[63]、激光表面加工[64]在内的多种工艺设计.而对于增材制造这一热点方向,有限元也可以提供3D打印过程中的凝固、热传导等相关数值机制信息,从而指导人工智能在有限样本空间内进行精准的裂纹敏感性预测与设计[65]. ...
Crack free metal printing using physics informed machine learning
2
2022
... 除却原子尺度与热动力学尺度外,其他尺度数值信息指导合金设计的系统性案例并不多见.同时,部分大尺度下的模拟方法不仅生成数值型信息,更会生成图像型信息,例如晶体塑性有限元,因此其在与人工智能结合时需要使用多模态的图像处理技术,这部分内容会在下文详细论述.尽管如此,在部分特殊的研究体系下,分子动力学、有限元等物理计算方法依然可以通过提供数值型机制信息发挥良好的指导作用(图6[60~67]).例如,分子动力学可以模拟激光加工过程中的烧蚀羽流等分子层面数值机制信息,从而指导人工智能在极少量的训练数据支撑下进行包括激光打孔[63]、激光表面加工[64]在内的多种工艺设计.而对于增材制造这一热点方向,有限元也可以提供3D打印过程中的凝固、热传导等相关数值机制信息,从而指导人工智能在有限样本空间内进行精准的裂纹敏感性预测与设计[65]. ...
... 由此说来,为何还要花大量篇幅介绍PINN这一方法?PINN在合金设计方面的价值在于其是一个非常方便的微分方程“万能自动”求解器.试想在使用物理模型进行合金计算设计的过程中,搜索到某一个合金成分空间时无法收敛,需要将原本的梯度下降法变成Newton迭代法才能继续算出结果,这将会给合金的自动化设计带来很大的不便.同理,当使用有限元进行合金计算设计时,若针对不同案例都要重新进行手动网格划分,如何去进行合金方案的大范围自动化搜索?所以,当使用PINN作为一个物理方程的替代品时,可直接规避各种网格划分及优化算法选取的问题,从而更为便捷地形成一个自动化迭代寻优的设计系统.相比于有限元等无法规避手动调整网格划分步骤的算法,PINN可以成为一个取代有限元的自动化提供机制数据的方法,用于在合金设计过程中更便捷地为其他人工智能算法的迭代过程提供持续的数据供应.例如,Mondal等[65]用PINN提供传热与凝固相关数据,从而利用该机制数据指导人工智能预测3D打印合金的裂纹敏感性.Zhang等[99]则结合图像信息与PINN提供的数据信息进行多模态数据分析建模,用以分析铝合金材料的内部缺陷.因此,从取代物理模型、为人工智能算法提供更便捷的物理机制信息获取渠道方面,PINN可以发挥良好的贡献作用. ...
Machine learning-enabled high-entropy alloy discovery
1
2022
... 综合上述全部案例可以发现,虽然用于指导人工智能的数值信息包含了从第一性原理到宏观有限元的多种尺度物理模型,但上述案例均只分别使用了一种特定尺度的数据,并没有涉及跨尺度数据的同时引入.但实质上,在此人工智能体系下,同时引入多个尺度的物理机制信息在技术方面并不难实现,例如Rao等[66]就在高熵合金设计中通过同时引入热力学与第一性原理数据来指导人工智能训练与合金设计.值得关注的是,该研究工作采用了一个对抗神经网络+传统神经网络+梯度提升树+主动学习的复杂计算流程,因此其使用的训练数据量多达700个样本.有趣的是,在本小节的高熵合金设计案例中,大多数工作仅将机制数据与简单的传统人工智能算法结合,也可优化设计出良好的合金,且其数据需求量大多不超过200条.而在钛合金的设计中,Zou等[67]也同时将包括原子尺度信息、相变尺度信息(层错能)、力学信息(体模量)在内的更多尺度的丰富信息引入相对简单的传统人工智能算法中,从而进行合金的强-塑性协同优化,而此设计中使用的训练数据样本为125条.因此,复杂的人工智能模型构架与算法流程是否真的有助于提升合金设计效率又是一个未来值得深入探讨的方向. ...
Integrating data mining and machine learning to discover high-strength ductile titanium alloys
5
2021
... 除却原子尺度与热动力学尺度外,其他尺度数值信息指导合金设计的系统性案例并不多见.同时,部分大尺度下的模拟方法不仅生成数值型信息,更会生成图像型信息,例如晶体塑性有限元,因此其在与人工智能结合时需要使用多模态的图像处理技术,这部分内容会在下文详细论述.尽管如此,在部分特殊的研究体系下,分子动力学、有限元等物理计算方法依然可以通过提供数值型机制信息发挥良好的指导作用(图6[60~67]).例如,分子动力学可以模拟激光加工过程中的烧蚀羽流等分子层面数值机制信息,从而指导人工智能在极少量的训练数据支撑下进行包括激光打孔[63]、激光表面加工[64]在内的多种工艺设计.而对于增材制造这一热点方向,有限元也可以提供3D打印过程中的凝固、热传导等相关数值机制信息,从而指导人工智能在有限样本空间内进行精准的裂纹敏感性预测与设计[65]. ...
... ~
67]
Paradigm of multi-scale mechanism information-guided artificial intelligence for design<sup>[<xref ref-type="bibr" rid="R60">60</xref>-<xref ref-type="bibr" rid="R67">67</xref>]</sup> (DFT—density functional theory, FEM—finite element model)Fig.6![]()
综合上述全部案例可以发现,虽然用于指导人工智能的数值信息包含了从第一性原理到宏观有限元的多种尺度物理模型,但上述案例均只分别使用了一种特定尺度的数据,并没有涉及跨尺度数据的同时引入.但实质上,在此人工智能体系下,同时引入多个尺度的物理机制信息在技术方面并不难实现,例如Rao等[66]就在高熵合金设计中通过同时引入热力学与第一性原理数据来指导人工智能训练与合金设计.值得关注的是,该研究工作采用了一个对抗神经网络+传统神经网络+梯度提升树+主动学习的复杂计算流程,因此其使用的训练数据量多达700个样本.有趣的是,在本小节的高熵合金设计案例中,大多数工作仅将机制数据与简单的传统人工智能算法结合,也可优化设计出良好的合金,且其数据需求量大多不超过200条.而在钛合金的设计中,Zou等[67]也同时将包括原子尺度信息、相变尺度信息(层错能)、力学信息(体模量)在内的更多尺度的丰富信息引入相对简单的传统人工智能算法中,从而进行合金的强-塑性协同优化,而此设计中使用的训练数据样本为125条.因此,复杂的人工智能模型构架与算法流程是否真的有助于提升合金设计效率又是一个未来值得深入探讨的方向. ...
... -
67] (DFT—density functional theory, FEM—finite element model)
Fig.6![]()
综合上述全部案例可以发现,虽然用于指导人工智能的数值信息包含了从第一性原理到宏观有限元的多种尺度物理模型,但上述案例均只分别使用了一种特定尺度的数据,并没有涉及跨尺度数据的同时引入.但实质上,在此人工智能体系下,同时引入多个尺度的物理机制信息在技术方面并不难实现,例如Rao等[66]就在高熵合金设计中通过同时引入热力学与第一性原理数据来指导人工智能训练与合金设计.值得关注的是,该研究工作采用了一个对抗神经网络+传统神经网络+梯度提升树+主动学习的复杂计算流程,因此其使用的训练数据量多达700个样本.有趣的是,在本小节的高熵合金设计案例中,大多数工作仅将机制数据与简单的传统人工智能算法结合,也可优化设计出良好的合金,且其数据需求量大多不超过200条.而在钛合金的设计中,Zou等[67]也同时将包括原子尺度信息、相变尺度信息(层错能)、力学信息(体模量)在内的更多尺度的丰富信息引入相对简单的传统人工智能算法中,从而进行合金的强-塑性协同优化,而此设计中使用的训练数据样本为125条.因此,复杂的人工智能模型构架与算法流程是否真的有助于提升合金设计效率又是一个未来值得深入探讨的方向. ...
... 综合上述全部案例可以发现,虽然用于指导人工智能的数值信息包含了从第一性原理到宏观有限元的多种尺度物理模型,但上述案例均只分别使用了一种特定尺度的数据,并没有涉及跨尺度数据的同时引入.但实质上,在此人工智能体系下,同时引入多个尺度的物理机制信息在技术方面并不难实现,例如Rao等[66]就在高熵合金设计中通过同时引入热力学与第一性原理数据来指导人工智能训练与合金设计.值得关注的是,该研究工作采用了一个对抗神经网络+传统神经网络+梯度提升树+主动学习的复杂计算流程,因此其使用的训练数据量多达700个样本.有趣的是,在本小节的高熵合金设计案例中,大多数工作仅将机制数据与简单的传统人工智能算法结合,也可优化设计出良好的合金,且其数据需求量大多不超过200条.而在钛合金的设计中,Zou等[67]也同时将包括原子尺度信息、相变尺度信息(层错能)、力学信息(体模量)在内的更多尺度的丰富信息引入相对简单的传统人工智能算法中,从而进行合金的强-塑性协同优化,而此设计中使用的训练数据样本为125条.因此,复杂的人工智能模型构架与算法流程是否真的有助于提升合金设计效率又是一个未来值得深入探讨的方向. ...
... (2) 跨尺度物理模型方向.相比于物理机制研究,物理模型的发展则更需要关注人工智能技术所带来的冲击.目前大多数链式结构的多尺度模型由于其很难通过自身的发展突破至跨尺度层级,因此其大概率会在合金设计领域逐步走下神坛.链式结构的多尺度模型很容易随着模型串联数量的增加而产生误差累积,同时其所需算力也会呈几何级数的增长.正因受到上述限制,目前领域内大多数多尺度模型均是局限在某个尺度范围内的“局部多尺度”模型,而并非真正意义上可以贯通原子尺度到宏观尺度的“全局跨尺度”模型.而人工智能则为实现真正意义上全局跨尺度信息的融合提供了一个更为宽松的并行式框架,各尺度信息完全可以如本文中所举的钛合金设计案例[67]一样同时输入至人工智能模型中,而多模态深度学习模型更可以给予跨尺度数据更为合理的分层级、分结构的引入方式,从而避免传统局部多尺度集成模型链式结构导致的误差累积问题.因此,从合金设计的需求角度,未来对于物理模型的研究或许应淡化其对某一特定体系数据的吻合精准度,或对某一特殊机制的特异性修正,淡化物理模型链式集成思想,尽量在单一尺度下开发对多种体系均适用的普适性模型,或者像热力学理论一样,通过系统性建立参数数据库提升模型的普适性应用价值,而后通过人工智能策略集成为并行式跨尺度计算体系.而只有具备足够普适性的物理模型才能在此跨尺度体系中成为指导人工智能域外扩展方向的核心,这也充分符合AI4Sci的中心思想.而上述观点也仅是针对合金设计的需求而提出的可行发展方向.如果抛开合金设计不谈,建立链式结构的物理模型依然是解析科学机制的有效方法,人工智能也可辅助加速各尺度物理模型间的衔接,提升计算效率,从而帮助链式结构物理模型在机制解析层面突破跨尺度技术. ...
Overview: Computer vision and machine learning for microstructural characterization and analysis
1
2020
... 早期的图像信息指导人工智能研究工作主要关注于显微组织的图像识别,在人工智能的术语中称其为“语义分割”,即训练人工智能模型,使其能精准识别显微组织照片中的相边界与相分布区域,从而进行图片中诸如晶粒度、相体积分数等核心组织信息的精准提取[68].对于图像数据的使用始于图像识别与核心信息提取,实质上是受到了第2节所述的数值型数据处理方法的思想引导,或者是物理机制建模长期以来的思维定式.在材料学大量的传统研究中,组织信息很多情况下并不是以图像的形式直接引入模型的,而是以相体积分数、长径比等数值信息引入的.如果可以从组织图像中精准地提取出上述核心组织信息,自然可以沿用第2节所列举的诸多数值型数据处理方法,使用显微组织核心信息指导人工智能.因为该技术路线除了要引入组织图像识别技术外,其与第2节所述的诸多数值型数据处理方法并无其他不同,所以本小节只专注于对图像识别方法发展的论述. ...
Overview: Machine learning for segmentation and classification of complex steel microstructures
1
2024
... 人工智能的语义分割技术在显微组织图像中的应用已经有接近15年的历史,其形成的丰富而系统性的研究基础已在Müller等[69]的综述中予以详尽的论述.不同研究中使用的各种人工智能算法不胜枚举,而使用频次最多的是基于卷积网络的视觉几何组(visual geometry group,VGG)构架[70]、基于融合式架构的U型网络(U-shaped network,Unet)[71]和基于残差算法的残差网络(residual network,ResNet)构架[72].因此,在处理一些常见的显微组织图像识别问题时可以优先尝试这几种技术路线.而无论使用哪种人工智能构架,永恒不变的难点问题依然在“数据标签”的精准度上(图7[73~75]).如果原始训练数据都没有一个准确的“标签”作为模型可学习的正确答案,那模型的最终性能也不可能优异.而标签的标注成本与其准确度是呈正相关的.直接使用一个灰度阈值来界定各相的边界最为简单,可以快速获得大量标签,但显然其并不准确.比较常用的折中方案是人工手动标注,其相对更费时费力,但准确性会有所提升.但人工标注终究还是会有人为误差,所以最精准的标注方式实际上是使用电子背散射衍射(EBSD)等测试设备直接精准测量相边界等信息,这一方法的代表性工作是Shen等[73]提出的EBSD指导深度学习的SEM图像识别方法.显然,通过EBSD标签的使用,显微组织识别的准确率大幅提升,稳定性也有了显著的改善,但该方法的主要局限性还是在于标签的成本.制备一个与SEM照片有良好对应性的EBSD相图标签所需要花费的时间与资金成本是明显高于人为经验标注的,因此Shen等[73]的工作一直以小样本图像识别算法为主体,来大幅规避大量标签制备带来的成本问题.实质上标签准确性与成本间的客观关系很难被打破,所以目前越来越多工作开始关注于如何在不使用标签的情况下直接获得良好的图像识别效果,这就是图像识别领域技术由监督学习逐渐向半监督,乃至无监督学习的转变.虽然Kunselman等[74]已综述了无监督学习算法在显微组织图像识别中的应用进展,但其综述的大多研究结果只是对图像的分类,而非语义分割,且其中大量工作是使用相场法计算得到的组织模拟图,而非真实组织照片.目前真正能在无标签的情况下实现普适性显微组织图像语义分割的工作少之又少.而由Meta开源的图像分割大模型——分割一切任何模型(segment anything model,SAM)的诞生似乎预示着普适性显微组织图像语义分割模型的发展又将进入一个里程碑式的时期.已有最新研究结果展现出了SAM在完全无标签支持的情况下对显微组织图像语义分割问题的良好处理效果,这一工作可为显微组织图像识别领域的发展带来一个令人振奋的全新思路[75]. ...
Very deep convolutional networks for large-scale image recognition
1
... 人工智能的语义分割技术在显微组织图像中的应用已经有接近15年的历史,其形成的丰富而系统性的研究基础已在Müller等[69]的综述中予以详尽的论述.不同研究中使用的各种人工智能算法不胜枚举,而使用频次最多的是基于卷积网络的视觉几何组(visual geometry group,VGG)构架[70]、基于融合式架构的U型网络(U-shaped network,Unet)[71]和基于残差算法的残差网络(residual network,ResNet)构架[72].因此,在处理一些常见的显微组织图像识别问题时可以优先尝试这几种技术路线.而无论使用哪种人工智能构架,永恒不变的难点问题依然在“数据标签”的精准度上(图7[73~75]).如果原始训练数据都没有一个准确的“标签”作为模型可学习的正确答案,那模型的最终性能也不可能优异.而标签的标注成本与其准确度是呈正相关的.直接使用一个灰度阈值来界定各相的边界最为简单,可以快速获得大量标签,但显然其并不准确.比较常用的折中方案是人工手动标注,其相对更费时费力,但准确性会有所提升.但人工标注终究还是会有人为误差,所以最精准的标注方式实际上是使用电子背散射衍射(EBSD)等测试设备直接精准测量相边界等信息,这一方法的代表性工作是Shen等[73]提出的EBSD指导深度学习的SEM图像识别方法.显然,通过EBSD标签的使用,显微组织识别的准确率大幅提升,稳定性也有了显著的改善,但该方法的主要局限性还是在于标签的成本.制备一个与SEM照片有良好对应性的EBSD相图标签所需要花费的时间与资金成本是明显高于人为经验标注的,因此Shen等[73]的工作一直以小样本图像识别算法为主体,来大幅规避大量标签制备带来的成本问题.实质上标签准确性与成本间的客观关系很难被打破,所以目前越来越多工作开始关注于如何在不使用标签的情况下直接获得良好的图像识别效果,这就是图像识别领域技术由监督学习逐渐向半监督,乃至无监督学习的转变.虽然Kunselman等[74]已综述了无监督学习算法在显微组织图像识别中的应用进展,但其综述的大多研究结果只是对图像的分类,而非语义分割,且其中大量工作是使用相场法计算得到的组织模拟图,而非真实组织照片.目前真正能在无标签的情况下实现普适性显微组织图像语义分割的工作少之又少.而由Meta开源的图像分割大模型——分割一切任何模型(segment anything model,SAM)的诞生似乎预示着普适性显微组织图像语义分割模型的发展又将进入一个里程碑式的时期.已有最新研究结果展现出了SAM在完全无标签支持的情况下对显微组织图像语义分割问题的良好处理效果,这一工作可为显微组织图像识别领域的发展带来一个令人振奋的全新思路[75]. ...
U-Net: Convolutional networks for biomedical image segmentation
1
2015
... 人工智能的语义分割技术在显微组织图像中的应用已经有接近15年的历史,其形成的丰富而系统性的研究基础已在Müller等[69]的综述中予以详尽的论述.不同研究中使用的各种人工智能算法不胜枚举,而使用频次最多的是基于卷积网络的视觉几何组(visual geometry group,VGG)构架[70]、基于融合式架构的U型网络(U-shaped network,Unet)[71]和基于残差算法的残差网络(residual network,ResNet)构架[72].因此,在处理一些常见的显微组织图像识别问题时可以优先尝试这几种技术路线.而无论使用哪种人工智能构架,永恒不变的难点问题依然在“数据标签”的精准度上(图7[73~75]).如果原始训练数据都没有一个准确的“标签”作为模型可学习的正确答案,那模型的最终性能也不可能优异.而标签的标注成本与其准确度是呈正相关的.直接使用一个灰度阈值来界定各相的边界最为简单,可以快速获得大量标签,但显然其并不准确.比较常用的折中方案是人工手动标注,其相对更费时费力,但准确性会有所提升.但人工标注终究还是会有人为误差,所以最精准的标注方式实际上是使用电子背散射衍射(EBSD)等测试设备直接精准测量相边界等信息,这一方法的代表性工作是Shen等[73]提出的EBSD指导深度学习的SEM图像识别方法.显然,通过EBSD标签的使用,显微组织识别的准确率大幅提升,稳定性也有了显著的改善,但该方法的主要局限性还是在于标签的成本.制备一个与SEM照片有良好对应性的EBSD相图标签所需要花费的时间与资金成本是明显高于人为经验标注的,因此Shen等[73]的工作一直以小样本图像识别算法为主体,来大幅规避大量标签制备带来的成本问题.实质上标签准确性与成本间的客观关系很难被打破,所以目前越来越多工作开始关注于如何在不使用标签的情况下直接获得良好的图像识别效果,这就是图像识别领域技术由监督学习逐渐向半监督,乃至无监督学习的转变.虽然Kunselman等[74]已综述了无监督学习算法在显微组织图像识别中的应用进展,但其综述的大多研究结果只是对图像的分类,而非语义分割,且其中大量工作是使用相场法计算得到的组织模拟图,而非真实组织照片.目前真正能在无标签的情况下实现普适性显微组织图像语义分割的工作少之又少.而由Meta开源的图像分割大模型——分割一切任何模型(segment anything model,SAM)的诞生似乎预示着普适性显微组织图像语义分割模型的发展又将进入一个里程碑式的时期.已有最新研究结果展现出了SAM在完全无标签支持的情况下对显微组织图像语义分割问题的良好处理效果,这一工作可为显微组织图像识别领域的发展带来一个令人振奋的全新思路[75]. ...
Deep residual learning for image recognition
1
2016
... 人工智能的语义分割技术在显微组织图像中的应用已经有接近15年的历史,其形成的丰富而系统性的研究基础已在Müller等[69]的综述中予以详尽的论述.不同研究中使用的各种人工智能算法不胜枚举,而使用频次最多的是基于卷积网络的视觉几何组(visual geometry group,VGG)构架[70]、基于融合式架构的U型网络(U-shaped network,Unet)[71]和基于残差算法的残差网络(residual network,ResNet)构架[72].因此,在处理一些常见的显微组织图像识别问题时可以优先尝试这几种技术路线.而无论使用哪种人工智能构架,永恒不变的难点问题依然在“数据标签”的精准度上(图7[73~75]).如果原始训练数据都没有一个准确的“标签”作为模型可学习的正确答案,那模型的最终性能也不可能优异.而标签的标注成本与其准确度是呈正相关的.直接使用一个灰度阈值来界定各相的边界最为简单,可以快速获得大量标签,但显然其并不准确.比较常用的折中方案是人工手动标注,其相对更费时费力,但准确性会有所提升.但人工标注终究还是会有人为误差,所以最精准的标注方式实际上是使用电子背散射衍射(EBSD)等测试设备直接精准测量相边界等信息,这一方法的代表性工作是Shen等[73]提出的EBSD指导深度学习的SEM图像识别方法.显然,通过EBSD标签的使用,显微组织识别的准确率大幅提升,稳定性也有了显著的改善,但该方法的主要局限性还是在于标签的成本.制备一个与SEM照片有良好对应性的EBSD相图标签所需要花费的时间与资金成本是明显高于人为经验标注的,因此Shen等[73]的工作一直以小样本图像识别算法为主体,来大幅规避大量标签制备带来的成本问题.实质上标签准确性与成本间的客观关系很难被打破,所以目前越来越多工作开始关注于如何在不使用标签的情况下直接获得良好的图像识别效果,这就是图像识别领域技术由监督学习逐渐向半监督,乃至无监督学习的转变.虽然Kunselman等[74]已综述了无监督学习算法在显微组织图像识别中的应用进展,但其综述的大多研究结果只是对图像的分类,而非语义分割,且其中大量工作是使用相场法计算得到的组织模拟图,而非真实组织照片.目前真正能在无标签的情况下实现普适性显微组织图像语义分割的工作少之又少.而由Meta开源的图像分割大模型——分割一切任何模型(segment anything model,SAM)的诞生似乎预示着普适性显微组织图像语义分割模型的发展又将进入一个里程碑式的时期.已有最新研究结果展现出了SAM在完全无标签支持的情况下对显微组织图像语义分割问题的良好处理效果,这一工作可为显微组织图像识别领域的发展带来一个令人振奋的全新思路[75]. ...
A generic high-throughput microstructure classification and quantification method for regular SEM images of complex steel microstructures combining EBSD labeling and deep learning
8
2021
... 人工智能的语义分割技术在显微组织图像中的应用已经有接近15年的历史,其形成的丰富而系统性的研究基础已在Müller等[69]的综述中予以详尽的论述.不同研究中使用的各种人工智能算法不胜枚举,而使用频次最多的是基于卷积网络的视觉几何组(visual geometry group,VGG)构架[70]、基于融合式架构的U型网络(U-shaped network,Unet)[71]和基于残差算法的残差网络(residual network,ResNet)构架[72].因此,在处理一些常见的显微组织图像识别问题时可以优先尝试这几种技术路线.而无论使用哪种人工智能构架,永恒不变的难点问题依然在“数据标签”的精准度上(图7[73~75]).如果原始训练数据都没有一个准确的“标签”作为模型可学习的正确答案,那模型的最终性能也不可能优异.而标签的标注成本与其准确度是呈正相关的.直接使用一个灰度阈值来界定各相的边界最为简单,可以快速获得大量标签,但显然其并不准确.比较常用的折中方案是人工手动标注,其相对更费时费力,但准确性会有所提升.但人工标注终究还是会有人为误差,所以最精准的标注方式实际上是使用电子背散射衍射(EBSD)等测试设备直接精准测量相边界等信息,这一方法的代表性工作是Shen等[73]提出的EBSD指导深度学习的SEM图像识别方法.显然,通过EBSD标签的使用,显微组织识别的准确率大幅提升,稳定性也有了显著的改善,但该方法的主要局限性还是在于标签的成本.制备一个与SEM照片有良好对应性的EBSD相图标签所需要花费的时间与资金成本是明显高于人为经验标注的,因此Shen等[73]的工作一直以小样本图像识别算法为主体,来大幅规避大量标签制备带来的成本问题.实质上标签准确性与成本间的客观关系很难被打破,所以目前越来越多工作开始关注于如何在不使用标签的情况下直接获得良好的图像识别效果,这就是图像识别领域技术由监督学习逐渐向半监督,乃至无监督学习的转变.虽然Kunselman等[74]已综述了无监督学习算法在显微组织图像识别中的应用进展,但其综述的大多研究结果只是对图像的分类,而非语义分割,且其中大量工作是使用相场法计算得到的组织模拟图,而非真实组织照片.目前真正能在无标签的情况下实现普适性显微组织图像语义分割的工作少之又少.而由Meta开源的图像分割大模型——分割一切任何模型(segment anything model,SAM)的诞生似乎预示着普适性显微组织图像语义分割模型的发展又将进入一个里程碑式的时期.已有最新研究结果展现出了SAM在完全无标签支持的情况下对显微组织图像语义分割问题的良好处理效果,这一工作可为显微组织图像识别领域的发展带来一个令人振奋的全新思路[75]. ...
... [73]提出的EBSD指导深度学习的SEM图像识别方法.显然,通过EBSD标签的使用,显微组织识别的准确率大幅提升,稳定性也有了显著的改善,但该方法的主要局限性还是在于标签的成本.制备一个与SEM照片有良好对应性的EBSD相图标签所需要花费的时间与资金成本是明显高于人为经验标注的,因此Shen等[73]的工作一直以小样本图像识别算法为主体,来大幅规避大量标签制备带来的成本问题.实质上标签准确性与成本间的客观关系很难被打破,所以目前越来越多工作开始关注于如何在不使用标签的情况下直接获得良好的图像识别效果,这就是图像识别领域技术由监督学习逐渐向半监督,乃至无监督学习的转变.虽然Kunselman等[74]已综述了无监督学习算法在显微组织图像识别中的应用进展,但其综述的大多研究结果只是对图像的分类,而非语义分割,且其中大量工作是使用相场法计算得到的组织模拟图,而非真实组织照片.目前真正能在无标签的情况下实现普适性显微组织图像语义分割的工作少之又少.而由Meta开源的图像分割大模型——分割一切任何模型(segment anything model,SAM)的诞生似乎预示着普适性显微组织图像语义分割模型的发展又将进入一个里程碑式的时期.已有最新研究结果展现出了SAM在完全无标签支持的情况下对显微组织图像语义分割问题的良好处理效果,这一工作可为显微组织图像识别领域的发展带来一个令人振奋的全新思路[75]. ...
... [73]的工作一直以小样本图像识别算法为主体,来大幅规避大量标签制备带来的成本问题.实质上标签准确性与成本间的客观关系很难被打破,所以目前越来越多工作开始关注于如何在不使用标签的情况下直接获得良好的图像识别效果,这就是图像识别领域技术由监督学习逐渐向半监督,乃至无监督学习的转变.虽然Kunselman等[74]已综述了无监督学习算法在显微组织图像识别中的应用进展,但其综述的大多研究结果只是对图像的分类,而非语义分割,且其中大量工作是使用相场法计算得到的组织模拟图,而非真实组织照片.目前真正能在无标签的情况下实现普适性显微组织图像语义分割的工作少之又少.而由Meta开源的图像分割大模型——分割一切任何模型(segment anything model,SAM)的诞生似乎预示着普适性显微组织图像语义分割模型的发展又将进入一个里程碑式的时期.已有最新研究结果展现出了SAM在完全无标签支持的情况下对显微组织图像语义分割问题的良好处理效果,这一工作可为显微组织图像识别领域的发展带来一个令人振奋的全新思路[75]. ...
... [
73~
75]
Comparisons of algorithms for guiding artificial intelligence with image core information<sup>[<xref ref-type="bibr" rid="R73">73</xref>-<xref ref-type="bibr" rid="R75">75</xref>]</sup> (DL—deep learning, SAM—segment anything model, ML1 and ML2 represent different machine learning models for regression)(a1-a12) large sample, low accuracy ...
... [
73-
75] (DL—deep learning, SAM—segment anything model, ML1 and ML2 represent different machine learning models for regression)
(a1-a12) large sample, low accuracy ...
... 如果上述例子有助于研究者理解GAN的不稳定性及其在材料学小数据环境下应用的局限性,那本文后续推荐另一种算法替代GAN的原因也就很清晰了,这种算法就是变分自编码器(variational autoencoder,VAE)[88,89],其也是AI4Sci领域中受到广泛关注的算法之一[6].与GAN的区别是,VAE是自监督学习算法.在小样本环境下,VAE不容易像GAN一样过度发散而导致一些图像无法生成或生成的图像不合理的问题(图9[73,76,87,90]).当然,数据量不足会导致VAE生成的图像模糊.但在分析组织与性能关系时,一个模糊的组织图片也基本不影响使用,可以权当拍摄组织照片时焦距未能调好,其总比一张错误的组织照片要有价值.因此,VAE在基于真实组织图像的合金设计中已有成功的案例.Pei等[89]通过对钢铁材料组织的自监督学习建立了可进行钢铁材料组织生成的VAE模型,该模型可以为开发更优力学性能的钢铁材料提供定性的搜索方向指导.虽然该工作没能给出可进行精准定量化合金设计的模型,但其对于VAE算法在合金设计方向上的应用具有里程碑式的意义.而Ma等[90]则以双相钢为研究对象,提供了一个更具参考价值的合金设计案例,其使用22个合金样本获得组织照片,照片经裁剪后为700余条图像样本,建立了双相钢下的VAE模型,并且真正实现了显微组织图像与成分、工艺、性能间的全链条预测,并且基于该全链条预测模型定量化设计了多种高性能双相钢,实验验证结果良好.模型所提方案无论在显微组织图像还是最终力学性能的预测结果方面都与实际制备出的钢种吻合,充分证明了该方法的有效性,而且22个合金获得的700余条组织图片样本需求显然比GAN所需的5000,甚至上万图片样本要更为人性化.当然,虽然VAE算法在双相钢中实现了“成分-工艺-组织图像-性能”全链条预测与指导合金设计的理想模式,但其稳定性如何,在预测的组织图像信息指导下模型的域外扩展能力是否得到了切实的改善,是否打破了准确性与域外扩展能力的互斥关系,以及在更多合金体系下VAE算法是否依然适用,诸多问题都尚待探索与解答,基于“成分-工艺-组织图像-性能”全链条预测理念的合金设计方法刚刚迈出历史性的第一步,仍然任重而道远. ...
... [
73,
76,
87,
90]
Mechanism correlation and data requirements of various image algorithms<sup>[<xref ref-type="bibr" rid="R73">73</xref>,<xref ref-type="bibr" rid="R76">76</xref>,<xref ref-type="bibr" rid="R87">87</xref>,<xref ref-type="bibr" rid="R90">90</xref>]</sup>Fig.9![]() <strong>4</strong> 物理机制指导人工智能
<strong>4</strong> 物理机制指导人工智能由以上论述可见,本文一直在强调物理模型与机制对人工智能的“弱约束”作用及其重要性,这也是物理冶金原理指导人工智能最核心的理论本质.而前文所列举的诸多案例引入这种“弱约束”作用的方式并非直接将模型或机制本身融入人工智能算法,而是以相对间接的数据输入形式加入一种隐性的“规劝”.例如,在数值型数据方面将热力学模型以能量数据的形式引入统计学习算法、在图像数据方面将晶体塑性本构方程以应力云图的形式引入深度学习网络.然而这种“规劝”式的处理方式也存在局限性,例如其会受到引入数据准确性的影响、引入的物理指导信息过多或维度过大也会导致过拟合等.因此,如果可以将物理机制以更直接的方式加入到人工智能的构架中,则可以大幅避免通过数据间接引入造成的上述诸多问题.因此,本小节专门针对“非数据引入”型的物理冶金原理指导人工智能方法进行总结分析. ...
... [
73,
76,
87,
90]
Fig.9![]() <strong>4</strong> 物理机制指导人工智能
<strong>4</strong> 物理机制指导人工智能由以上论述可见,本文一直在强调物理模型与机制对人工智能的“弱约束”作用及其重要性,这也是物理冶金原理指导人工智能最核心的理论本质.而前文所列举的诸多案例引入这种“弱约束”作用的方式并非直接将模型或机制本身融入人工智能算法,而是以相对间接的数据输入形式加入一种隐性的“规劝”.例如,在数值型数据方面将热力学模型以能量数据的形式引入统计学习算法、在图像数据方面将晶体塑性本构方程以应力云图的形式引入深度学习网络.然而这种“规劝”式的处理方式也存在局限性,例如其会受到引入数据准确性的影响、引入的物理指导信息过多或维度过大也会导致过拟合等.因此,如果可以将物理机制以更直接的方式加入到人工智能的构架中,则可以大幅避免通过数据间接引入造成的上述诸多问题.因此,本小节专门针对“非数据引入”型的物理冶金原理指导人工智能方法进行总结分析. ...
Microstructure classification in the unsupervised context
1
2022
... 人工智能的语义分割技术在显微组织图像中的应用已经有接近15年的历史,其形成的丰富而系统性的研究基础已在Müller等[69]的综述中予以详尽的论述.不同研究中使用的各种人工智能算法不胜枚举,而使用频次最多的是基于卷积网络的视觉几何组(visual geometry group,VGG)构架[70]、基于融合式架构的U型网络(U-shaped network,Unet)[71]和基于残差算法的残差网络(residual network,ResNet)构架[72].因此,在处理一些常见的显微组织图像识别问题时可以优先尝试这几种技术路线.而无论使用哪种人工智能构架,永恒不变的难点问题依然在“数据标签”的精准度上(图7[73~75]).如果原始训练数据都没有一个准确的“标签”作为模型可学习的正确答案,那模型的最终性能也不可能优异.而标签的标注成本与其准确度是呈正相关的.直接使用一个灰度阈值来界定各相的边界最为简单,可以快速获得大量标签,但显然其并不准确.比较常用的折中方案是人工手动标注,其相对更费时费力,但准确性会有所提升.但人工标注终究还是会有人为误差,所以最精准的标注方式实际上是使用电子背散射衍射(EBSD)等测试设备直接精准测量相边界等信息,这一方法的代表性工作是Shen等[73]提出的EBSD指导深度学习的SEM图像识别方法.显然,通过EBSD标签的使用,显微组织识别的准确率大幅提升,稳定性也有了显著的改善,但该方法的主要局限性还是在于标签的成本.制备一个与SEM照片有良好对应性的EBSD相图标签所需要花费的时间与资金成本是明显高于人为经验标注的,因此Shen等[73]的工作一直以小样本图像识别算法为主体,来大幅规避大量标签制备带来的成本问题.实质上标签准确性与成本间的客观关系很难被打破,所以目前越来越多工作开始关注于如何在不使用标签的情况下直接获得良好的图像识别效果,这就是图像识别领域技术由监督学习逐渐向半监督,乃至无监督学习的转变.虽然Kunselman等[74]已综述了无监督学习算法在显微组织图像识别中的应用进展,但其综述的大多研究结果只是对图像的分类,而非语义分割,且其中大量工作是使用相场法计算得到的组织模拟图,而非真实组织照片.目前真正能在无标签的情况下实现普适性显微组织图像语义分割的工作少之又少.而由Meta开源的图像分割大模型——分割一切任何模型(segment anything model,SAM)的诞生似乎预示着普适性显微组织图像语义分割模型的发展又将进入一个里程碑式的时期.已有最新研究结果展现出了SAM在完全无标签支持的情况下对显微组织图像语义分割问题的良好处理效果,这一工作可为显微组织图像识别领域的发展带来一个令人振奋的全新思路[75]. ...
Alloy microstructure segmentation through SAM and domain knowledge without extra training
4
2025
... 人工智能的语义分割技术在显微组织图像中的应用已经有接近15年的历史,其形成的丰富而系统性的研究基础已在Müller等[69]的综述中予以详尽的论述.不同研究中使用的各种人工智能算法不胜枚举,而使用频次最多的是基于卷积网络的视觉几何组(visual geometry group,VGG)构架[70]、基于融合式架构的U型网络(U-shaped network,Unet)[71]和基于残差算法的残差网络(residual network,ResNet)构架[72].因此,在处理一些常见的显微组织图像识别问题时可以优先尝试这几种技术路线.而无论使用哪种人工智能构架,永恒不变的难点问题依然在“数据标签”的精准度上(图7[73~75]).如果原始训练数据都没有一个准确的“标签”作为模型可学习的正确答案,那模型的最终性能也不可能优异.而标签的标注成本与其准确度是呈正相关的.直接使用一个灰度阈值来界定各相的边界最为简单,可以快速获得大量标签,但显然其并不准确.比较常用的折中方案是人工手动标注,其相对更费时费力,但准确性会有所提升.但人工标注终究还是会有人为误差,所以最精准的标注方式实际上是使用电子背散射衍射(EBSD)等测试设备直接精准测量相边界等信息,这一方法的代表性工作是Shen等[73]提出的EBSD指导深度学习的SEM图像识别方法.显然,通过EBSD标签的使用,显微组织识别的准确率大幅提升,稳定性也有了显著的改善,但该方法的主要局限性还是在于标签的成本.制备一个与SEM照片有良好对应性的EBSD相图标签所需要花费的时间与资金成本是明显高于人为经验标注的,因此Shen等[73]的工作一直以小样本图像识别算法为主体,来大幅规避大量标签制备带来的成本问题.实质上标签准确性与成本间的客观关系很难被打破,所以目前越来越多工作开始关注于如何在不使用标签的情况下直接获得良好的图像识别效果,这就是图像识别领域技术由监督学习逐渐向半监督,乃至无监督学习的转变.虽然Kunselman等[74]已综述了无监督学习算法在显微组织图像识别中的应用进展,但其综述的大多研究结果只是对图像的分类,而非语义分割,且其中大量工作是使用相场法计算得到的组织模拟图,而非真实组织照片.目前真正能在无标签的情况下实现普适性显微组织图像语义分割的工作少之又少.而由Meta开源的图像分割大模型——分割一切任何模型(segment anything model,SAM)的诞生似乎预示着普适性显微组织图像语义分割模型的发展又将进入一个里程碑式的时期.已有最新研究结果展现出了SAM在完全无标签支持的情况下对显微组织图像语义分割问题的良好处理效果,这一工作可为显微组织图像识别领域的发展带来一个令人振奋的全新思路[75]. ...
... [75]. ...
... ~
75]
Comparisons of algorithms for guiding artificial intelligence with image core information<sup>[<xref ref-type="bibr" rid="R73">73</xref>-<xref ref-type="bibr" rid="R75">75</xref>]</sup> (DL—deep learning, SAM—segment anything model, ML1 and ML2 represent different machine learning models for regression)(a1-a12) large sample, low accuracy ...
... -
75] (DL—deep learning, SAM—segment anything model, ML1 and ML2 represent different machine learning models for regression)
(a1-a12) large sample, low accuracy ...
Building a quantitative composition-microstructure-property relationship of dual-phase steels via multimodal data mining
4
2023
... 图像的本质是一个由诸多像素点数值组成的矩阵,而成分、工艺、性能等离散型数值数据也可以用向量表示.所以从数学本质来说,2者也可以看作是模态相同或至少是相近的数据.因此,只需将图像这一矩阵数据通过卷积操作转换成向量数据,就可以方便地与成分、工艺、性能等向量数据协同分析,这一处理方式用传统卷积神经网络构架就可以实现,并不用涉及诸多更为复杂的人工智能策略.而这一思路最具代表性的范例是双相钢的常规力学性能预测[76].该研究将双相钢的多种组织图片(相分布图、带衬度(BC)图、局部取向差(KAM)图)与钢种成分信息联合,共同作为输入,训练卷积神经网络用以预测钢种的强度与塑性,取得了良好的模型准确性与域外扩展能力,充分证明了使用组织图像作为“弱约束”指导人工智能,也可以达到打破模型准确性与域外扩展能力互斥关系的效果.钛合金领域也同时发表了基于多模态思想的合金设计工作[77],而且同样使用卷积神经网络预测合金的常规力学性能(压缩).但值得关注的是,2者使用的具体技术方案略有不同:钛合金设计的案例中直接使用了全连接层向量拼接的技术手段融合成分信息与组织信息,双相钢的案例中则更为系统地对比了图像点乘的预处理技术方案与全连接层向量拼接技术方案2种路线,同时指出了全连接层向量拼接技术方案的模型准确性可能会受到全连接层向量维度变化的影响.而且双相钢案例用更为直观的反向热图生成方法证明了该模型具有极强的物理可解释性,能够反向指明显微组织图像中对性能贡献最大的相区域,这也是模型具有良好域外扩展能力的本质原因(图8).目前,多模态数据处理方法被进一步推广应用至更多领域,包括应力诱导马氏体相变温度的预测[78]等.更有趣的是,近期该方法被应用于与晶体塑性有限元的结合,获得了良好的效果[79].该工作将晶体塑性有限元计算获得的应力云图引入卷积神经网络,指导其进行应力-应变曲线的预测.由于应力云图包含基本的晶体塑性本构方程信息,因此,卷积神经网络在晶体塑性本构的“弱约束”下获得了极强的域外扩展能力.在无任何人为拟合参数的前提下,该模型可以实现双相钢应力-应变曲线的普适性预测,针对不同成分和工艺,甚至不同热处理工艺路线,双相钢均能获得稳定的预测结果.在该方向上为解决晶体塑性有限元因参数敏感性导致的准确性问题和人工智能的域外扩展能力问题提供了高可行性思路.综上,合金设计领域的多模态数据处理研究尚处于起步阶段,目前形成的系统性技术方案也多基于最基本的卷积神经网络构架,但其已经可以被用来解决诸多领域内存在的难点问题,助力高效的合金设计.进一步开发适用于材料学数据特点的,具有更强大数据分析与融合能力的多模态分析策略则是未来的高潜力研究方向. ...
... 如果上述例子有助于研究者理解GAN的不稳定性及其在材料学小数据环境下应用的局限性,那本文后续推荐另一种算法替代GAN的原因也就很清晰了,这种算法就是变分自编码器(variational autoencoder,VAE)[88,89],其也是AI4Sci领域中受到广泛关注的算法之一[6].与GAN的区别是,VAE是自监督学习算法.在小样本环境下,VAE不容易像GAN一样过度发散而导致一些图像无法生成或生成的图像不合理的问题(图9[73,76,87,90]).当然,数据量不足会导致VAE生成的图像模糊.但在分析组织与性能关系时,一个模糊的组织图片也基本不影响使用,可以权当拍摄组织照片时焦距未能调好,其总比一张错误的组织照片要有价值.因此,VAE在基于真实组织图像的合金设计中已有成功的案例.Pei等[89]通过对钢铁材料组织的自监督学习建立了可进行钢铁材料组织生成的VAE模型,该模型可以为开发更优力学性能的钢铁材料提供定性的搜索方向指导.虽然该工作没能给出可进行精准定量化合金设计的模型,但其对于VAE算法在合金设计方向上的应用具有里程碑式的意义.而Ma等[90]则以双相钢为研究对象,提供了一个更具参考价值的合金设计案例,其使用22个合金样本获得组织照片,照片经裁剪后为700余条图像样本,建立了双相钢下的VAE模型,并且真正实现了显微组织图像与成分、工艺、性能间的全链条预测,并且基于该全链条预测模型定量化设计了多种高性能双相钢,实验验证结果良好.模型所提方案无论在显微组织图像还是最终力学性能的预测结果方面都与实际制备出的钢种吻合,充分证明了该方法的有效性,而且22个合金获得的700余条组织图片样本需求显然比GAN所需的5000,甚至上万图片样本要更为人性化.当然,虽然VAE算法在双相钢中实现了“成分-工艺-组织图像-性能”全链条预测与指导合金设计的理想模式,但其稳定性如何,在预测的组织图像信息指导下模型的域外扩展能力是否得到了切实的改善,是否打破了准确性与域外扩展能力的互斥关系,以及在更多合金体系下VAE算法是否依然适用,诸多问题都尚待探索与解答,基于“成分-工艺-组织图像-性能”全链条预测理念的合金设计方法刚刚迈出历史性的第一步,仍然任重而道远. ...
... ,
76,
87,
90]
Mechanism correlation and data requirements of various image algorithms<sup>[<xref ref-type="bibr" rid="R73">73</xref>,<xref ref-type="bibr" rid="R76">76</xref>,<xref ref-type="bibr" rid="R87">87</xref>,<xref ref-type="bibr" rid="R90">90</xref>]</sup>Fig.9![]() <strong>4</strong> 物理机制指导人工智能
<strong>4</strong> 物理机制指导人工智能由以上论述可见,本文一直在强调物理模型与机制对人工智能的“弱约束”作用及其重要性,这也是物理冶金原理指导人工智能最核心的理论本质.而前文所列举的诸多案例引入这种“弱约束”作用的方式并非直接将模型或机制本身融入人工智能算法,而是以相对间接的数据输入形式加入一种隐性的“规劝”.例如,在数值型数据方面将热力学模型以能量数据的形式引入统计学习算法、在图像数据方面将晶体塑性本构方程以应力云图的形式引入深度学习网络.然而这种“规劝”式的处理方式也存在局限性,例如其会受到引入数据准确性的影响、引入的物理指导信息过多或维度过大也会导致过拟合等.因此,如果可以将物理机制以更直接的方式加入到人工智能的构架中,则可以大幅避免通过数据间接引入造成的上述诸多问题.因此,本小节专门针对“非数据引入”型的物理冶金原理指导人工智能方法进行总结分析. ...
... ,
76,
87,
90]
Fig.9![]() <strong>4</strong> 物理机制指导人工智能
<strong>4</strong> 物理机制指导人工智能由以上论述可见,本文一直在强调物理模型与机制对人工智能的“弱约束”作用及其重要性,这也是物理冶金原理指导人工智能最核心的理论本质.而前文所列举的诸多案例引入这种“弱约束”作用的方式并非直接将模型或机制本身融入人工智能算法,而是以相对间接的数据输入形式加入一种隐性的“规劝”.例如,在数值型数据方面将热力学模型以能量数据的形式引入统计学习算法、在图像数据方面将晶体塑性本构方程以应力云图的形式引入深度学习网络.然而这种“规劝”式的处理方式也存在局限性,例如其会受到引入数据准确性的影响、引入的物理指导信息过多或维度过大也会导致过拟合等.因此,如果可以将物理机制以更直接的方式加入到人工智能的构架中,则可以大幅避免通过数据间接引入造成的上述诸多问题.因此,本小节专门针对“非数据引入”型的物理冶金原理指导人工智能方法进行总结分析. ...
Neural network modeling of titanium alloy composition-microstructure-property relationships based on multimodal data
1
2023
... 图像的本质是一个由诸多像素点数值组成的矩阵,而成分、工艺、性能等离散型数值数据也可以用向量表示.所以从数学本质来说,2者也可以看作是模态相同或至少是相近的数据.因此,只需将图像这一矩阵数据通过卷积操作转换成向量数据,就可以方便地与成分、工艺、性能等向量数据协同分析,这一处理方式用传统卷积神经网络构架就可以实现,并不用涉及诸多更为复杂的人工智能策略.而这一思路最具代表性的范例是双相钢的常规力学性能预测[76].该研究将双相钢的多种组织图片(相分布图、带衬度(BC)图、局部取向差(KAM)图)与钢种成分信息联合,共同作为输入,训练卷积神经网络用以预测钢种的强度与塑性,取得了良好的模型准确性与域外扩展能力,充分证明了使用组织图像作为“弱约束”指导人工智能,也可以达到打破模型准确性与域外扩展能力互斥关系的效果.钛合金领域也同时发表了基于多模态思想的合金设计工作[77],而且同样使用卷积神经网络预测合金的常规力学性能(压缩).但值得关注的是,2者使用的具体技术方案略有不同:钛合金设计的案例中直接使用了全连接层向量拼接的技术手段融合成分信息与组织信息,双相钢的案例中则更为系统地对比了图像点乘的预处理技术方案与全连接层向量拼接技术方案2种路线,同时指出了全连接层向量拼接技术方案的模型准确性可能会受到全连接层向量维度变化的影响.而且双相钢案例用更为直观的反向热图生成方法证明了该模型具有极强的物理可解释性,能够反向指明显微组织图像中对性能贡献最大的相区域,这也是模型具有良好域外扩展能力的本质原因(图8).目前,多模态数据处理方法被进一步推广应用至更多领域,包括应力诱导马氏体相变温度的预测[78]等.更有趣的是,近期该方法被应用于与晶体塑性有限元的结合,获得了良好的效果[79].该工作将晶体塑性有限元计算获得的应力云图引入卷积神经网络,指导其进行应力-应变曲线的预测.由于应力云图包含基本的晶体塑性本构方程信息,因此,卷积神经网络在晶体塑性本构的“弱约束”下获得了极强的域外扩展能力.在无任何人为拟合参数的前提下,该模型可以实现双相钢应力-应变曲线的普适性预测,针对不同成分和工艺,甚至不同热处理工艺路线,双相钢均能获得稳定的预测结果.在该方向上为解决晶体塑性有限元因参数敏感性导致的准确性问题和人工智能的域外扩展能力问题提供了高可行性思路.综上,合金设计领域的多模态数据处理研究尚处于起步阶段,目前形成的系统性技术方案也多基于最基本的卷积神经网络构架,但其已经可以被用来解决诸多领域内存在的难点问题,助力高效的合金设计.进一步开发适用于材料学数据特点的,具有更强大数据分析与融合能力的多模态分析策略则是未来的高潜力研究方向. ...
Prediction of deformation-induced martensite start temperature by convolutional neural network with dual mode features
1
2022
... 图像的本质是一个由诸多像素点数值组成的矩阵,而成分、工艺、性能等离散型数值数据也可以用向量表示.所以从数学本质来说,2者也可以看作是模态相同或至少是相近的数据.因此,只需将图像这一矩阵数据通过卷积操作转换成向量数据,就可以方便地与成分、工艺、性能等向量数据协同分析,这一处理方式用传统卷积神经网络构架就可以实现,并不用涉及诸多更为复杂的人工智能策略.而这一思路最具代表性的范例是双相钢的常规力学性能预测[76].该研究将双相钢的多种组织图片(相分布图、带衬度(BC)图、局部取向差(KAM)图)与钢种成分信息联合,共同作为输入,训练卷积神经网络用以预测钢种的强度与塑性,取得了良好的模型准确性与域外扩展能力,充分证明了使用组织图像作为“弱约束”指导人工智能,也可以达到打破模型准确性与域外扩展能力互斥关系的效果.钛合金领域也同时发表了基于多模态思想的合金设计工作[77],而且同样使用卷积神经网络预测合金的常规力学性能(压缩).但值得关注的是,2者使用的具体技术方案略有不同:钛合金设计的案例中直接使用了全连接层向量拼接的技术手段融合成分信息与组织信息,双相钢的案例中则更为系统地对比了图像点乘的预处理技术方案与全连接层向量拼接技术方案2种路线,同时指出了全连接层向量拼接技术方案的模型准确性可能会受到全连接层向量维度变化的影响.而且双相钢案例用更为直观的反向热图生成方法证明了该模型具有极强的物理可解释性,能够反向指明显微组织图像中对性能贡献最大的相区域,这也是模型具有良好域外扩展能力的本质原因(图8).目前,多模态数据处理方法被进一步推广应用至更多领域,包括应力诱导马氏体相变温度的预测[78]等.更有趣的是,近期该方法被应用于与晶体塑性有限元的结合,获得了良好的效果[79].该工作将晶体塑性有限元计算获得的应力云图引入卷积神经网络,指导其进行应力-应变曲线的预测.由于应力云图包含基本的晶体塑性本构方程信息,因此,卷积神经网络在晶体塑性本构的“弱约束”下获得了极强的域外扩展能力.在无任何人为拟合参数的前提下,该模型可以实现双相钢应力-应变曲线的普适性预测,针对不同成分和工艺,甚至不同热处理工艺路线,双相钢均能获得稳定的预测结果.在该方向上为解决晶体塑性有限元因参数敏感性导致的准确性问题和人工智能的域外扩展能力问题提供了高可行性思路.综上,合金设计领域的多模态数据处理研究尚处于起步阶段,目前形成的系统性技术方案也多基于最基本的卷积神经网络构架,但其已经可以被用来解决诸多领域内存在的难点问题,助力高效的合金设计.进一步开发适用于材料学数据特点的,具有更强大数据分析与融合能力的多模态分析策略则是未来的高潜力研究方向. ...
Fitting-free mechanical response prediction in dual-phase steels by crystal plasticity theory guided deep learning
1
2025
... 图像的本质是一个由诸多像素点数值组成的矩阵,而成分、工艺、性能等离散型数值数据也可以用向量表示.所以从数学本质来说,2者也可以看作是模态相同或至少是相近的数据.因此,只需将图像这一矩阵数据通过卷积操作转换成向量数据,就可以方便地与成分、工艺、性能等向量数据协同分析,这一处理方式用传统卷积神经网络构架就可以实现,并不用涉及诸多更为复杂的人工智能策略.而这一思路最具代表性的范例是双相钢的常规力学性能预测[76].该研究将双相钢的多种组织图片(相分布图、带衬度(BC)图、局部取向差(KAM)图)与钢种成分信息联合,共同作为输入,训练卷积神经网络用以预测钢种的强度与塑性,取得了良好的模型准确性与域外扩展能力,充分证明了使用组织图像作为“弱约束”指导人工智能,也可以达到打破模型准确性与域外扩展能力互斥关系的效果.钛合金领域也同时发表了基于多模态思想的合金设计工作[77],而且同样使用卷积神经网络预测合金的常规力学性能(压缩).但值得关注的是,2者使用的具体技术方案略有不同:钛合金设计的案例中直接使用了全连接层向量拼接的技术手段融合成分信息与组织信息,双相钢的案例中则更为系统地对比了图像点乘的预处理技术方案与全连接层向量拼接技术方案2种路线,同时指出了全连接层向量拼接技术方案的模型准确性可能会受到全连接层向量维度变化的影响.而且双相钢案例用更为直观的反向热图生成方法证明了该模型具有极强的物理可解释性,能够反向指明显微组织图像中对性能贡献最大的相区域,这也是模型具有良好域外扩展能力的本质原因(图8).目前,多模态数据处理方法被进一步推广应用至更多领域,包括应力诱导马氏体相变温度的预测[78]等.更有趣的是,近期该方法被应用于与晶体塑性有限元的结合,获得了良好的效果[79].该工作将晶体塑性有限元计算获得的应力云图引入卷积神经网络,指导其进行应力-应变曲线的预测.由于应力云图包含基本的晶体塑性本构方程信息,因此,卷积神经网络在晶体塑性本构的“弱约束”下获得了极强的域外扩展能力.在无任何人为拟合参数的前提下,该模型可以实现双相钢应力-应变曲线的普适性预测,针对不同成分和工艺,甚至不同热处理工艺路线,双相钢均能获得稳定的预测结果.在该方向上为解决晶体塑性有限元因参数敏感性导致的准确性问题和人工智能的域外扩展能力问题提供了高可行性思路.综上,合金设计领域的多模态数据处理研究尚处于起步阶段,目前形成的系统性技术方案也多基于最基本的卷积神经网络构架,但其已经可以被用来解决诸多领域内存在的难点问题,助力高效的合金设计.进一步开发适用于材料学数据特点的,具有更强大数据分析与融合能力的多模态分析策略则是未来的高潜力研究方向. ...
Generative adversarial network technologies and applications in computer vision
1
2020
... 上述多模态分析方法可以实现显微组织图像与成分、工艺信息的联合分析,共同用来预测性能,甚至应力-应变曲线,但实质上并未建立起成分、工艺与显微组织图像之间的关系.而材料学科的研究模式向来以“成分-工艺-组织-性能”全链条分析为核心,在多模态分析的基础上,进一步实现基于成分、工艺向显微组织图像的预测,则自然成为了打通整个计算链条的终极目标.而此链条中的核心难点技术就是“成分、工艺信息→显微组织图像”的预测,这一技术涉及人工智能领域的热点研究方向之一:图像生成模型[80]. ...
Generative adversarial nets
1
2014
... 当论及图像生成领域,应最先被提及的自然是应用最为广泛的GAN[81].值得注意的是,GAN虽然在合金组织分析研究中被广泛提及,但其并不是本文主要推荐使用的策略.GAN的本质是训练得到一个图像生成器和一个图像判别器,图像生成器可以将一个向量转化成矩阵式的图像,而图像鉴别器可以将矩阵式的图像转化成一个向量以鉴别其真伪.试想,当显微组织图像可以转化成一个对应的特征向量时,自然就可以通过传统机器学习方式建立起成分、工艺信息向量与显微组织特征向量间的关系模型,从而通过成分、工艺信息预测出对应的显微组织特征向量,进而再使用图像生成器将该向量转化为矩阵式的图像,呈现出显微组织图.更重要的是GAN是一个无监督学习网络,不存在语义分割中所涉及的“标签”问题.因此GAN在基于图像的合金设计领域中也有诸多应用,例如Qian等[82]使用GAN进行力学超材料设计,让其寻找可使材料性能变得更佳的超材料结构图样.而使用GAN进行纯图像生成的研究工作则更多[83~85],例如Long等[84]使用GAN助力稳定晶体结构的搜索,Yang[85]使用GAN生成晶粒长大、枝晶生长等组织图像,为图像识别工作提供更多训练数据等.但可以发现,虽然理论上GAN可以实现“成分-工艺-真实组织图像-性能”的全链条模型构建,但遗憾的是,真正实现这一理想效果的示范案例很少,其本质原因还是材料学领域的小样本限制问题.基于前文对于诸多图像相关案例的论述不难发现,无论是图像识别、多模态处理,还是图像生成,其处理过程的数学本质是相通的,都是先将图像这一矩阵数据转换成更易处理的小维度向量数据,然后再做后续计算.图像识别是先将显微组织图片转换成特征向量,再将该特征向量解码成一个只包含核心信息的相分布图;多模态处理则根本不用将特征向量解码成图片,而是直接用其去预测性能数值;而基于GAN的图像生成则是要依据特征向量再构造出一个与原始组织图片相似的“真实”全信息图像,这3者间的难度差异是不可同日而语的(图8).在合金设计领域小样本实验数据的环境下,GAN很难被训练稳定,并实现合理的真实组织图像生成与预测,这也是为何目前合金设计领域多数GAN相关的研究是使用相场等模拟手段提供数据来源,而非用实验获得的真实显微组织图像.而为数不多的基于真实组织照片的GAN工作也是在大量数据积累的基础上才得以实现的,例如Cao等[86]针对单一的Ti-6Al-4V合金体系进行3D打印工艺分析,在组织形式相对固定的体系环境下,该工作依然积累了450张真实组织照片,并通过数据增强与图像切割,最终获得了一个多达10.8万张子图的数据库,才完成了GAN的训练,而且该工作只建立了成分、工艺与显微组织间的预测模型,并未涉及对后续性能的预测.可想而知,面对组织状态更为多变的复杂合金体系,再引入性能预测功能,GAN训练的数据需求是会更为夸张的.实质上,早在2018年,美国西北大学Ankit Agrawal团队的Yang等[87]就针对利用GAN建立“成分-工艺-真实组织图像-性能”全链条模型进行了探索,并认为这一GAN框架的训练数据需求量至少是5000个显微组织图像样本,这一工作可以给予后续研究人员在人工智能方法选择上提供极大的指导. ...
Design of architectured composite materials with an efficient, adaptive artificial neural network-based generative design method
1
2022
... 当论及图像生成领域,应最先被提及的自然是应用最为广泛的GAN[81].值得注意的是,GAN虽然在合金组织分析研究中被广泛提及,但其并不是本文主要推荐使用的策略.GAN的本质是训练得到一个图像生成器和一个图像判别器,图像生成器可以将一个向量转化成矩阵式的图像,而图像鉴别器可以将矩阵式的图像转化成一个向量以鉴别其真伪.试想,当显微组织图像可以转化成一个对应的特征向量时,自然就可以通过传统机器学习方式建立起成分、工艺信息向量与显微组织特征向量间的关系模型,从而通过成分、工艺信息预测出对应的显微组织特征向量,进而再使用图像生成器将该向量转化为矩阵式的图像,呈现出显微组织图.更重要的是GAN是一个无监督学习网络,不存在语义分割中所涉及的“标签”问题.因此GAN在基于图像的合金设计领域中也有诸多应用,例如Qian等[82]使用GAN进行力学超材料设计,让其寻找可使材料性能变得更佳的超材料结构图样.而使用GAN进行纯图像生成的研究工作则更多[83~85],例如Long等[84]使用GAN助力稳定晶体结构的搜索,Yang[85]使用GAN生成晶粒长大、枝晶生长等组织图像,为图像识别工作提供更多训练数据等.但可以发现,虽然理论上GAN可以实现“成分-工艺-真实组织图像-性能”的全链条模型构建,但遗憾的是,真正实现这一理想效果的示范案例很少,其本质原因还是材料学领域的小样本限制问题.基于前文对于诸多图像相关案例的论述不难发现,无论是图像识别、多模态处理,还是图像生成,其处理过程的数学本质是相通的,都是先将图像这一矩阵数据转换成更易处理的小维度向量数据,然后再做后续计算.图像识别是先将显微组织图片转换成特征向量,再将该特征向量解码成一个只包含核心信息的相分布图;多模态处理则根本不用将特征向量解码成图片,而是直接用其去预测性能数值;而基于GAN的图像生成则是要依据特征向量再构造出一个与原始组织图片相似的“真实”全信息图像,这3者间的难度差异是不可同日而语的(图8).在合金设计领域小样本实验数据的环境下,GAN很难被训练稳定,并实现合理的真实组织图像生成与预测,这也是为何目前合金设计领域多数GAN相关的研究是使用相场等模拟手段提供数据来源,而非用实验获得的真实显微组织图像.而为数不多的基于真实组织照片的GAN工作也是在大量数据积累的基础上才得以实现的,例如Cao等[86]针对单一的Ti-6Al-4V合金体系进行3D打印工艺分析,在组织形式相对固定的体系环境下,该工作依然积累了450张真实组织照片,并通过数据增强与图像切割,最终获得了一个多达10.8万张子图的数据库,才完成了GAN的训练,而且该工作只建立了成分、工艺与显微组织间的预测模型,并未涉及对后续性能的预测.可想而知,面对组织状态更为多变的复杂合金体系,再引入性能预测功能,GAN训练的数据需求是会更为夸张的.实质上,早在2018年,美国西北大学Ankit Agrawal团队的Yang等[87]就针对利用GAN建立“成分-工艺-真实组织图像-性能”全链条模型进行了探索,并认为这一GAN框架的训练数据需求量至少是5000个显微组织图像样本,这一工作可以给予后续研究人员在人工智能方法选择上提供极大的指导. ...
Generative adversarial networks-based synthetic microstructures for data-driven materials design
1
2022
... 当论及图像生成领域,应最先被提及的自然是应用最为广泛的GAN[81].值得注意的是,GAN虽然在合金组织分析研究中被广泛提及,但其并不是本文主要推荐使用的策略.GAN的本质是训练得到一个图像生成器和一个图像判别器,图像生成器可以将一个向量转化成矩阵式的图像,而图像鉴别器可以将矩阵式的图像转化成一个向量以鉴别其真伪.试想,当显微组织图像可以转化成一个对应的特征向量时,自然就可以通过传统机器学习方式建立起成分、工艺信息向量与显微组织特征向量间的关系模型,从而通过成分、工艺信息预测出对应的显微组织特征向量,进而再使用图像生成器将该向量转化为矩阵式的图像,呈现出显微组织图.更重要的是GAN是一个无监督学习网络,不存在语义分割中所涉及的“标签”问题.因此GAN在基于图像的合金设计领域中也有诸多应用,例如Qian等[82]使用GAN进行力学超材料设计,让其寻找可使材料性能变得更佳的超材料结构图样.而使用GAN进行纯图像生成的研究工作则更多[83~85],例如Long等[84]使用GAN助力稳定晶体结构的搜索,Yang[85]使用GAN生成晶粒长大、枝晶生长等组织图像,为图像识别工作提供更多训练数据等.但可以发现,虽然理论上GAN可以实现“成分-工艺-真实组织图像-性能”的全链条模型构建,但遗憾的是,真正实现这一理想效果的示范案例很少,其本质原因还是材料学领域的小样本限制问题.基于前文对于诸多图像相关案例的论述不难发现,无论是图像识别、多模态处理,还是图像生成,其处理过程的数学本质是相通的,都是先将图像这一矩阵数据转换成更易处理的小维度向量数据,然后再做后续计算.图像识别是先将显微组织图片转换成特征向量,再将该特征向量解码成一个只包含核心信息的相分布图;多模态处理则根本不用将特征向量解码成图片,而是直接用其去预测性能数值;而基于GAN的图像生成则是要依据特征向量再构造出一个与原始组织图片相似的“真实”全信息图像,这3者间的难度差异是不可同日而语的(图8).在合金设计领域小样本实验数据的环境下,GAN很难被训练稳定,并实现合理的真实组织图像生成与预测,这也是为何目前合金设计领域多数GAN相关的研究是使用相场等模拟手段提供数据来源,而非用实验获得的真实显微组织图像.而为数不多的基于真实组织照片的GAN工作也是在大量数据积累的基础上才得以实现的,例如Cao等[86]针对单一的Ti-6Al-4V合金体系进行3D打印工艺分析,在组织形式相对固定的体系环境下,该工作依然积累了450张真实组织照片,并通过数据增强与图像切割,最终获得了一个多达10.8万张子图的数据库,才完成了GAN的训练,而且该工作只建立了成分、工艺与显微组织间的预测模型,并未涉及对后续性能的预测.可想而知,面对组织状态更为多变的复杂合金体系,再引入性能预测功能,GAN训练的数据需求是会更为夸张的.实质上,早在2018年,美国西北大学Ankit Agrawal团队的Yang等[87]就针对利用GAN建立“成分-工艺-真实组织图像-性能”全链条模型进行了探索,并认为这一GAN框架的训练数据需求量至少是5000个显微组织图像样本,这一工作可以给予后续研究人员在人工智能方法选择上提供极大的指导. ...
Inverse design of crystal structures for multicomponent systems
1
2022
... 当论及图像生成领域,应最先被提及的自然是应用最为广泛的GAN[81].值得注意的是,GAN虽然在合金组织分析研究中被广泛提及,但其并不是本文主要推荐使用的策略.GAN的本质是训练得到一个图像生成器和一个图像判别器,图像生成器可以将一个向量转化成矩阵式的图像,而图像鉴别器可以将矩阵式的图像转化成一个向量以鉴别其真伪.试想,当显微组织图像可以转化成一个对应的特征向量时,自然就可以通过传统机器学习方式建立起成分、工艺信息向量与显微组织特征向量间的关系模型,从而通过成分、工艺信息预测出对应的显微组织特征向量,进而再使用图像生成器将该向量转化为矩阵式的图像,呈现出显微组织图.更重要的是GAN是一个无监督学习网络,不存在语义分割中所涉及的“标签”问题.因此GAN在基于图像的合金设计领域中也有诸多应用,例如Qian等[82]使用GAN进行力学超材料设计,让其寻找可使材料性能变得更佳的超材料结构图样.而使用GAN进行纯图像生成的研究工作则更多[83~85],例如Long等[84]使用GAN助力稳定晶体结构的搜索,Yang[85]使用GAN生成晶粒长大、枝晶生长等组织图像,为图像识别工作提供更多训练数据等.但可以发现,虽然理论上GAN可以实现“成分-工艺-真实组织图像-性能”的全链条模型构建,但遗憾的是,真正实现这一理想效果的示范案例很少,其本质原因还是材料学领域的小样本限制问题.基于前文对于诸多图像相关案例的论述不难发现,无论是图像识别、多模态处理,还是图像生成,其处理过程的数学本质是相通的,都是先将图像这一矩阵数据转换成更易处理的小维度向量数据,然后再做后续计算.图像识别是先将显微组织图片转换成特征向量,再将该特征向量解码成一个只包含核心信息的相分布图;多模态处理则根本不用将特征向量解码成图片,而是直接用其去预测性能数值;而基于GAN的图像生成则是要依据特征向量再构造出一个与原始组织图片相似的“真实”全信息图像,这3者间的难度差异是不可同日而语的(图8).在合金设计领域小样本实验数据的环境下,GAN很难被训练稳定,并实现合理的真实组织图像生成与预测,这也是为何目前合金设计领域多数GAN相关的研究是使用相场等模拟手段提供数据来源,而非用实验获得的真实显微组织图像.而为数不多的基于真实组织照片的GAN工作也是在大量数据积累的基础上才得以实现的,例如Cao等[86]针对单一的Ti-6Al-4V合金体系进行3D打印工艺分析,在组织形式相对固定的体系环境下,该工作依然积累了450张真实组织照片,并通过数据增强与图像切割,最终获得了一个多达10.8万张子图的数据库,才完成了GAN的训练,而且该工作只建立了成分、工艺与显微组织间的预测模型,并未涉及对后续性能的预测.可想而知,面对组织状态更为多变的复杂合金体系,再引入性能预测功能,GAN训练的数据需求是会更为夸张的.实质上,早在2018年,美国西北大学Ankit Agrawal团队的Yang等[87]就针对利用GAN建立“成分-工艺-真实组织图像-性能”全链条模型进行了探索,并认为这一GAN框架的训练数据需求量至少是5000个显微组织图像样本,这一工作可以给予后续研究人员在人工智能方法选择上提供极大的指导. ...
A machine learning-based approach for materials microstructure analysis and prediction
2
2020
... 当论及图像生成领域,应最先被提及的自然是应用最为广泛的GAN[81].值得注意的是,GAN虽然在合金组织分析研究中被广泛提及,但其并不是本文主要推荐使用的策略.GAN的本质是训练得到一个图像生成器和一个图像判别器,图像生成器可以将一个向量转化成矩阵式的图像,而图像鉴别器可以将矩阵式的图像转化成一个向量以鉴别其真伪.试想,当显微组织图像可以转化成一个对应的特征向量时,自然就可以通过传统机器学习方式建立起成分、工艺信息向量与显微组织特征向量间的关系模型,从而通过成分、工艺信息预测出对应的显微组织特征向量,进而再使用图像生成器将该向量转化为矩阵式的图像,呈现出显微组织图.更重要的是GAN是一个无监督学习网络,不存在语义分割中所涉及的“标签”问题.因此GAN在基于图像的合金设计领域中也有诸多应用,例如Qian等[82]使用GAN进行力学超材料设计,让其寻找可使材料性能变得更佳的超材料结构图样.而使用GAN进行纯图像生成的研究工作则更多[83~85],例如Long等[84]使用GAN助力稳定晶体结构的搜索,Yang[85]使用GAN生成晶粒长大、枝晶生长等组织图像,为图像识别工作提供更多训练数据等.但可以发现,虽然理论上GAN可以实现“成分-工艺-真实组织图像-性能”的全链条模型构建,但遗憾的是,真正实现这一理想效果的示范案例很少,其本质原因还是材料学领域的小样本限制问题.基于前文对于诸多图像相关案例的论述不难发现,无论是图像识别、多模态处理,还是图像生成,其处理过程的数学本质是相通的,都是先将图像这一矩阵数据转换成更易处理的小维度向量数据,然后再做后续计算.图像识别是先将显微组织图片转换成特征向量,再将该特征向量解码成一个只包含核心信息的相分布图;多模态处理则根本不用将特征向量解码成图片,而是直接用其去预测性能数值;而基于GAN的图像生成则是要依据特征向量再构造出一个与原始组织图片相似的“真实”全信息图像,这3者间的难度差异是不可同日而语的(图8).在合金设计领域小样本实验数据的环境下,GAN很难被训练稳定,并实现合理的真实组织图像生成与预测,这也是为何目前合金设计领域多数GAN相关的研究是使用相场等模拟手段提供数据来源,而非用实验获得的真实显微组织图像.而为数不多的基于真实组织照片的GAN工作也是在大量数据积累的基础上才得以实现的,例如Cao等[86]针对单一的Ti-6Al-4V合金体系进行3D打印工艺分析,在组织形式相对固定的体系环境下,该工作依然积累了450张真实组织照片,并通过数据增强与图像切割,最终获得了一个多达10.8万张子图的数据库,才完成了GAN的训练,而且该工作只建立了成分、工艺与显微组织间的预测模型,并未涉及对后续性能的预测.可想而知,面对组织状态更为多变的复杂合金体系,再引入性能预测功能,GAN训练的数据需求是会更为夸张的.实质上,早在2018年,美国西北大学Ankit Agrawal团队的Yang等[87]就针对利用GAN建立“成分-工艺-真实组织图像-性能”全链条模型进行了探索,并认为这一GAN框架的训练数据需求量至少是5000个显微组织图像样本,这一工作可以给予后续研究人员在人工智能方法选择上提供极大的指导. ...
... [85]使用GAN生成晶粒长大、枝晶生长等组织图像,为图像识别工作提供更多训练数据等.但可以发现,虽然理论上GAN可以实现“成分-工艺-真实组织图像-性能”的全链条模型构建,但遗憾的是,真正实现这一理想效果的示范案例很少,其本质原因还是材料学领域的小样本限制问题.基于前文对于诸多图像相关案例的论述不难发现,无论是图像识别、多模态处理,还是图像生成,其处理过程的数学本质是相通的,都是先将图像这一矩阵数据转换成更易处理的小维度向量数据,然后再做后续计算.图像识别是先将显微组织图片转换成特征向量,再将该特征向量解码成一个只包含核心信息的相分布图;多模态处理则根本不用将特征向量解码成图片,而是直接用其去预测性能数值;而基于GAN的图像生成则是要依据特征向量再构造出一个与原始组织图片相似的“真实”全信息图像,这3者间的难度差异是不可同日而语的(图8).在合金设计领域小样本实验数据的环境下,GAN很难被训练稳定,并实现合理的真实组织图像生成与预测,这也是为何目前合金设计领域多数GAN相关的研究是使用相场等模拟手段提供数据来源,而非用实验获得的真实显微组织图像.而为数不多的基于真实组织照片的GAN工作也是在大量数据积累的基础上才得以实现的,例如Cao等[86]针对单一的Ti-6Al-4V合金体系进行3D打印工艺分析,在组织形式相对固定的体系环境下,该工作依然积累了450张真实组织照片,并通过数据增强与图像切割,最终获得了一个多达10.8万张子图的数据库,才完成了GAN的训练,而且该工作只建立了成分、工艺与显微组织间的预测模型,并未涉及对后续性能的预测.可想而知,面对组织状态更为多变的复杂合金体系,再引入性能预测功能,GAN训练的数据需求是会更为夸张的.实质上,早在2018年,美国西北大学Ankit Agrawal团队的Yang等[87]就针对利用GAN建立“成分-工艺-真实组织图像-性能”全链条模型进行了探索,并认为这一GAN框架的训练数据需求量至少是5000个显微组织图像样本,这一工作可以给予后续研究人员在人工智能方法选择上提供极大的指导. ...
A machine learning method to quantitatively predict alpha phase morphology in additively manufactured Ti-6Al-4V
1
2023
... 当论及图像生成领域,应最先被提及的自然是应用最为广泛的GAN[81].值得注意的是,GAN虽然在合金组织分析研究中被广泛提及,但其并不是本文主要推荐使用的策略.GAN的本质是训练得到一个图像生成器和一个图像判别器,图像生成器可以将一个向量转化成矩阵式的图像,而图像鉴别器可以将矩阵式的图像转化成一个向量以鉴别其真伪.试想,当显微组织图像可以转化成一个对应的特征向量时,自然就可以通过传统机器学习方式建立起成分、工艺信息向量与显微组织特征向量间的关系模型,从而通过成分、工艺信息预测出对应的显微组织特征向量,进而再使用图像生成器将该向量转化为矩阵式的图像,呈现出显微组织图.更重要的是GAN是一个无监督学习网络,不存在语义分割中所涉及的“标签”问题.因此GAN在基于图像的合金设计领域中也有诸多应用,例如Qian等[82]使用GAN进行力学超材料设计,让其寻找可使材料性能变得更佳的超材料结构图样.而使用GAN进行纯图像生成的研究工作则更多[83~85],例如Long等[84]使用GAN助力稳定晶体结构的搜索,Yang[85]使用GAN生成晶粒长大、枝晶生长等组织图像,为图像识别工作提供更多训练数据等.但可以发现,虽然理论上GAN可以实现“成分-工艺-真实组织图像-性能”的全链条模型构建,但遗憾的是,真正实现这一理想效果的示范案例很少,其本质原因还是材料学领域的小样本限制问题.基于前文对于诸多图像相关案例的论述不难发现,无论是图像识别、多模态处理,还是图像生成,其处理过程的数学本质是相通的,都是先将图像这一矩阵数据转换成更易处理的小维度向量数据,然后再做后续计算.图像识别是先将显微组织图片转换成特征向量,再将该特征向量解码成一个只包含核心信息的相分布图;多模态处理则根本不用将特征向量解码成图片,而是直接用其去预测性能数值;而基于GAN的图像生成则是要依据特征向量再构造出一个与原始组织图片相似的“真实”全信息图像,这3者间的难度差异是不可同日而语的(图8).在合金设计领域小样本实验数据的环境下,GAN很难被训练稳定,并实现合理的真实组织图像生成与预测,这也是为何目前合金设计领域多数GAN相关的研究是使用相场等模拟手段提供数据来源,而非用实验获得的真实显微组织图像.而为数不多的基于真实组织照片的GAN工作也是在大量数据积累的基础上才得以实现的,例如Cao等[86]针对单一的Ti-6Al-4V合金体系进行3D打印工艺分析,在组织形式相对固定的体系环境下,该工作依然积累了450张真实组织照片,并通过数据增强与图像切割,最终获得了一个多达10.8万张子图的数据库,才完成了GAN的训练,而且该工作只建立了成分、工艺与显微组织间的预测模型,并未涉及对后续性能的预测.可想而知,面对组织状态更为多变的复杂合金体系,再引入性能预测功能,GAN训练的数据需求是会更为夸张的.实质上,早在2018年,美国西北大学Ankit Agrawal团队的Yang等[87]就针对利用GAN建立“成分-工艺-真实组织图像-性能”全链条模型进行了探索,并认为这一GAN框架的训练数据需求量至少是5000个显微组织图像样本,这一工作可以给予后续研究人员在人工智能方法选择上提供极大的指导. ...
Microstructural materials design via deep adversarial learning methodology
4
2018
... 当论及图像生成领域,应最先被提及的自然是应用最为广泛的GAN[81].值得注意的是,GAN虽然在合金组织分析研究中被广泛提及,但其并不是本文主要推荐使用的策略.GAN的本质是训练得到一个图像生成器和一个图像判别器,图像生成器可以将一个向量转化成矩阵式的图像,而图像鉴别器可以将矩阵式的图像转化成一个向量以鉴别其真伪.试想,当显微组织图像可以转化成一个对应的特征向量时,自然就可以通过传统机器学习方式建立起成分、工艺信息向量与显微组织特征向量间的关系模型,从而通过成分、工艺信息预测出对应的显微组织特征向量,进而再使用图像生成器将该向量转化为矩阵式的图像,呈现出显微组织图.更重要的是GAN是一个无监督学习网络,不存在语义分割中所涉及的“标签”问题.因此GAN在基于图像的合金设计领域中也有诸多应用,例如Qian等[82]使用GAN进行力学超材料设计,让其寻找可使材料性能变得更佳的超材料结构图样.而使用GAN进行纯图像生成的研究工作则更多[83~85],例如Long等[84]使用GAN助力稳定晶体结构的搜索,Yang[85]使用GAN生成晶粒长大、枝晶生长等组织图像,为图像识别工作提供更多训练数据等.但可以发现,虽然理论上GAN可以实现“成分-工艺-真实组织图像-性能”的全链条模型构建,但遗憾的是,真正实现这一理想效果的示范案例很少,其本质原因还是材料学领域的小样本限制问题.基于前文对于诸多图像相关案例的论述不难发现,无论是图像识别、多模态处理,还是图像生成,其处理过程的数学本质是相通的,都是先将图像这一矩阵数据转换成更易处理的小维度向量数据,然后再做后续计算.图像识别是先将显微组织图片转换成特征向量,再将该特征向量解码成一个只包含核心信息的相分布图;多模态处理则根本不用将特征向量解码成图片,而是直接用其去预测性能数值;而基于GAN的图像生成则是要依据特征向量再构造出一个与原始组织图片相似的“真实”全信息图像,这3者间的难度差异是不可同日而语的(图8).在合金设计领域小样本实验数据的环境下,GAN很难被训练稳定,并实现合理的真实组织图像生成与预测,这也是为何目前合金设计领域多数GAN相关的研究是使用相场等模拟手段提供数据来源,而非用实验获得的真实显微组织图像.而为数不多的基于真实组织照片的GAN工作也是在大量数据积累的基础上才得以实现的,例如Cao等[86]针对单一的Ti-6Al-4V合金体系进行3D打印工艺分析,在组织形式相对固定的体系环境下,该工作依然积累了450张真实组织照片,并通过数据增强与图像切割,最终获得了一个多达10.8万张子图的数据库,才完成了GAN的训练,而且该工作只建立了成分、工艺与显微组织间的预测模型,并未涉及对后续性能的预测.可想而知,面对组织状态更为多变的复杂合金体系,再引入性能预测功能,GAN训练的数据需求是会更为夸张的.实质上,早在2018年,美国西北大学Ankit Agrawal团队的Yang等[87]就针对利用GAN建立“成分-工艺-真实组织图像-性能”全链条模型进行了探索,并认为这一GAN框架的训练数据需求量至少是5000个显微组织图像样本,这一工作可以给予后续研究人员在人工智能方法选择上提供极大的指导. ...
... 如果上述例子有助于研究者理解GAN的不稳定性及其在材料学小数据环境下应用的局限性,那本文后续推荐另一种算法替代GAN的原因也就很清晰了,这种算法就是变分自编码器(variational autoencoder,VAE)[88,89],其也是AI4Sci领域中受到广泛关注的算法之一[6].与GAN的区别是,VAE是自监督学习算法.在小样本环境下,VAE不容易像GAN一样过度发散而导致一些图像无法生成或生成的图像不合理的问题(图9[73,76,87,90]).当然,数据量不足会导致VAE生成的图像模糊.但在分析组织与性能关系时,一个模糊的组织图片也基本不影响使用,可以权当拍摄组织照片时焦距未能调好,其总比一张错误的组织照片要有价值.因此,VAE在基于真实组织图像的合金设计中已有成功的案例.Pei等[89]通过对钢铁材料组织的自监督学习建立了可进行钢铁材料组织生成的VAE模型,该模型可以为开发更优力学性能的钢铁材料提供定性的搜索方向指导.虽然该工作没能给出可进行精准定量化合金设计的模型,但其对于VAE算法在合金设计方向上的应用具有里程碑式的意义.而Ma等[90]则以双相钢为研究对象,提供了一个更具参考价值的合金设计案例,其使用22个合金样本获得组织照片,照片经裁剪后为700余条图像样本,建立了双相钢下的VAE模型,并且真正实现了显微组织图像与成分、工艺、性能间的全链条预测,并且基于该全链条预测模型定量化设计了多种高性能双相钢,实验验证结果良好.模型所提方案无论在显微组织图像还是最终力学性能的预测结果方面都与实际制备出的钢种吻合,充分证明了该方法的有效性,而且22个合金获得的700余条组织图片样本需求显然比GAN所需的5000,甚至上万图片样本要更为人性化.当然,虽然VAE算法在双相钢中实现了“成分-工艺-组织图像-性能”全链条预测与指导合金设计的理想模式,但其稳定性如何,在预测的组织图像信息指导下模型的域外扩展能力是否得到了切实的改善,是否打破了准确性与域外扩展能力的互斥关系,以及在更多合金体系下VAE算法是否依然适用,诸多问题都尚待探索与解答,基于“成分-工艺-组织图像-性能”全链条预测理念的合金设计方法刚刚迈出历史性的第一步,仍然任重而道远. ...
... ,
87,
90]
Mechanism correlation and data requirements of various image algorithms<sup>[<xref ref-type="bibr" rid="R73">73</xref>,<xref ref-type="bibr" rid="R76">76</xref>,<xref ref-type="bibr" rid="R87">87</xref>,<xref ref-type="bibr" rid="R90">90</xref>]</sup>Fig.9![]() <strong>4</strong> 物理机制指导人工智能
<strong>4</strong> 物理机制指导人工智能由以上论述可见,本文一直在强调物理模型与机制对人工智能的“弱约束”作用及其重要性,这也是物理冶金原理指导人工智能最核心的理论本质.而前文所列举的诸多案例引入这种“弱约束”作用的方式并非直接将模型或机制本身融入人工智能算法,而是以相对间接的数据输入形式加入一种隐性的“规劝”.例如,在数值型数据方面将热力学模型以能量数据的形式引入统计学习算法、在图像数据方面将晶体塑性本构方程以应力云图的形式引入深度学习网络.然而这种“规劝”式的处理方式也存在局限性,例如其会受到引入数据准确性的影响、引入的物理指导信息过多或维度过大也会导致过拟合等.因此,如果可以将物理机制以更直接的方式加入到人工智能的构架中,则可以大幅避免通过数据间接引入造成的上述诸多问题.因此,本小节专门针对“非数据引入”型的物理冶金原理指导人工智能方法进行总结分析. ...
... ,
87,
90]
Fig.9![]() <strong>4</strong> 物理机制指导人工智能
<strong>4</strong> 物理机制指导人工智能由以上论述可见,本文一直在强调物理模型与机制对人工智能的“弱约束”作用及其重要性,这也是物理冶金原理指导人工智能最核心的理论本质.而前文所列举的诸多案例引入这种“弱约束”作用的方式并非直接将模型或机制本身融入人工智能算法,而是以相对间接的数据输入形式加入一种隐性的“规劝”.例如,在数值型数据方面将热力学模型以能量数据的形式引入统计学习算法、在图像数据方面将晶体塑性本构方程以应力云图的形式引入深度学习网络.然而这种“规劝”式的处理方式也存在局限性,例如其会受到引入数据准确性的影响、引入的物理指导信息过多或维度过大也会导致过拟合等.因此,如果可以将物理机制以更直接的方式加入到人工智能的构架中,则可以大幅避免通过数据间接引入造成的上述诸多问题.因此,本小节专门针对“非数据引入”型的物理冶金原理指导人工智能方法进行总结分析. ...
Auto-encoding variational Bayes
1
... 如果上述例子有助于研究者理解GAN的不稳定性及其在材料学小数据环境下应用的局限性,那本文后续推荐另一种算法替代GAN的原因也就很清晰了,这种算法就是变分自编码器(variational autoencoder,VAE)[88,89],其也是AI4Sci领域中受到广泛关注的算法之一[6].与GAN的区别是,VAE是自监督学习算法.在小样本环境下,VAE不容易像GAN一样过度发散而导致一些图像无法生成或生成的图像不合理的问题(图9[73,76,87,90]).当然,数据量不足会导致VAE生成的图像模糊.但在分析组织与性能关系时,一个模糊的组织图片也基本不影响使用,可以权当拍摄组织照片时焦距未能调好,其总比一张错误的组织照片要有价值.因此,VAE在基于真实组织图像的合金设计中已有成功的案例.Pei等[89]通过对钢铁材料组织的自监督学习建立了可进行钢铁材料组织生成的VAE模型,该模型可以为开发更优力学性能的钢铁材料提供定性的搜索方向指导.虽然该工作没能给出可进行精准定量化合金设计的模型,但其对于VAE算法在合金设计方向上的应用具有里程碑式的意义.而Ma等[90]则以双相钢为研究对象,提供了一个更具参考价值的合金设计案例,其使用22个合金样本获得组织照片,照片经裁剪后为700余条图像样本,建立了双相钢下的VAE模型,并且真正实现了显微组织图像与成分、工艺、性能间的全链条预测,并且基于该全链条预测模型定量化设计了多种高性能双相钢,实验验证结果良好.模型所提方案无论在显微组织图像还是最终力学性能的预测结果方面都与实际制备出的钢种吻合,充分证明了该方法的有效性,而且22个合金获得的700余条组织图片样本需求显然比GAN所需的5000,甚至上万图片样本要更为人性化.当然,虽然VAE算法在双相钢中实现了“成分-工艺-组织图像-性能”全链条预测与指导合金设计的理想模式,但其稳定性如何,在预测的组织图像信息指导下模型的域外扩展能力是否得到了切实的改善,是否打破了准确性与域外扩展能力的互斥关系,以及在更多合金体系下VAE算法是否依然适用,诸多问题都尚待探索与解答,基于“成分-工艺-组织图像-性能”全链条预测理念的合金设计方法刚刚迈出历史性的第一步,仍然任重而道远. ...
Machine-learning microstructure for inverse material design
2
2021
... 如果上述例子有助于研究者理解GAN的不稳定性及其在材料学小数据环境下应用的局限性,那本文后续推荐另一种算法替代GAN的原因也就很清晰了,这种算法就是变分自编码器(variational autoencoder,VAE)[88,89],其也是AI4Sci领域中受到广泛关注的算法之一[6].与GAN的区别是,VAE是自监督学习算法.在小样本环境下,VAE不容易像GAN一样过度发散而导致一些图像无法生成或生成的图像不合理的问题(图9[73,76,87,90]).当然,数据量不足会导致VAE生成的图像模糊.但在分析组织与性能关系时,一个模糊的组织图片也基本不影响使用,可以权当拍摄组织照片时焦距未能调好,其总比一张错误的组织照片要有价值.因此,VAE在基于真实组织图像的合金设计中已有成功的案例.Pei等[89]通过对钢铁材料组织的自监督学习建立了可进行钢铁材料组织生成的VAE模型,该模型可以为开发更优力学性能的钢铁材料提供定性的搜索方向指导.虽然该工作没能给出可进行精准定量化合金设计的模型,但其对于VAE算法在合金设计方向上的应用具有里程碑式的意义.而Ma等[90]则以双相钢为研究对象,提供了一个更具参考价值的合金设计案例,其使用22个合金样本获得组织照片,照片经裁剪后为700余条图像样本,建立了双相钢下的VAE模型,并且真正实现了显微组织图像与成分、工艺、性能间的全链条预测,并且基于该全链条预测模型定量化设计了多种高性能双相钢,实验验证结果良好.模型所提方案无论在显微组织图像还是最终力学性能的预测结果方面都与实际制备出的钢种吻合,充分证明了该方法的有效性,而且22个合金获得的700余条组织图片样本需求显然比GAN所需的5000,甚至上万图片样本要更为人性化.当然,虽然VAE算法在双相钢中实现了“成分-工艺-组织图像-性能”全链条预测与指导合金设计的理想模式,但其稳定性如何,在预测的组织图像信息指导下模型的域外扩展能力是否得到了切实的改善,是否打破了准确性与域外扩展能力的互斥关系,以及在更多合金体系下VAE算法是否依然适用,诸多问题都尚待探索与解答,基于“成分-工艺-组织图像-性能”全链条预测理念的合金设计方法刚刚迈出历史性的第一步,仍然任重而道远. ...
... [89]通过对钢铁材料组织的自监督学习建立了可进行钢铁材料组织生成的VAE模型,该模型可以为开发更优力学性能的钢铁材料提供定性的搜索方向指导.虽然该工作没能给出可进行精准定量化合金设计的模型,但其对于VAE算法在合金设计方向上的应用具有里程碑式的意义.而Ma等[90]则以双相钢为研究对象,提供了一个更具参考价值的合金设计案例,其使用22个合金样本获得组织照片,照片经裁剪后为700余条图像样本,建立了双相钢下的VAE模型,并且真正实现了显微组织图像与成分、工艺、性能间的全链条预测,并且基于该全链条预测模型定量化设计了多种高性能双相钢,实验验证结果良好.模型所提方案无论在显微组织图像还是最终力学性能的预测结果方面都与实际制备出的钢种吻合,充分证明了该方法的有效性,而且22个合金获得的700余条组织图片样本需求显然比GAN所需的5000,甚至上万图片样本要更为人性化.当然,虽然VAE算法在双相钢中实现了“成分-工艺-组织图像-性能”全链条预测与指导合金设计的理想模式,但其稳定性如何,在预测的组织图像信息指导下模型的域外扩展能力是否得到了切实的改善,是否打破了准确性与域外扩展能力的互斥关系,以及在更多合金体系下VAE算法是否依然适用,诸多问题都尚待探索与解答,基于“成分-工艺-组织图像-性能”全链条预测理念的合金设计方法刚刚迈出历史性的第一步,仍然任重而道远. ...
Creating a microstructure latent space with rich material information for multiphase alloy design
4
2024
... 如果上述例子有助于研究者理解GAN的不稳定性及其在材料学小数据环境下应用的局限性,那本文后续推荐另一种算法替代GAN的原因也就很清晰了,这种算法就是变分自编码器(variational autoencoder,VAE)[88,89],其也是AI4Sci领域中受到广泛关注的算法之一[6].与GAN的区别是,VAE是自监督学习算法.在小样本环境下,VAE不容易像GAN一样过度发散而导致一些图像无法生成或生成的图像不合理的问题(图9[73,76,87,90]).当然,数据量不足会导致VAE生成的图像模糊.但在分析组织与性能关系时,一个模糊的组织图片也基本不影响使用,可以权当拍摄组织照片时焦距未能调好,其总比一张错误的组织照片要有价值.因此,VAE在基于真实组织图像的合金设计中已有成功的案例.Pei等[89]通过对钢铁材料组织的自监督学习建立了可进行钢铁材料组织生成的VAE模型,该模型可以为开发更优力学性能的钢铁材料提供定性的搜索方向指导.虽然该工作没能给出可进行精准定量化合金设计的模型,但其对于VAE算法在合金设计方向上的应用具有里程碑式的意义.而Ma等[90]则以双相钢为研究对象,提供了一个更具参考价值的合金设计案例,其使用22个合金样本获得组织照片,照片经裁剪后为700余条图像样本,建立了双相钢下的VAE模型,并且真正实现了显微组织图像与成分、工艺、性能间的全链条预测,并且基于该全链条预测模型定量化设计了多种高性能双相钢,实验验证结果良好.模型所提方案无论在显微组织图像还是最终力学性能的预测结果方面都与实际制备出的钢种吻合,充分证明了该方法的有效性,而且22个合金获得的700余条组织图片样本需求显然比GAN所需的5000,甚至上万图片样本要更为人性化.当然,虽然VAE算法在双相钢中实现了“成分-工艺-组织图像-性能”全链条预测与指导合金设计的理想模式,但其稳定性如何,在预测的组织图像信息指导下模型的域外扩展能力是否得到了切实的改善,是否打破了准确性与域外扩展能力的互斥关系,以及在更多合金体系下VAE算法是否依然适用,诸多问题都尚待探索与解答,基于“成分-工艺-组织图像-性能”全链条预测理念的合金设计方法刚刚迈出历史性的第一步,仍然任重而道远. ...
... [90]则以双相钢为研究对象,提供了一个更具参考价值的合金设计案例,其使用22个合金样本获得组织照片,照片经裁剪后为700余条图像样本,建立了双相钢下的VAE模型,并且真正实现了显微组织图像与成分、工艺、性能间的全链条预测,并且基于该全链条预测模型定量化设计了多种高性能双相钢,实验验证结果良好.模型所提方案无论在显微组织图像还是最终力学性能的预测结果方面都与实际制备出的钢种吻合,充分证明了该方法的有效性,而且22个合金获得的700余条组织图片样本需求显然比GAN所需的5000,甚至上万图片样本要更为人性化.当然,虽然VAE算法在双相钢中实现了“成分-工艺-组织图像-性能”全链条预测与指导合金设计的理想模式,但其稳定性如何,在预测的组织图像信息指导下模型的域外扩展能力是否得到了切实的改善,是否打破了准确性与域外扩展能力的互斥关系,以及在更多合金体系下VAE算法是否依然适用,诸多问题都尚待探索与解答,基于“成分-工艺-组织图像-性能”全链条预测理念的合金设计方法刚刚迈出历史性的第一步,仍然任重而道远. ...
... ,
90]
Mechanism correlation and data requirements of various image algorithms<sup>[<xref ref-type="bibr" rid="R73">73</xref>,<xref ref-type="bibr" rid="R76">76</xref>,<xref ref-type="bibr" rid="R87">87</xref>,<xref ref-type="bibr" rid="R90">90</xref>]</sup>Fig.9![]() <strong>4</strong> 物理机制指导人工智能
<strong>4</strong> 物理机制指导人工智能由以上论述可见,本文一直在强调物理模型与机制对人工智能的“弱约束”作用及其重要性,这也是物理冶金原理指导人工智能最核心的理论本质.而前文所列举的诸多案例引入这种“弱约束”作用的方式并非直接将模型或机制本身融入人工智能算法,而是以相对间接的数据输入形式加入一种隐性的“规劝”.例如,在数值型数据方面将热力学模型以能量数据的形式引入统计学习算法、在图像数据方面将晶体塑性本构方程以应力云图的形式引入深度学习网络.然而这种“规劝”式的处理方式也存在局限性,例如其会受到引入数据准确性的影响、引入的物理指导信息过多或维度过大也会导致过拟合等.因此,如果可以将物理机制以更直接的方式加入到人工智能的构架中,则可以大幅避免通过数据间接引入造成的上述诸多问题.因此,本小节专门针对“非数据引入”型的物理冶金原理指导人工智能方法进行总结分析. ...
... ,
90]
Fig.9![]() <strong>4</strong> 物理机制指导人工智能
<strong>4</strong> 物理机制指导人工智能由以上论述可见,本文一直在强调物理模型与机制对人工智能的“弱约束”作用及其重要性,这也是物理冶金原理指导人工智能最核心的理论本质.而前文所列举的诸多案例引入这种“弱约束”作用的方式并非直接将模型或机制本身融入人工智能算法,而是以相对间接的数据输入形式加入一种隐性的“规劝”.例如,在数值型数据方面将热力学模型以能量数据的形式引入统计学习算法、在图像数据方面将晶体塑性本构方程以应力云图的形式引入深度学习网络.然而这种“规劝”式的处理方式也存在局限性,例如其会受到引入数据准确性的影响、引入的物理指导信息过多或维度过大也会导致过拟合等.因此,如果可以将物理机制以更直接的方式加入到人工智能的构架中,则可以大幅避免通过数据间接引入造成的上述诸多问题.因此,本小节专门针对“非数据引入”型的物理冶金原理指导人工智能方法进行总结分析. ...
Enhancing materials property prediction by leveraging computational and experimental data using deep transfer learning
1
2019
... 迁移学习技术作为图像识别领域非常经典的技术手段,其在材料学领域的图像识别方面也早有应用.但真正将迁移学习技术与物理机制相关联,进行机制数据间的迁移最早始于2019年,美国西北大学Ankit Agrawal研究团队的Jha等[91]将其应用于加速第一性原理计算,并提出了该算法可通过机制间的关联关系,大幅缩减人工智能面对新问题时训练所需数据量的观点.从依托GAN算法的合金设计,到基于物理机制的迁移学习技术,Ankit Agrawal研究团队作为数据驱动材料基因领域的代表性团队,其所使用的人工智能技术一直具有极强的前瞻性.同一时间,日本统计数理研究所的Yamada等[92]也发表了迁移学习在有机和无机化学领域的应用,证明了其在减少人工智能训练数据需求量方面的强大能力.虽然上述迁移学习工作已得到诸多材料学者的广泛认可,但实质上在上述研究结果发表的3年后,迁移学习技术才被合金设计领域关注并形成了第一个代表性的示范案例:低合金钢的疲劳性能设计[93].众所周知,疲劳性能的测试需要消耗大量时间与资金成本,因此金属的疲劳一直是一个数据稀缺的领域.Wei等[93]将疲劳与常规力学性能间具有强关联性这一力学领域广泛认可的基本物理机制引入至人工神经网络框架,实现了使用常规拉伸数据部分取代疲劳数据的效果,其最终仅使用30余条疲劳数据就建立起可以进行合理合金设计的疲劳强度预测模型,设计结果与实验验证结果吻合良好,新设计的合金实现了疲劳强度提升50 MPa的效果.30余条数据建立一个人工智能模型而不出现过拟合本身就是一个很令人惊讶的夸张效果,且还能保证对新数据进行稳定的扩展预测,并指导合理的合金设计,实属罕见.而形成该效果的本质原因是该模型的框架中包含了“常规力学性能-疲劳性能”这一物理机制的“弱约束”,因此常规拉伸性能预测的源模型为迁移后的疲劳性能预测模型提供了大量可直接借鉴的经验,大幅降低了模型在分析该问题时面临的困难.该范例充分证明了将物理冶金机制引入人工智能可使其突破人工智能本身算法的局限性,获得准确性与扩展能力的同时提升. ...
Predicting materials properties with little data using shotgun transfer learning
1
2019
... 迁移学习技术作为图像识别领域非常经典的技术手段,其在材料学领域的图像识别方面也早有应用.但真正将迁移学习技术与物理机制相关联,进行机制数据间的迁移最早始于2019年,美国西北大学Ankit Agrawal研究团队的Jha等[91]将其应用于加速第一性原理计算,并提出了该算法可通过机制间的关联关系,大幅缩减人工智能面对新问题时训练所需数据量的观点.从依托GAN算法的合金设计,到基于物理机制的迁移学习技术,Ankit Agrawal研究团队作为数据驱动材料基因领域的代表性团队,其所使用的人工智能技术一直具有极强的前瞻性.同一时间,日本统计数理研究所的Yamada等[92]也发表了迁移学习在有机和无机化学领域的应用,证明了其在减少人工智能训练数据需求量方面的强大能力.虽然上述迁移学习工作已得到诸多材料学者的广泛认可,但实质上在上述研究结果发表的3年后,迁移学习技术才被合金设计领域关注并形成了第一个代表性的示范案例:低合金钢的疲劳性能设计[93].众所周知,疲劳性能的测试需要消耗大量时间与资金成本,因此金属的疲劳一直是一个数据稀缺的领域.Wei等[93]将疲劳与常规力学性能间具有强关联性这一力学领域广泛认可的基本物理机制引入至人工神经网络框架,实现了使用常规拉伸数据部分取代疲劳数据的效果,其最终仅使用30余条疲劳数据就建立起可以进行合理合金设计的疲劳强度预测模型,设计结果与实验验证结果吻合良好,新设计的合金实现了疲劳强度提升50 MPa的效果.30余条数据建立一个人工智能模型而不出现过拟合本身就是一个很令人惊讶的夸张效果,且还能保证对新数据进行稳定的扩展预测,并指导合理的合金设计,实属罕见.而形成该效果的本质原因是该模型的框架中包含了“常规力学性能-疲劳性能”这一物理机制的“弱约束”,因此常规拉伸性能预测的源模型为迁移后的疲劳性能预测模型提供了大量可直接借鉴的经验,大幅降低了模型在分析该问题时面临的困难.该范例充分证明了将物理冶金机制引入人工智能可使其突破人工智能本身算法的局限性,获得准确性与扩展能力的同时提升. ...
On the use of transfer modeling to design new steels with excellent rotating bending fatigue resistance even in the case of very small calibration datasets
2
2022
... 迁移学习技术作为图像识别领域非常经典的技术手段,其在材料学领域的图像识别方面也早有应用.但真正将迁移学习技术与物理机制相关联,进行机制数据间的迁移最早始于2019年,美国西北大学Ankit Agrawal研究团队的Jha等[91]将其应用于加速第一性原理计算,并提出了该算法可通过机制间的关联关系,大幅缩减人工智能面对新问题时训练所需数据量的观点.从依托GAN算法的合金设计,到基于物理机制的迁移学习技术,Ankit Agrawal研究团队作为数据驱动材料基因领域的代表性团队,其所使用的人工智能技术一直具有极强的前瞻性.同一时间,日本统计数理研究所的Yamada等[92]也发表了迁移学习在有机和无机化学领域的应用,证明了其在减少人工智能训练数据需求量方面的强大能力.虽然上述迁移学习工作已得到诸多材料学者的广泛认可,但实质上在上述研究结果发表的3年后,迁移学习技术才被合金设计领域关注并形成了第一个代表性的示范案例:低合金钢的疲劳性能设计[93].众所周知,疲劳性能的测试需要消耗大量时间与资金成本,因此金属的疲劳一直是一个数据稀缺的领域.Wei等[93]将疲劳与常规力学性能间具有强关联性这一力学领域广泛认可的基本物理机制引入至人工神经网络框架,实现了使用常规拉伸数据部分取代疲劳数据的效果,其最终仅使用30余条疲劳数据就建立起可以进行合理合金设计的疲劳强度预测模型,设计结果与实验验证结果吻合良好,新设计的合金实现了疲劳强度提升50 MPa的效果.30余条数据建立一个人工智能模型而不出现过拟合本身就是一个很令人惊讶的夸张效果,且还能保证对新数据进行稳定的扩展预测,并指导合理的合金设计,实属罕见.而形成该效果的本质原因是该模型的框架中包含了“常规力学性能-疲劳性能”这一物理机制的“弱约束”,因此常规拉伸性能预测的源模型为迁移后的疲劳性能预测模型提供了大量可直接借鉴的经验,大幅降低了模型在分析该问题时面临的困难.该范例充分证明了将物理冶金机制引入人工智能可使其突破人工智能本身算法的局限性,获得准确性与扩展能力的同时提升. ...
... [93]将疲劳与常规力学性能间具有强关联性这一力学领域广泛认可的基本物理机制引入至人工神经网络框架,实现了使用常规拉伸数据部分取代疲劳数据的效果,其最终仅使用30余条疲劳数据就建立起可以进行合理合金设计的疲劳强度预测模型,设计结果与实验验证结果吻合良好,新设计的合金实现了疲劳强度提升50 MPa的效果.30余条数据建立一个人工智能模型而不出现过拟合本身就是一个很令人惊讶的夸张效果,且还能保证对新数据进行稳定的扩展预测,并指导合理的合金设计,实属罕见.而形成该效果的本质原因是该模型的框架中包含了“常规力学性能-疲劳性能”这一物理机制的“弱约束”,因此常规拉伸性能预测的源模型为迁移后的疲劳性能预测模型提供了大量可直接借鉴的经验,大幅降低了模型在分析该问题时面临的困难.该范例充分证明了将物理冶金机制引入人工智能可使其突破人工智能本身算法的局限性,获得准确性与扩展能力的同时提升. ...
A rapid and effective method for alloy materials design via sample data transfer machine learning
1
2023
... 迁移学习技术本质上是一个方法理念,只要所处理的问题与前人已解决的某个问题有关联性或相似性,就可以使用迁移学习技术直接将其模型中学到的“机制或规律”沿用至本问题.最简单的操作方式就是保持源模型的特征提取过程参数不变,只使用现问题的数据重新训练模型在特征提取之后所涉及的参数.因此该方法所需数据量少,对模型构架无特别要求,是一个非常容易推广使用的范式.因此,目前迁移学习技术也被广泛应用于诸多合金设计案例中:近期,Jiang等[94]在铝合金体系下实现了基于迁移学习的合金设计案例,同样着重强调了迁移学习数据需求少的显著优势.针对不同的性能目标需求,迁移学习方法也被进一步推广应用至蠕变性能的预测与设计,甚至疲劳曲线的外推与条件转换等方向[95]. ...
High cycle fatigue S-N curve prediction of steels based on transfer learning guided long short term memory network
1
2022
... 迁移学习技术本质上是一个方法理念,只要所处理的问题与前人已解决的某个问题有关联性或相似性,就可以使用迁移学习技术直接将其模型中学到的“机制或规律”沿用至本问题.最简单的操作方式就是保持源模型的特征提取过程参数不变,只使用现问题的数据重新训练模型在特征提取之后所涉及的参数.因此该方法所需数据量少,对模型构架无特别要求,是一个非常容易推广使用的范式.因此,目前迁移学习技术也被广泛应用于诸多合金设计案例中:近期,Jiang等[94]在铝合金体系下实现了基于迁移学习的合金设计案例,同样着重强调了迁移学习数据需求少的显著优势.针对不同的性能目标需求,迁移学习方法也被进一步推广应用至蠕变性能的预测与设计,甚至疲劳曲线的外推与条件转换等方向[95]. ...
Scientific machine learning through physics-informed neural networks: Where we are and what's next
3
2022
... 上述介绍的迁移学习技术虽然是一个非常具有代表性的“非数据引入”型物理冶金原理指导人工智能方法策略,但通过调整神经网络构架引入物理冶金机制显然只能处理定性或半定量的机制关系,因为构架调整实质上不涉及任何定量化的公式构建.那是否可以将各种定量化的物理场与物理机制直接以公式、方程的形式引入人工智能算法,实现约束指导的作用?论及这方面的研究,就涉及了目前AI4Sci领域的热点研究方向之一:物理信息神经网络(physics-informed neural network,PINN)[96].但同样值得注意的是,PINN也并非本文主要推荐在合金设计中使用的计算策略. ...
... 如图10所示,PINN是一个主要基于人工智能思想提出的技术路线,人工智能模型在训练过程中所受到的约束完全来源于其设定的损失函数,按损失函数计算后损失达到最低则模型训练过程终止.所以对人工智能进行方程式约束的最直接办法,就是将物理方程直接写进损失函数里,则模型自然会沿着损失函数所界定的方程形式进行训练与优化.作为一个重要的研究方向,人工智能领域近年来开发的PINN算法较多,包括物理信息卷积神经网络(physics-informed convolutional neural network,PCNN)、守恒物理信息神经网络(conservative physics-informed neural networks,CPINN)等,而这些算法的技术细节见文献[96].从表象来看,PINN似乎是一个非常值得推广的应用范式,其不受机制的尺度限制、不受体系种类限制,只要合金设计过程中涉及的物理过程可以用方程形式表示,就可以将其引入损失函数,万事皆可PINN.但当抛却这些华丽的示范案例,更为深入地窥视PINN的数学理论本质时,就会发现PINN并没有想象中的那样完美.这也是本文在开篇之初花费大量篇幅介绍各方法数学理论基础的原因,只有透过这些数学本质才能看清各种计算方式真正的优势与劣势.实质上,损失函数对人工智能算法的约束是一种“强约束”,不是“规劝与引导”,而是强迫人工智能必须按这个方程形式去训练,与损失函数所定义的方程形式不够吻合,模型训练过程就不会停止.所以PINN的本质是让一个高自由度的统计学算法强行拟合成一个与定义的损失函数相一致的固定微分方程形式,可以形象地称其为“人工智能物理模型化”.所以,即使再精确的拟合也会有误差,自然可以想象,对于一个低纬度的简单问题,PINN就是一个全面弱化版的物理模型,其拟合所需的数据量远高于物理模型,准确度却低于物理模型,域外扩展能力也不会比物理模型更好,这一点也是人工智能领域对PINN公认的评价[96].对于高维度复杂问题,PINN则会体现出一定的优势,因为基于有限元思想的物理模型很容易在维度过大的体系下产生误差累积,变得极为不准确,此时PINN这种随机拟合的算法则会体现出相对更好的准确性优势,这与统计模拟方法中的Monte Carlo思想类似.例如,上述提到的多数固体力学领域案例均强调了PINN在高维问题求解方面的准确性优势[97,98].需要注意的是,这里提到的准确性优势并不是指PINN真的很准确,而是因为有限元计算在高维度问题上更加不准,所以PINN相对更可接受一些.所以,这种“人工智能物理模型化”的思想显然是与物理冶金原理指导人工智能方法的理论基础并不完全吻合.PINN中物理方程起到的作用显然已经不是“弱约束”了,而是一种逼迫人工智能成为物理模型的“强约束”,导致的结果就是人工智能变成了与物理模型一样的低准确性、高域外扩展能力算法,本质上依然没有打破准确性与域外扩展能力间的互斥关系. ...
... [96].对于高维度复杂问题,PINN则会体现出一定的优势,因为基于有限元思想的物理模型很容易在维度过大的体系下产生误差累积,变得极为不准确,此时PINN这种随机拟合的算法则会体现出相对更好的准确性优势,这与统计模拟方法中的Monte Carlo思想类似.例如,上述提到的多数固体力学领域案例均强调了PINN在高维问题求解方面的准确性优势[97,98].需要注意的是,这里提到的准确性优势并不是指PINN真的很准确,而是因为有限元计算在高维度问题上更加不准,所以PINN相对更可接受一些.所以,这种“人工智能物理模型化”的思想显然是与物理冶金原理指导人工智能方法的理论基础并不完全吻合.PINN中物理方程起到的作用显然已经不是“弱约束”了,而是一种逼迫人工智能成为物理模型的“强约束”,导致的结果就是人工智能变成了与物理模型一样的低准确性、高域外扩展能力算法,本质上依然没有打破准确性与域外扩展能力间的互斥关系. ...
A variational formulation of physics-informed neural network for the applications of homogeneous and heterogeneous material properties identification
1
2023
... 如图10所示,PINN是一个主要基于人工智能思想提出的技术路线,人工智能模型在训练过程中所受到的约束完全来源于其设定的损失函数,按损失函数计算后损失达到最低则模型训练过程终止.所以对人工智能进行方程式约束的最直接办法,就是将物理方程直接写进损失函数里,则模型自然会沿着损失函数所界定的方程形式进行训练与优化.作为一个重要的研究方向,人工智能领域近年来开发的PINN算法较多,包括物理信息卷积神经网络(physics-informed convolutional neural network,PCNN)、守恒物理信息神经网络(conservative physics-informed neural networks,CPINN)等,而这些算法的技术细节见文献[96].从表象来看,PINN似乎是一个非常值得推广的应用范式,其不受机制的尺度限制、不受体系种类限制,只要合金设计过程中涉及的物理过程可以用方程形式表示,就可以将其引入损失函数,万事皆可PINN.但当抛却这些华丽的示范案例,更为深入地窥视PINN的数学理论本质时,就会发现PINN并没有想象中的那样完美.这也是本文在开篇之初花费大量篇幅介绍各方法数学理论基础的原因,只有透过这些数学本质才能看清各种计算方式真正的优势与劣势.实质上,损失函数对人工智能算法的约束是一种“强约束”,不是“规劝与引导”,而是强迫人工智能必须按这个方程形式去训练,与损失函数所定义的方程形式不够吻合,模型训练过程就不会停止.所以PINN的本质是让一个高自由度的统计学算法强行拟合成一个与定义的损失函数相一致的固定微分方程形式,可以形象地称其为“人工智能物理模型化”.所以,即使再精确的拟合也会有误差,自然可以想象,对于一个低纬度的简单问题,PINN就是一个全面弱化版的物理模型,其拟合所需的数据量远高于物理模型,准确度却低于物理模型,域外扩展能力也不会比物理模型更好,这一点也是人工智能领域对PINN公认的评价[96].对于高维度复杂问题,PINN则会体现出一定的优势,因为基于有限元思想的物理模型很容易在维度过大的体系下产生误差累积,变得极为不准确,此时PINN这种随机拟合的算法则会体现出相对更好的准确性优势,这与统计模拟方法中的Monte Carlo思想类似.例如,上述提到的多数固体力学领域案例均强调了PINN在高维问题求解方面的准确性优势[97,98].需要注意的是,这里提到的准确性优势并不是指PINN真的很准确,而是因为有限元计算在高维度问题上更加不准,所以PINN相对更可接受一些.所以,这种“人工智能物理模型化”的思想显然是与物理冶金原理指导人工智能方法的理论基础并不完全吻合.PINN中物理方程起到的作用显然已经不是“弱约束”了,而是一种逼迫人工智能成为物理模型的“强约束”,导致的结果就是人工智能变成了与物理模型一样的低准确性、高域外扩展能力算法,本质上依然没有打破准确性与域外扩展能力间的互斥关系. ...
Recent advances and applications of machine learning in experimental solid mechanics: A review
1
2023
... 如图10所示,PINN是一个主要基于人工智能思想提出的技术路线,人工智能模型在训练过程中所受到的约束完全来源于其设定的损失函数,按损失函数计算后损失达到最低则模型训练过程终止.所以对人工智能进行方程式约束的最直接办法,就是将物理方程直接写进损失函数里,则模型自然会沿着损失函数所界定的方程形式进行训练与优化.作为一个重要的研究方向,人工智能领域近年来开发的PINN算法较多,包括物理信息卷积神经网络(physics-informed convolutional neural network,PCNN)、守恒物理信息神经网络(conservative physics-informed neural networks,CPINN)等,而这些算法的技术细节见文献[96].从表象来看,PINN似乎是一个非常值得推广的应用范式,其不受机制的尺度限制、不受体系种类限制,只要合金设计过程中涉及的物理过程可以用方程形式表示,就可以将其引入损失函数,万事皆可PINN.但当抛却这些华丽的示范案例,更为深入地窥视PINN的数学理论本质时,就会发现PINN并没有想象中的那样完美.这也是本文在开篇之初花费大量篇幅介绍各方法数学理论基础的原因,只有透过这些数学本质才能看清各种计算方式真正的优势与劣势.实质上,损失函数对人工智能算法的约束是一种“强约束”,不是“规劝与引导”,而是强迫人工智能必须按这个方程形式去训练,与损失函数所定义的方程形式不够吻合,模型训练过程就不会停止.所以PINN的本质是让一个高自由度的统计学算法强行拟合成一个与定义的损失函数相一致的固定微分方程形式,可以形象地称其为“人工智能物理模型化”.所以,即使再精确的拟合也会有误差,自然可以想象,对于一个低纬度的简单问题,PINN就是一个全面弱化版的物理模型,其拟合所需的数据量远高于物理模型,准确度却低于物理模型,域外扩展能力也不会比物理模型更好,这一点也是人工智能领域对PINN公认的评价[96].对于高维度复杂问题,PINN则会体现出一定的优势,因为基于有限元思想的物理模型很容易在维度过大的体系下产生误差累积,变得极为不准确,此时PINN这种随机拟合的算法则会体现出相对更好的准确性优势,这与统计模拟方法中的Monte Carlo思想类似.例如,上述提到的多数固体力学领域案例均强调了PINN在高维问题求解方面的准确性优势[97,98].需要注意的是,这里提到的准确性优势并不是指PINN真的很准确,而是因为有限元计算在高维度问题上更加不准,所以PINN相对更可接受一些.所以,这种“人工智能物理模型化”的思想显然是与物理冶金原理指导人工智能方法的理论基础并不完全吻合.PINN中物理方程起到的作用显然已经不是“弱约束”了,而是一种逼迫人工智能成为物理模型的“强约束”,导致的结果就是人工智能变成了与物理模型一样的低准确性、高域外扩展能力算法,本质上依然没有打破准确性与域外扩展能力间的互斥关系. ...
MFC-PINN: A method to improve the accuracy and robustness of acoustic emission source planar localization
1
2024
... 由此说来,为何还要花大量篇幅介绍PINN这一方法?PINN在合金设计方面的价值在于其是一个非常方便的微分方程“万能自动”求解器.试想在使用物理模型进行合金计算设计的过程中,搜索到某一个合金成分空间时无法收敛,需要将原本的梯度下降法变成Newton迭代法才能继续算出结果,这将会给合金的自动化设计带来很大的不便.同理,当使用有限元进行合金计算设计时,若针对不同案例都要重新进行手动网格划分,如何去进行合金方案的大范围自动化搜索?所以,当使用PINN作为一个物理方程的替代品时,可直接规避各种网格划分及优化算法选取的问题,从而更为便捷地形成一个自动化迭代寻优的设计系统.相比于有限元等无法规避手动调整网格划分步骤的算法,PINN可以成为一个取代有限元的自动化提供机制数据的方法,用于在合金设计过程中更便捷地为其他人工智能算法的迭代过程提供持续的数据供应.例如,Mondal等[65]用PINN提供传热与凝固相关数据,从而利用该机制数据指导人工智能预测3D打印合金的裂纹敏感性.Zhang等[99]则结合图像信息与PINN提供的数据信息进行多模态数据分析建模,用以分析铝合金材料的内部缺陷.因此,从取代物理模型、为人工智能算法提供更便捷的物理机制信息获取渠道方面,PINN可以发挥良好的贡献作用. ...
AI for Science: Pursuing the brightest side of human intelligence
1
... 在遍历了如此多算法范式与应用案例后,还是要聚焦回本文的主题:在合金设计领域,物理模型、数据驱动和AI4Sci三个范式间的协同、替代和发展关系.其实在本文第2小节论述过后,多尺度物理模型和数据驱动范式各自的优劣势就已经比较清晰了,而且两大范式都很难在合金设计领域基于自身的理论框架突破各自面临的困局.因此,AI4Sci的思路实质上与本文重点介绍的物理冶金原理指导人工智能方法非常接近,融合了各范式的优势.而这里所指的各范式不仅包括物理模型与数据驱动,也包含第一和第二范式涉及的理论与经验.正如刘铁岩[100]对AI4Sci的解读:AI4Sci的本质是以物理机制为核心,以人工智能技术处理实验观测结果与现今普适性理论间的残差.该解读与本文中所强调的物理冶金原理指导人工智能方法的理论基础不谋而合.虽然一家之言并不能代表AI4Sci的总体全貌,但至少可以证明,在以金属结构材料为主的合金设计领域中,物理冶金原理指导人工智能方法可以被理解为AI4Sci方向的一个分支.由此可见,AI4Sci作为第五范式,其代表着未来科学发展的关键趋势,合金设计领域显然也不例外.但专注于AI4Sci的发展并不等于从事物理模型与数据驱动研究就要被淘汰,因为AI4Sci本身就是前四种科学范式的结合体,只是未来研究人员在基于自身范式发展的研究基础上,要更关注于其他范式的进展情况,以明确未来研究方向,尽量使自身研究方向与其他范式研究进展相结合时能起到共同促进、而非相互取代的作用.基于此目的,本文在最后的展望部分,基于主观浅显的理解,尝试性地提出各范式在未来合金设计领域可能的高潜力研究方向,以供参考(图11). ...
AI for Science: 追求人类智能最光辉的一面
1
... 在遍历了如此多算法范式与应用案例后,还是要聚焦回本文的主题:在合金设计领域,物理模型、数据驱动和AI4Sci三个范式间的协同、替代和发展关系.其实在本文第2小节论述过后,多尺度物理模型和数据驱动范式各自的优劣势就已经比较清晰了,而且两大范式都很难在合金设计领域基于自身的理论框架突破各自面临的困局.因此,AI4Sci的思路实质上与本文重点介绍的物理冶金原理指导人工智能方法非常接近,融合了各范式的优势.而这里所指的各范式不仅包括物理模型与数据驱动,也包含第一和第二范式涉及的理论与经验.正如刘铁岩[100]对AI4Sci的解读:AI4Sci的本质是以物理机制为核心,以人工智能技术处理实验观测结果与现今普适性理论间的残差.该解读与本文中所强调的物理冶金原理指导人工智能方法的理论基础不谋而合.虽然一家之言并不能代表AI4Sci的总体全貌,但至少可以证明,在以金属结构材料为主的合金设计领域中,物理冶金原理指导人工智能方法可以被理解为AI4Sci方向的一个分支.由此可见,AI4Sci作为第五范式,其代表着未来科学发展的关键趋势,合金设计领域显然也不例外.但专注于AI4Sci的发展并不等于从事物理模型与数据驱动研究就要被淘汰,因为AI4Sci本身就是前四种科学范式的结合体,只是未来研究人员在基于自身范式发展的研究基础上,要更关注于其他范式的进展情况,以明确未来研究方向,尽量使自身研究方向与其他范式研究进展相结合时能起到共同促进、而非相互取代的作用.基于此目的,本文在最后的展望部分,基于主观浅显的理解,尝试性地提出各范式在未来合金设计领域可能的高潜力研究方向,以供参考(图11). ...



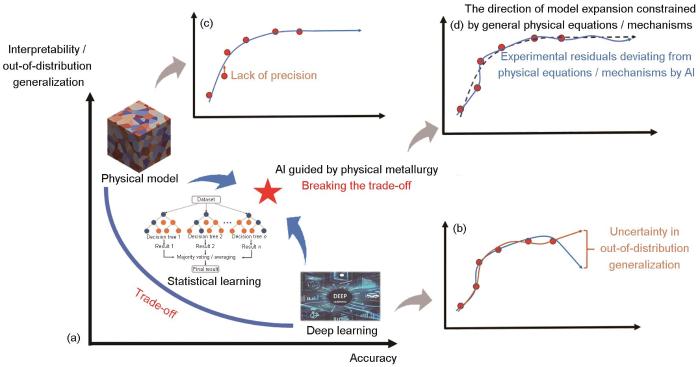
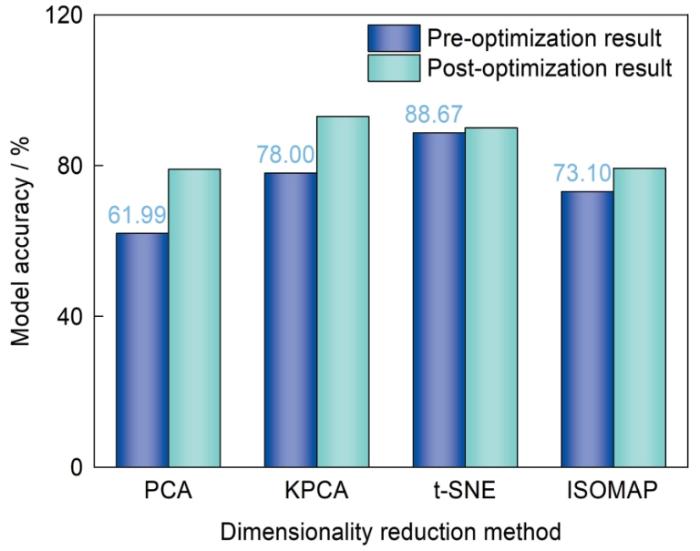
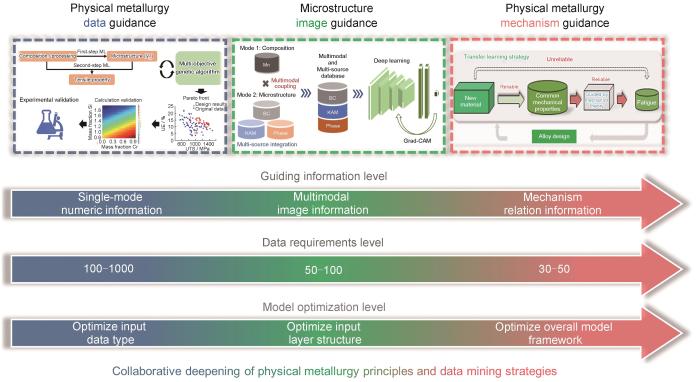
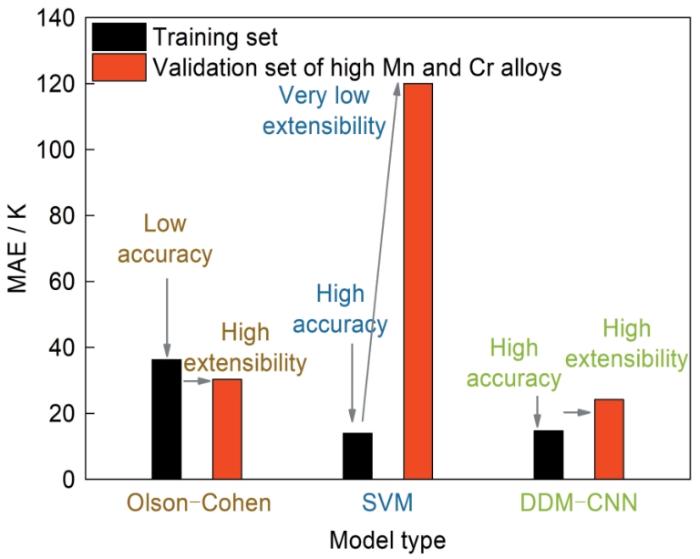
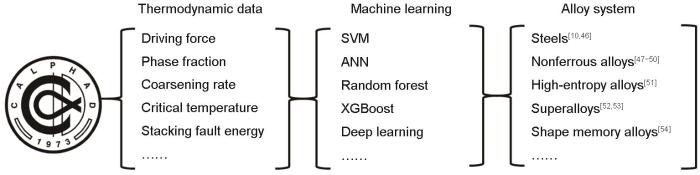
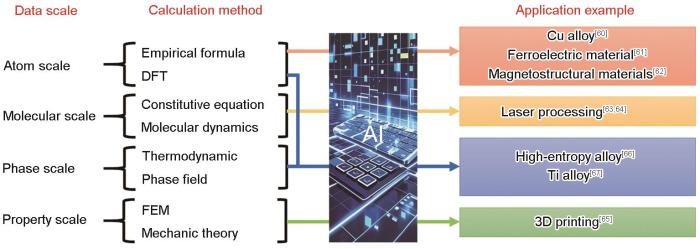
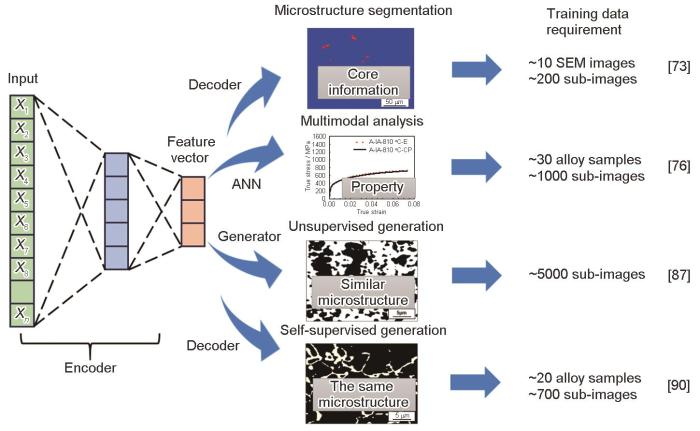


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}