Perspective: Materials informatics and big data: Realization of the “fourth paradigm” of science in materials science
3
2016
... 材料是一个复杂的高维多尺度耦合系统,现有的基础理论还不能准确地描述材料成分-组织/结构-性能-服役行为的构效关系,一些深层次的机理还不清楚,导致材料研发长期沿用基于经验的“试错法”.1980年以来,随着计算机的发展和计算能力的提高,计算材料学快速兴起,推动了材料研发由“经验+试错”的模式向计算驱动的研发模式转变[1 ] .材料基因工程的提出,促进了材料大数据的发展[2 ] ,推动了人工智能技术在材料领域的全面应用,数据驱动的材料研发第四范式正在形成[1 ] . ...
... [1 ]. ...
... 近年来,机器学习已经成为材料研究的前沿方向和热点领域[1 , 3 ~12 ] .Hart等[3 ] 综述了机器学习辅助合金研究的进展,总结了机器学习在非晶合金、高熵合金、形状记忆合金、磁性材料、超合金等研究中的典型应用.Lookman等[4 ] 综述了自适应实验采样和贝叶斯优化(Bayesian optimization)方法,总结了主动学习在加速新材料探索发现中的应用.Schmidt等[5 ] 以材料计算数据机器学习为主线,从基础原理与算法、机器学习辅助新材料发现和性能预测、模型可解释性等方面进行了综述和分析.Liu等[6 ] 在材料基因工程思想框架下,按照材料数据生命周期理念,总结了典型材料数据库、机器学习原理、材料结构-性能-描述符的预测,以及新材料研发的诸多应用案例. ...
中国材料基因工程研究进展
1
2020
... 材料是一个复杂的高维多尺度耦合系统,现有的基础理论还不能准确地描述材料成分-组织/结构-性能-服役行为的构效关系,一些深层次的机理还不清楚,导致材料研发长期沿用基于经验的“试错法”.1980年以来,随着计算机的发展和计算能力的提高,计算材料学快速兴起,推动了材料研发由“经验+试错”的模式向计算驱动的研发模式转变[1 ] .材料基因工程的提出,促进了材料大数据的发展[2 ] ,推动了人工智能技术在材料领域的全面应用,数据驱动的材料研发第四范式正在形成[1 ] . ...
中国材料基因工程研究进展
1
2020
... 材料是一个复杂的高维多尺度耦合系统,现有的基础理论还不能准确地描述材料成分-组织/结构-性能-服役行为的构效关系,一些深层次的机理还不清楚,导致材料研发长期沿用基于经验的“试错法”.1980年以来,随着计算机的发展和计算能力的提高,计算材料学快速兴起,推动了材料研发由“经验+试错”的模式向计算驱动的研发模式转变[1 ] .材料基因工程的提出,促进了材料大数据的发展[2 ] ,推动了人工智能技术在材料领域的全面应用,数据驱动的材料研发第四范式正在形成[1 ] . ...
Machine learning for alloys
2
2021
... 近年来,机器学习已经成为材料研究的前沿方向和热点领域[1 , 3 ~12 ] .Hart等[3 ] 综述了机器学习辅助合金研究的进展,总结了机器学习在非晶合金、高熵合金、形状记忆合金、磁性材料、超合金等研究中的典型应用.Lookman等[4 ] 综述了自适应实验采样和贝叶斯优化(Bayesian optimization)方法,总结了主动学习在加速新材料探索发现中的应用.Schmidt等[5 ] 以材料计算数据机器学习为主线,从基础原理与算法、机器学习辅助新材料发现和性能预测、模型可解释性等方面进行了综述和分析.Liu等[6 ] 在材料基因工程思想框架下,按照材料数据生命周期理念,总结了典型材料数据库、机器学习原理、材料结构-性能-描述符的预测,以及新材料研发的诸多应用案例. ...
... [3 ]综述了机器学习辅助合金研究的进展,总结了机器学习在非晶合金、高熵合金、形状记忆合金、磁性材料、超合金等研究中的典型应用.Lookman等[4 ] 综述了自适应实验采样和贝叶斯优化(Bayesian optimization)方法,总结了主动学习在加速新材料探索发现中的应用.Schmidt等[5 ] 以材料计算数据机器学习为主线,从基础原理与算法、机器学习辅助新材料发现和性能预测、模型可解释性等方面进行了综述和分析.Liu等[6 ] 在材料基因工程思想框架下,按照材料数据生命周期理念,总结了典型材料数据库、机器学习原理、材料结构-性能-描述符的预测,以及新材料研发的诸多应用案例. ...
Active learning in materials science with emphasis on adaptive sampling using uncertainties for targeted design
1
2019
... 近年来,机器学习已经成为材料研究的前沿方向和热点领域[1 , 3 ~12 ] .Hart等[3 ] 综述了机器学习辅助合金研究的进展,总结了机器学习在非晶合金、高熵合金、形状记忆合金、磁性材料、超合金等研究中的典型应用.Lookman等[4 ] 综述了自适应实验采样和贝叶斯优化(Bayesian optimization)方法,总结了主动学习在加速新材料探索发现中的应用.Schmidt等[5 ] 以材料计算数据机器学习为主线,从基础原理与算法、机器学习辅助新材料发现和性能预测、模型可解释性等方面进行了综述和分析.Liu等[6 ] 在材料基因工程思想框架下,按照材料数据生命周期理念,总结了典型材料数据库、机器学习原理、材料结构-性能-描述符的预测,以及新材料研发的诸多应用案例. ...
Recent advances and applications of machine learning in solid-state materials science
2
2019
... 近年来,机器学习已经成为材料研究的前沿方向和热点领域[1 , 3 ~12 ] .Hart等[3 ] 综述了机器学习辅助合金研究的进展,总结了机器学习在非晶合金、高熵合金、形状记忆合金、磁性材料、超合金等研究中的典型应用.Lookman等[4 ] 综述了自适应实验采样和贝叶斯优化(Bayesian optimization)方法,总结了主动学习在加速新材料探索发现中的应用.Schmidt等[5 ] 以材料计算数据机器学习为主线,从基础原理与算法、机器学习辅助新材料发现和性能预测、模型可解释性等方面进行了综述和分析.Liu等[6 ] 在材料基因工程思想框架下,按照材料数据生命周期理念,总结了典型材料数据库、机器学习原理、材料结构-性能-描述符的预测,以及新材料研发的诸多应用案例. ...
... 近年来,以实验和生产数据为基础的机器学习辅助材料设计在金属、陶瓷、高分子等结构和功能材料中得到较为广泛应用,以材料计算数据为基础的机器学习在能源材料、催化材料、拓扑材料等前沿材料领域取得了引人瞩目的进展[5 ] .机器学习与材料实验技术的融合,发展了材料自主实验技术[107 ,108 ,144 ~146 ] ,有效地提升了材料实验的效率和智能化水平.机器学习与材料第一性原理计算,以及相场和有限元模拟相结合,大幅度提升了材料计算设计和筛选的效率.限于篇幅,本文重点以实验和生产数据为基础,以在金属材料,特别是金属结构材料中的应用为案例,综述了机器学习在材料设计和优化中的研究进展. ...
Machine learning in materials genome initiative: A review
1
2020
... 近年来,机器学习已经成为材料研究的前沿方向和热点领域[1 , 3 ~12 ] .Hart等[3 ] 综述了机器学习辅助合金研究的进展,总结了机器学习在非晶合金、高熵合金、形状记忆合金、磁性材料、超合金等研究中的典型应用.Lookman等[4 ] 综述了自适应实验采样和贝叶斯优化(Bayesian optimization)方法,总结了主动学习在加速新材料探索发现中的应用.Schmidt等[5 ] 以材料计算数据机器学习为主线,从基础原理与算法、机器学习辅助新材料发现和性能预测、模型可解释性等方面进行了综述和分析.Liu等[6 ] 在材料基因工程思想框架下,按照材料数据生命周期理念,总结了典型材料数据库、机器学习原理、材料结构-性能-描述符的预测,以及新材料研发的诸多应用案例. ...
A critical review of machine learn-ing of energy materials
0
2020
Machine learning in materials informatics: Recent applications and prospects
0
2017
Emerging materials intelligence ecosystems propelled by machine learning
0
2021
Materials informatics: From the atomic-level to the continuum
0
2019
Strategies for accelerating the adoption of materials informatics
0
2018
Machine learning in materials design: Algorithm and application
1
2020
... 近年来,机器学习已经成为材料研究的前沿方向和热点领域[1 , 3 ~12 ] .Hart等[3 ] 综述了机器学习辅助合金研究的进展,总结了机器学习在非晶合金、高熵合金、形状记忆合金、磁性材料、超合金等研究中的典型应用.Lookman等[4 ] 综述了自适应实验采样和贝叶斯优化(Bayesian optimization)方法,总结了主动学习在加速新材料探索发现中的应用.Schmidt等[5 ] 以材料计算数据机器学习为主线,从基础原理与算法、机器学习辅助新材料发现和性能预测、模型可解释性等方面进行了综述和分析.Liu等[6 ] 在材料基因工程思想框架下,按照材料数据生命周期理念,总结了典型材料数据库、机器学习原理、材料结构-性能-描述符的预测,以及新材料研发的诸多应用案例. ...
Dramatically enhanced combina-tion of ultimate tensile strength and electric conductivity of alloys via machine learning screening
2
2020
... 建立机器学习模型的输入量有多种表述方法,如变量(variable)、特征(feature)、描述符(descriptor)、指纹(fingerprint)等,不同材料领域的表述方法也不尽相同,例如在催化材料领域通常称为特征、描述符或指纹等.本文将材料成分、组织/结构、制备工艺等决定材料性质或服役行为的参量称为材料参数(material parameter),根据材料理论或先验知识,通过材料参数与材料物理和化学参量或元素电子原子参量间的数学运算构建的参量称为材料因子(material factor)或合金因子(alloy factor)[13 ] .根据研究问题或目标量的需求,在一些情况下,一般单独使用或者混合使用合金元素的物理化学本征参量(如原子半径、点阵常数等)、材料参数和材料因子(合金因子)作为建立机器学习模型的输入量,以材料的结构/组织或性能作为机器学习模型的输出(目标量).为了叙述方便,在一般泛指的场合,本文将合金元素的物理化学本征参量、材料参数和材料因子统称为材料特征.而在另外一些情况下,例如逆向设计,则将材料的性能或结构作为机器学习模型的输入,以成分或工艺参数等作为机器学习模型的输出. ...
... 科学合理地构建与目标量相关的材料特征是建立高精度机器学习预测模型、辅助理解材料机制、实现材料高效优化设计的基础.对于应用场景固定的材料问题或目标量,利用先验知识,结合问题场景,一般直接利用材料参数为特征训练机器学习模型.Pattanayak等[14 ] 直接利用管线钢成分、加热温度、初轧温度、精轧温度、冷却初始温度和冷却速率等材料参数为特征,建立了管线钢屈服强度、抗拉强度、断后伸长率、冲击功等力学性能的机器学习模型,对管线钢的成分和工艺进行了优化设计.为了增强机器学习模型的泛化能力,一般利用材料先验知识将元素的电子、原子和晶体结构参量,以及材料的热力学和动力学参量等与材料参数进行数学运算,将材料参数转化成材料因子训练机器学习模型,如Zhang等[13 ] 设计高强度高导电率铜合金时,利用原子半径、电负性和核电子距离(core electron distance)等69个物理化学本征参量,以材料成分为权重,通过平均和方差运算,构建了138个合金因子,筛选出用于建立铜合金抗拉强度和导电率机器学习模型的合金因子,成功研发出了多种新型高强高导电铜合金,同时发现描述铜合金固溶强化的合金因子可以用于固溶强化铝合金强度的机器学习建模. ...
Computational intelligence based designing of microalloyed pipeline steel
1
2015
... 科学合理地构建与目标量相关的材料特征是建立高精度机器学习预测模型、辅助理解材料机制、实现材料高效优化设计的基础.对于应用场景固定的材料问题或目标量,利用先验知识,结合问题场景,一般直接利用材料参数为特征训练机器学习模型.Pattanayak等[14 ] 直接利用管线钢成分、加热温度、初轧温度、精轧温度、冷却初始温度和冷却速率等材料参数为特征,建立了管线钢屈服强度、抗拉强度、断后伸长率、冲击功等力学性能的机器学习模型,对管线钢的成分和工艺进行了优化设计.为了增强机器学习模型的泛化能力,一般利用材料先验知识将元素的电子、原子和晶体结构参量,以及材料的热力学和动力学参量等与材料参数进行数学运算,将材料参数转化成材料因子训练机器学习模型,如Zhang等[13 ] 设计高强度高导电率铜合金时,利用原子半径、电负性和核电子距离(core electron distance)等69个物理化学本征参量,以材料成分为权重,通过平均和方差运算,构建了138个合金因子,筛选出用于建立铜合金抗拉强度和导电率机器学习模型的合金因子,成功研发出了多种新型高强高导电铜合金,同时发现描述铜合金固溶强化的合金因子可以用于固溶强化铝合金强度的机器学习建模. ...
Simple descriptor derived from symbolic regression accelerating the discovery of new perovskite catalysts
2
2020
... 以材料特征为输入建立机器学习模型,往往遇到输入变量维数高、信息冗余严重的问题,带来维数灾难(curse of dimensionality),使数据变得稀疏或导致模型过拟合.为此,机器学习建模时通常需要对材料因子进行过滤和筛选,以降低数据维度,提高模型精度,增强模型泛化能力.在某些特殊情况下,利用材料理论和先验知识,选择合理的材料物理化学参量和数学运算法则,构建尽可能与目标量物理相关的材料因子也是提升模型精度和泛化能力的有效方法,有可能构建和筛选出具有潜在物理解释性的材料因子,辅助材料机制的理解,例如,通过特征构建与筛选,提出了钙钛矿催化材料析氧反应[15 ] 和二维MXenes催化材料析氢反应的描述符[16 ] ,寻找到了AB 2 C 型化合物具有Heusler结构概率[17 ] 的控制参量和双钙钛矿带隙的主要影响因素[18 ] 等. ...
... 符号回归是利用优化算法,将数学运算符(如:+、-、*、/、sin、cos、log等)和材料特征等进行数学组合,回归目标量和材料特征(输入)之间的数学表达式,从而建立材料构效关系(QSAR)的显性表达式.Weng等[15 ] 对d轨道电子数、容忍因子t 、八面体因子μ 、以及A 、B 、X 位点的氧化价态、离子半径、电负性等参量进行符号回归,通过平衡数学公式的准确性和简单性,建立了钙钛矿结构催化材料析氧反应活性可逆氢电极过电位的数学关系式,提出了A 位点选用大离子半径阳离子,B 位点选用小离子半径阳离子的高效钙钛矿结构催化材料的优选方案,指导合成了5种新型钙钛矿结构催化材料,其中4种材料的催化活性优于已有材料.Loftis等[83 ] 基于347种钙钛矿结构、立方结构、六方ZnS结构等化合物导热系数的计算数据样本,利用符号回归建立了晶格导热系数的数学表达式,均方根误差达到5.296,远小于Slack模型的误差(19.451).Yuan等[84 ] 使用LASSO模型和符号回归方法,基于82种典型介电材料电击穿数据样本,对带隙、声子截止频率、晶体密度、介电常数、原子最近邻距离、Young's模量等参量进行符号回归,通过帕累托(Pareto)前沿面平衡数学公式的复杂度和误差,回归出了以带隙和声子截止频率为变量的介电材料电击穿强度数学表达式,预测结果与第一性原理计算结果的Pearson相关系数为0.74.魏清华等[85 ] 基于360条钢的数据样本,以疲劳强度、拉伸强度、断裂强度和硬度等为目标量,利用Multi-Task-Lasso特征筛选算法从17个材料参数中筛选出成分、制备工艺与夹杂物尺寸等同时满足4种力学性能预测的特征,利用符号回归建立了4种力学性能的数学表达式,分析发现增加Cr、Mo、Ni、Mn元素含量,以及降低回火温度、减少不连续夹杂物、提高淬火温度等有利于同时提升钢的4种力学性能. ...
Accelerating 2D MXene catalyst discovery for the hydrogen evolution reaction by computer-driven workflow and an ensemble learning strategy
1
2020
... 以材料特征为输入建立机器学习模型,往往遇到输入变量维数高、信息冗余严重的问题,带来维数灾难(curse of dimensionality),使数据变得稀疏或导致模型过拟合.为此,机器学习建模时通常需要对材料因子进行过滤和筛选,以降低数据维度,提高模型精度,增强模型泛化能力.在某些特殊情况下,利用材料理论和先验知识,选择合理的材料物理化学参量和数学运算法则,构建尽可能与目标量物理相关的材料因子也是提升模型精度和泛化能力的有效方法,有可能构建和筛选出具有潜在物理解释性的材料因子,辅助材料机制的理解,例如,通过特征构建与筛选,提出了钙钛矿催化材料析氧反应[15 ] 和二维MXenes催化材料析氢反应的描述符[16 ] ,寻找到了AB 2 C 型化合物具有Heusler结构概率[17 ] 的控制参量和双钙钛矿带隙的主要影响因素[18 ] 等. ...
High-throughput machine-learning-driven synthesis of Full-Heusler compounds
1
2016
... 以材料特征为输入建立机器学习模型,往往遇到输入变量维数高、信息冗余严重的问题,带来维数灾难(curse of dimensionality),使数据变得稀疏或导致模型过拟合.为此,机器学习建模时通常需要对材料因子进行过滤和筛选,以降低数据维度,提高模型精度,增强模型泛化能力.在某些特殊情况下,利用材料理论和先验知识,选择合理的材料物理化学参量和数学运算法则,构建尽可能与目标量物理相关的材料因子也是提升模型精度和泛化能力的有效方法,有可能构建和筛选出具有潜在物理解释性的材料因子,辅助材料机制的理解,例如,通过特征构建与筛选,提出了钙钛矿催化材料析氧反应[15 ] 和二维MXenes催化材料析氢反应的描述符[16 ] ,寻找到了AB 2 C 型化合物具有Heusler结构概率[17 ] 的控制参量和双钙钛矿带隙的主要影响因素[18 ] 等. ...
Machine learning bandgaps of double perovskites
1
2016
... 以材料特征为输入建立机器学习模型,往往遇到输入变量维数高、信息冗余严重的问题,带来维数灾难(curse of dimensionality),使数据变得稀疏或导致模型过拟合.为此,机器学习建模时通常需要对材料因子进行过滤和筛选,以降低数据维度,提高模型精度,增强模型泛化能力.在某些特殊情况下,利用材料理论和先验知识,选择合理的材料物理化学参量和数学运算法则,构建尽可能与目标量物理相关的材料因子也是提升模型精度和泛化能力的有效方法,有可能构建和筛选出具有潜在物理解释性的材料因子,辅助材料机制的理解,例如,通过特征构建与筛选,提出了钙钛矿催化材料析氧反应[15 ] 和二维MXenes催化材料析氢反应的描述符[16 ] ,寻找到了AB 2 C 型化合物具有Heusler结构概率[17 ] 的控制参量和双钙钛矿带隙的主要影响因素[18 ] 等. ...
Phase prediction of Ni-base superalloys via high-throughput experiments and machine learning
4
2021
... 高温合金包含γ 基体相、γ' 增强相、拓扑密排(TCP)相和几何密排(GCP)相等,TCP和GCP相是有害相,高温合金设计时应避免有害相的析出.Qin等[19 ] 利用材料高通量实验和微区X射线荧光光谱仪自动采集高温合金成分和显微组织信息,如图1 [19 ] 所示,快速获取了8371个镍基高温合金成分和相结构的数据样本,利用相关性筛选和递归特征消除法筛选出了混合熵、原子尺寸差、熔点和价电子数等材料因子,建立了线性模型(linear model)、K近邻(k-nearest neighbor)、梯度提升树(gradient boosting decision tree)、决策树(decision tree)、随机森林(random forest)和支持向量机(support vector machine)等6个分类模型,发现K近邻模型具有较高的精度,预测TCP和GCP的受试者工作特征(receiver operating characteristic,ROC)曲线下面积总和值(area under roc curve,AUC)分别为0.88和0.92.Zou等[20 ] 利用扩散多元节实验获得了2275个钴基高温合金成分与相结构数据样本,以合金成分为特征,建立了预测有害相析出的梯度提升树分类模型(平衡F分数为0.972)和预测γ' 相体积分数的梯度提升树回归模型(决定系数R 2 为0.954),设计出了1000℃时效24 h无有害相析出、γ' 相体积分数为79.8%的新型九元钴基高温合金.Yu等[21 ] 利用458个实验数据样本,以成分、时效温度和时效时间等23个材料参数为特征,通过主成分分析降维,建立了是否存在γ' 相的随机森林分类模型,预测准确率超过95%,设计出了一系列含γ' 相的Co-Ti-V基四元合金. ...
... [19 ]所示,快速获取了8371个镍基高温合金成分和相结构的数据样本,利用相关性筛选和递归特征消除法筛选出了混合熵、原子尺寸差、熔点和价电子数等材料因子,建立了线性模型(linear model)、K近邻(k-nearest neighbor)、梯度提升树(gradient boosting decision tree)、决策树(decision tree)、随机森林(random forest)和支持向量机(support vector machine)等6个分类模型,发现K近邻模型具有较高的精度,预测TCP和GCP的受试者工作特征(receiver operating characteristic,ROC)曲线下面积总和值(area under roc curve,AUC)分别为0.88和0.92.Zou等[20 ] 利用扩散多元节实验获得了2275个钴基高温合金成分与相结构数据样本,以合金成分为特征,建立了预测有害相析出的梯度提升树分类模型(平衡F分数为0.972)和预测γ' 相体积分数的梯度提升树回归模型(决定系数R 2 为0.954),设计出了1000℃时效24 h无有害相析出、γ' 相体积分数为79.8%的新型九元钴基高温合金.Yu等[21 ] 利用458个实验数据样本,以成分、时效温度和时效时间等23个材料参数为特征,通过主成分分析降维,建立了是否存在γ' 相的随机森林分类模型,预测准确率超过95%,设计出了一系列含γ' 相的Co-Ti-V基四元合金. ...
... [
19 ]
Schematic workflow of phase prediction via high-throughput experiments and machine learning of Ni-base superalloys<sup>[<xref ref-type="bibr" rid="R19">19</xref>]</sup> (TCP—topologically close-packed, GCP—geometric close-packed) Fig.1 ![]()
机器学习广泛应用于高熵合金的相分类和相结构预测,指导高熵合金的设计和研发[22 ~32 ] .Zhang等[32 ] 以原子半径、熔化温度、混合熵,以及高熵合金相形成的经验参数为特征,利用遗传算法筛选材料特征与机器学习模型组合,建立了高精度高熵合金相分类模型.Li和Guo[22 ] 基于322个铸态高熵合金数据样本,通过顺序选择法筛选出价电子浓度、原子尺寸差、熔化温度、混合焓和混合熵等5个材料因子为特征,建立支持向量机分类模型,模型对高熵合金体心立方单相、面心立方单相和不形成单相固溶体的分类准确率达90%以上.Huang等[31 ] 基于401个高熵合金数据样本,以价电子数、电负性错配、原子尺寸错配、混合熵和混合焓等为特征,建立了K近邻、支持向量机、神经网络等分类模型,对高熵合金是否形成单相固溶体、金属间化合物、固溶体+金属间化合物相进行预测,交叉验证得到的3种模型三分类的预测准确率分别有68.6%、64.3%和74.3%,通过自组织映射神经网络(SOM)发现造成分类准确率偏低的原因是固溶体和固溶体+金属间化合物的相间边界不清晰,进而利用多层神经网络(MLFFNN)分别建立了固溶体和金属间化合物、固溶体+金属间化合物和金属间化合物、固溶体和固溶体+金属间化合物等的二分类模型,分类准确率分别为86.7%、94.3%和78.9%.Lee等[25 ] 基于989个高熵合金数据样本(250个固溶体高熵合金,267个固溶体+金属间化合物相高熵合金,307个金属间化合物相,165个非晶相高熵合金),利用原子尺寸差、平均熔化温度、体积模量等13个特征,建立了高熵合金深度神经网络分类模型,为了弥补实验数据的不足,利用条件生成对抗性网络(CGAN)生成额外的高熵合金数据,将分类准确率从84.75%提升到了93.17%. ...
... [
19 ] (TCP—topologically close-packed, GCP—geometric close-packed)
Fig.1 ![]()
机器学习广泛应用于高熵合金的相分类和相结构预测,指导高熵合金的设计和研发[22 ~32 ] .Zhang等[32 ] 以原子半径、熔化温度、混合熵,以及高熵合金相形成的经验参数为特征,利用遗传算法筛选材料特征与机器学习模型组合,建立了高精度高熵合金相分类模型.Li和Guo[22 ] 基于322个铸态高熵合金数据样本,通过顺序选择法筛选出价电子浓度、原子尺寸差、熔化温度、混合焓和混合熵等5个材料因子为特征,建立支持向量机分类模型,模型对高熵合金体心立方单相、面心立方单相和不形成单相固溶体的分类准确率达90%以上.Huang等[31 ] 基于401个高熵合金数据样本,以价电子数、电负性错配、原子尺寸错配、混合熵和混合焓等为特征,建立了K近邻、支持向量机、神经网络等分类模型,对高熵合金是否形成单相固溶体、金属间化合物、固溶体+金属间化合物相进行预测,交叉验证得到的3种模型三分类的预测准确率分别有68.6%、64.3%和74.3%,通过自组织映射神经网络(SOM)发现造成分类准确率偏低的原因是固溶体和固溶体+金属间化合物的相间边界不清晰,进而利用多层神经网络(MLFFNN)分别建立了固溶体和金属间化合物、固溶体+金属间化合物和金属间化合物、固溶体和固溶体+金属间化合物等的二分类模型,分类准确率分别为86.7%、94.3%和78.9%.Lee等[25 ] 基于989个高熵合金数据样本(250个固溶体高熵合金,267个固溶体+金属间化合物相高熵合金,307个金属间化合物相,165个非晶相高熵合金),利用原子尺寸差、平均熔化温度、体积模量等13个特征,建立了高熵合金深度神经网络分类模型,为了弥补实验数据的不足,利用条件生成对抗性网络(CGAN)生成额外的高熵合金数据,将分类准确率从84.75%提升到了93.17%. ...
Machine learning assisted design approach for developing γ′ -strengthened Co-Ni-base superalloys
1
2020
... 高温合金包含γ 基体相、γ' 增强相、拓扑密排(TCP)相和几何密排(GCP)相等,TCP和GCP相是有害相,高温合金设计时应避免有害相的析出.Qin等[19 ] 利用材料高通量实验和微区X射线荧光光谱仪自动采集高温合金成分和显微组织信息,如图1 [19 ] 所示,快速获取了8371个镍基高温合金成分和相结构的数据样本,利用相关性筛选和递归特征消除法筛选出了混合熵、原子尺寸差、熔点和价电子数等材料因子,建立了线性模型(linear model)、K近邻(k-nearest neighbor)、梯度提升树(gradient boosting decision tree)、决策树(decision tree)、随机森林(random forest)和支持向量机(support vector machine)等6个分类模型,发现K近邻模型具有较高的精度,预测TCP和GCP的受试者工作特征(receiver operating characteristic,ROC)曲线下面积总和值(area under roc curve,AUC)分别为0.88和0.92.Zou等[20 ] 利用扩散多元节实验获得了2275个钴基高温合金成分与相结构数据样本,以合金成分为特征,建立了预测有害相析出的梯度提升树分类模型(平衡F分数为0.972)和预测γ' 相体积分数的梯度提升树回归模型(决定系数R 2 为0.954),设计出了1000℃时效24 h无有害相析出、γ' 相体积分数为79.8%的新型九元钴基高温合金.Yu等[21 ] 利用458个实验数据样本,以成分、时效温度和时效时间等23个材料参数为特征,通过主成分分析降维,建立了是否存在γ' 相的随机森林分类模型,预测准确率超过95%,设计出了一系列含γ' 相的Co-Ti-V基四元合金. ...
A two-stage predicting model for γ′ solvus temperature of L 12 -strengthened Co-base superalloys based on machine learning
1
2019
... 高温合金包含γ 基体相、γ' 增强相、拓扑密排(TCP)相和几何密排(GCP)相等,TCP和GCP相是有害相,高温合金设计时应避免有害相的析出.Qin等[19 ] 利用材料高通量实验和微区X射线荧光光谱仪自动采集高温合金成分和显微组织信息,如图1 [19 ] 所示,快速获取了8371个镍基高温合金成分和相结构的数据样本,利用相关性筛选和递归特征消除法筛选出了混合熵、原子尺寸差、熔点和价电子数等材料因子,建立了线性模型(linear model)、K近邻(k-nearest neighbor)、梯度提升树(gradient boosting decision tree)、决策树(decision tree)、随机森林(random forest)和支持向量机(support vector machine)等6个分类模型,发现K近邻模型具有较高的精度,预测TCP和GCP的受试者工作特征(receiver operating characteristic,ROC)曲线下面积总和值(area under roc curve,AUC)分别为0.88和0.92.Zou等[20 ] 利用扩散多元节实验获得了2275个钴基高温合金成分与相结构数据样本,以合金成分为特征,建立了预测有害相析出的梯度提升树分类模型(平衡F分数为0.972)和预测γ' 相体积分数的梯度提升树回归模型(决定系数R 2 为0.954),设计出了1000℃时效24 h无有害相析出、γ' 相体积分数为79.8%的新型九元钴基高温合金.Yu等[21 ] 利用458个实验数据样本,以成分、时效温度和时效时间等23个材料参数为特征,通过主成分分析降维,建立了是否存在γ' 相的随机森林分类模型,预测准确率超过95%,设计出了一系列含γ' 相的Co-Ti-V基四元合金. ...
Machine-learning model for predicting phase forma-tions of high-entropy alloys
2
2019
... 机器学习广泛应用于高熵合金的相分类和相结构预测,指导高熵合金的设计和研发[22 ~32 ] .Zhang等[32 ] 以原子半径、熔化温度、混合熵,以及高熵合金相形成的经验参数为特征,利用遗传算法筛选材料特征与机器学习模型组合,建立了高精度高熵合金相分类模型.Li和Guo[22 ] 基于322个铸态高熵合金数据样本,通过顺序选择法筛选出价电子浓度、原子尺寸差、熔化温度、混合焓和混合熵等5个材料因子为特征,建立支持向量机分类模型,模型对高熵合金体心立方单相、面心立方单相和不形成单相固溶体的分类准确率达90%以上.Huang等[31 ] 基于401个高熵合金数据样本,以价电子数、电负性错配、原子尺寸错配、混合熵和混合焓等为特征,建立了K近邻、支持向量机、神经网络等分类模型,对高熵合金是否形成单相固溶体、金属间化合物、固溶体+金属间化合物相进行预测,交叉验证得到的3种模型三分类的预测准确率分别有68.6%、64.3%和74.3%,通过自组织映射神经网络(SOM)发现造成分类准确率偏低的原因是固溶体和固溶体+金属间化合物的相间边界不清晰,进而利用多层神经网络(MLFFNN)分别建立了固溶体和金属间化合物、固溶体+金属间化合物和金属间化合物、固溶体和固溶体+金属间化合物等的二分类模型,分类准确率分别为86.7%、94.3%和78.9%.Lee等[25 ] 基于989个高熵合金数据样本(250个固溶体高熵合金,267个固溶体+金属间化合物相高熵合金,307个金属间化合物相,165个非晶相高熵合金),利用原子尺寸差、平均熔化温度、体积模量等13个特征,建立了高熵合金深度神经网络分类模型,为了弥补实验数据的不足,利用条件生成对抗性网络(CGAN)生成额外的高熵合金数据,将分类准确率从84.75%提升到了93.17%. ...
... [22 ]基于322个铸态高熵合金数据样本,通过顺序选择法筛选出价电子浓度、原子尺寸差、熔化温度、混合焓和混合熵等5个材料因子为特征,建立支持向量机分类模型,模型对高熵合金体心立方单相、面心立方单相和不形成单相固溶体的分类准确率达90%以上.Huang等[31 ] 基于401个高熵合金数据样本,以价电子数、电负性错配、原子尺寸错配、混合熵和混合焓等为特征,建立了K近邻、支持向量机、神经网络等分类模型,对高熵合金是否形成单相固溶体、金属间化合物、固溶体+金属间化合物相进行预测,交叉验证得到的3种模型三分类的预测准确率分别有68.6%、64.3%和74.3%,通过自组织映射神经网络(SOM)发现造成分类准确率偏低的原因是固溶体和固溶体+金属间化合物的相间边界不清晰,进而利用多层神经网络(MLFFNN)分别建立了固溶体和金属间化合物、固溶体+金属间化合物和金属间化合物、固溶体和固溶体+金属间化合物等的二分类模型,分类准确率分别为86.7%、94.3%和78.9%.Lee等[25 ] 基于989个高熵合金数据样本(250个固溶体高熵合金,267个固溶体+金属间化合物相高熵合金,307个金属间化合物相,165个非晶相高熵合金),利用原子尺寸差、平均熔化温度、体积模量等13个特征,建立了高熵合金深度神经网络分类模型,为了弥补实验数据的不足,利用条件生成对抗性网络(CGAN)生成额外的高熵合金数据,将分类准确率从84.75%提升到了93.17%. ...
Machine learning guided appraisal and exploration of phase design for high entropy alloys
0
2019
Searching for high entropy alloys: A machine learning approach
0
2020
Deep learning-based phase prediction of high-entropy alloys: Optimization, generation, and explanation
1
2021
... 机器学习广泛应用于高熵合金的相分类和相结构预测,指导高熵合金的设计和研发[22 ~32 ] .Zhang等[32 ] 以原子半径、熔化温度、混合熵,以及高熵合金相形成的经验参数为特征,利用遗传算法筛选材料特征与机器学习模型组合,建立了高精度高熵合金相分类模型.Li和Guo[22 ] 基于322个铸态高熵合金数据样本,通过顺序选择法筛选出价电子浓度、原子尺寸差、熔化温度、混合焓和混合熵等5个材料因子为特征,建立支持向量机分类模型,模型对高熵合金体心立方单相、面心立方单相和不形成单相固溶体的分类准确率达90%以上.Huang等[31 ] 基于401个高熵合金数据样本,以价电子数、电负性错配、原子尺寸错配、混合熵和混合焓等为特征,建立了K近邻、支持向量机、神经网络等分类模型,对高熵合金是否形成单相固溶体、金属间化合物、固溶体+金属间化合物相进行预测,交叉验证得到的3种模型三分类的预测准确率分别有68.6%、64.3%和74.3%,通过自组织映射神经网络(SOM)发现造成分类准确率偏低的原因是固溶体和固溶体+金属间化合物的相间边界不清晰,进而利用多层神经网络(MLFFNN)分别建立了固溶体和金属间化合物、固溶体+金属间化合物和金属间化合物、固溶体和固溶体+金属间化合物等的二分类模型,分类准确率分别为86.7%、94.3%和78.9%.Lee等[25 ] 基于989个高熵合金数据样本(250个固溶体高熵合金,267个固溶体+金属间化合物相高熵合金,307个金属间化合物相,165个非晶相高熵合金),利用原子尺寸差、平均熔化温度、体积模量等13个特征,建立了高熵合金深度神经网络分类模型,为了弥补实验数据的不足,利用条件生成对抗性网络(CGAN)生成额外的高熵合金数据,将分类准确率从84.75%提升到了93.17%. ...
Improving phase prediction accuracy for high entropy alloys with machine learning
0
2021
Predictive descriptors in machine learning and data-enabled explorations of high-entropy alloys
0
2021
Machine learning approach to predict new multiphase high entropy alloys
0
2021
Machine learning-enabled identification of new medium to high entropy alloys with solid solution phases
0
2021
Accelerated discovery of single-phase refractory high entropy alloys assisted by machine learning
0
2021
Machine-learning phase prediction of high-entropy alloys
1
2019
... 机器学习广泛应用于高熵合金的相分类和相结构预测,指导高熵合金的设计和研发[22 ~32 ] .Zhang等[32 ] 以原子半径、熔化温度、混合熵,以及高熵合金相形成的经验参数为特征,利用遗传算法筛选材料特征与机器学习模型组合,建立了高精度高熵合金相分类模型.Li和Guo[22 ] 基于322个铸态高熵合金数据样本,通过顺序选择法筛选出价电子浓度、原子尺寸差、熔化温度、混合焓和混合熵等5个材料因子为特征,建立支持向量机分类模型,模型对高熵合金体心立方单相、面心立方单相和不形成单相固溶体的分类准确率达90%以上.Huang等[31 ] 基于401个高熵合金数据样本,以价电子数、电负性错配、原子尺寸错配、混合熵和混合焓等为特征,建立了K近邻、支持向量机、神经网络等分类模型,对高熵合金是否形成单相固溶体、金属间化合物、固溶体+金属间化合物相进行预测,交叉验证得到的3种模型三分类的预测准确率分别有68.6%、64.3%和74.3%,通过自组织映射神经网络(SOM)发现造成分类准确率偏低的原因是固溶体和固溶体+金属间化合物的相间边界不清晰,进而利用多层神经网络(MLFFNN)分别建立了固溶体和金属间化合物、固溶体+金属间化合物和金属间化合物、固溶体和固溶体+金属间化合物等的二分类模型,分类准确率分别为86.7%、94.3%和78.9%.Lee等[25 ] 基于989个高熵合金数据样本(250个固溶体高熵合金,267个固溶体+金属间化合物相高熵合金,307个金属间化合物相,165个非晶相高熵合金),利用原子尺寸差、平均熔化温度、体积模量等13个特征,建立了高熵合金深度神经网络分类模型,为了弥补实验数据的不足,利用条件生成对抗性网络(CGAN)生成额外的高熵合金数据,将分类准确率从84.75%提升到了93.17%. ...
Phase prediction in high entropy alloys with a rational selection of materials descriptors and machine learning models
2
2020
... 机器学习广泛应用于高熵合金的相分类和相结构预测,指导高熵合金的设计和研发[22 ~32 ] .Zhang等[32 ] 以原子半径、熔化温度、混合熵,以及高熵合金相形成的经验参数为特征,利用遗传算法筛选材料特征与机器学习模型组合,建立了高精度高熵合金相分类模型.Li和Guo[22 ] 基于322个铸态高熵合金数据样本,通过顺序选择法筛选出价电子浓度、原子尺寸差、熔化温度、混合焓和混合熵等5个材料因子为特征,建立支持向量机分类模型,模型对高熵合金体心立方单相、面心立方单相和不形成单相固溶体的分类准确率达90%以上.Huang等[31 ] 基于401个高熵合金数据样本,以价电子数、电负性错配、原子尺寸错配、混合熵和混合焓等为特征,建立了K近邻、支持向量机、神经网络等分类模型,对高熵合金是否形成单相固溶体、金属间化合物、固溶体+金属间化合物相进行预测,交叉验证得到的3种模型三分类的预测准确率分别有68.6%、64.3%和74.3%,通过自组织映射神经网络(SOM)发现造成分类准确率偏低的原因是固溶体和固溶体+金属间化合物的相间边界不清晰,进而利用多层神经网络(MLFFNN)分别建立了固溶体和金属间化合物、固溶体+金属间化合物和金属间化合物、固溶体和固溶体+金属间化合物等的二分类模型,分类准确率分别为86.7%、94.3%和78.9%.Lee等[25 ] 基于989个高熵合金数据样本(250个固溶体高熵合金,267个固溶体+金属间化合物相高熵合金,307个金属间化合物相,165个非晶相高熵合金),利用原子尺寸差、平均熔化温度、体积模量等13个特征,建立了高熵合金深度神经网络分类模型,为了弥补实验数据的不足,利用条件生成对抗性网络(CGAN)生成额外的高熵合金数据,将分类准确率从84.75%提升到了93.17%. ...
... [32 ]以原子半径、熔化温度、混合熵,以及高熵合金相形成的经验参数为特征,利用遗传算法筛选材料特征与机器学习模型组合,建立了高精度高熵合金相分类模型.Li和Guo[22 ] 基于322个铸态高熵合金数据样本,通过顺序选择法筛选出价电子浓度、原子尺寸差、熔化温度、混合焓和混合熵等5个材料因子为特征,建立支持向量机分类模型,模型对高熵合金体心立方单相、面心立方单相和不形成单相固溶体的分类准确率达90%以上.Huang等[31 ] 基于401个高熵合金数据样本,以价电子数、电负性错配、原子尺寸错配、混合熵和混合焓等为特征,建立了K近邻、支持向量机、神经网络等分类模型,对高熵合金是否形成单相固溶体、金属间化合物、固溶体+金属间化合物相进行预测,交叉验证得到的3种模型三分类的预测准确率分别有68.6%、64.3%和74.3%,通过自组织映射神经网络(SOM)发现造成分类准确率偏低的原因是固溶体和固溶体+金属间化合物的相间边界不清晰,进而利用多层神经网络(MLFFNN)分别建立了固溶体和金属间化合物、固溶体+金属间化合物和金属间化合物、固溶体和固溶体+金属间化合物等的二分类模型,分类准确率分别为86.7%、94.3%和78.9%.Lee等[25 ] 基于989个高熵合金数据样本(250个固溶体高熵合金,267个固溶体+金属间化合物相高熵合金,307个金属间化合物相,165个非晶相高熵合金),利用原子尺寸差、平均熔化温度、体积模量等13个特征,建立了高熵合金深度神经网络分类模型,为了弥补实验数据的不足,利用条件生成对抗性网络(CGAN)生成额外的高熵合金数据,将分类准确率从84.75%提升到了93.17%. ...
Machine learning prediction of elastic properties and glass-forming ability of bulk metallic glasses
1
2019
... 非晶形成能力尚没有明确的定义和科学的实验表征方法,冷却速率是最直接可量化非晶形成能力的实验手段,但实验测量困难.因此,利用能够形成非晶的数据样本,建立机器学习分类模型,深入分析模型的材料特征,辅助理解非晶形成能力的物理机制,指导非晶设计,是非晶领域机器学习的研究热点[33 ~40 ] .Xiong等[35 ] 基于6471个数据样本(1211个块体非晶合金,1552个带状非晶合金和3708个晶态合金),利用合金元素电子、原子和热力学参数构建合金因子,通过相关系数筛选、方差分析、顺序选择法等三步特征筛选,筛选出平均价电子数、s轨道电子数、熔化焓差、沸点、元素族数和功函数差等6个特征,建立的随机森林分类模型准确率为88.13%,根据预测结果,从13种带状非晶合金中成功发现了5种新的块体非晶合金,并进行了实验验证.Xiong等[34 ] 还利用非晶形成临界直径在1~40 mm的695个块体非晶合金数据样本,将数据分成376个临界直径在1~5 mm的低非晶形成能力(L-GFA)和319个临界直径大于5 mm的高非晶形成能力(G-GFA) 2个数据样本集,分别建立极端梯度提升树(XGboost)分类模型对2个数据样本集进行分类,同时,对G-GFA数据样本集进行回归,以便更准确地预测具有高非晶形成能力的合金临界直径.Sun等[38 ] 基于339个利用甩带方式形成非晶合金和1131组二元非晶合金数据样本,选取原子质量、混合焓、原子半径、单质材料的液化温度、虚拟液化温度、液化温差、元素含量等构建合金因子,建立支持向量机分类模型,对二元合金的非晶形成能力进行预测和分析,发现液相线温度是二元合金非晶形成能力的关键参量.采用机器学习辅助方法还提出了许多预测合金非晶形成能力的准则和参数,如混合熵、混合焓、过冷液体温度区间、约化玻璃转化温度、黏度、临界冷却速率等,通过建立回归模型预测非晶的形成能力[34 ~37 , 39 ~41 ] .Xiong等[35 ] 基于6000个涵盖非晶类型、非晶形成临界直径、非晶特征转变温度(如玻璃化转变温度、约化玻璃转变温度、液相线温度)和弹性性能等数据样本,利用符号回归建立了以原子体积和Pauling电负性为变量的体积模量正相关的合金因子,以原子体积和混合熵为变量的剪切模量正相关的合金因子,以及分别以混合焓、混合熵、热导率等为变量和以玻璃转变温度、晶化温度、液相线温度等为变量的非晶形成临界直径的合金因子,利用最小二乘法拟合建立了非晶形成临界直径与上述4个合金因子的数学表达式.根据该数学表达式,提出了指导大尺寸块状非晶合金筛选的原则是具有高的混合熵、高的平均热导率和适中的混合焓,非晶合金特征转变温度与合金组元的平均熔点强相关,非晶合金剪切模量和体积模量与合金的平均原子体积呈负相关等. ...
Machine learning prediction of glass-forming ability in bulk metallic glasses
2
2021
... 非晶形成能力尚没有明确的定义和科学的实验表征方法,冷却速率是最直接可量化非晶形成能力的实验手段,但实验测量困难.因此,利用能够形成非晶的数据样本,建立机器学习分类模型,深入分析模型的材料特征,辅助理解非晶形成能力的物理机制,指导非晶设计,是非晶领域机器学习的研究热点[33 ~40 ] .Xiong等[35 ] 基于6471个数据样本(1211个块体非晶合金,1552个带状非晶合金和3708个晶态合金),利用合金元素电子、原子和热力学参数构建合金因子,通过相关系数筛选、方差分析、顺序选择法等三步特征筛选,筛选出平均价电子数、s轨道电子数、熔化焓差、沸点、元素族数和功函数差等6个特征,建立的随机森林分类模型准确率为88.13%,根据预测结果,从13种带状非晶合金中成功发现了5种新的块体非晶合金,并进行了实验验证.Xiong等[34 ] 还利用非晶形成临界直径在1~40 mm的695个块体非晶合金数据样本,将数据分成376个临界直径在1~5 mm的低非晶形成能力(L-GFA)和319个临界直径大于5 mm的高非晶形成能力(G-GFA) 2个数据样本集,分别建立极端梯度提升树(XGboost)分类模型对2个数据样本集进行分类,同时,对G-GFA数据样本集进行回归,以便更准确地预测具有高非晶形成能力的合金临界直径.Sun等[38 ] 基于339个利用甩带方式形成非晶合金和1131组二元非晶合金数据样本,选取原子质量、混合焓、原子半径、单质材料的液化温度、虚拟液化温度、液化温差、元素含量等构建合金因子,建立支持向量机分类模型,对二元合金的非晶形成能力进行预测和分析,发现液相线温度是二元合金非晶形成能力的关键参量.采用机器学习辅助方法还提出了许多预测合金非晶形成能力的准则和参数,如混合熵、混合焓、过冷液体温度区间、约化玻璃转化温度、黏度、临界冷却速率等,通过建立回归模型预测非晶的形成能力[34 ~37 , 39 ~41 ] .Xiong等[35 ] 基于6000个涵盖非晶类型、非晶形成临界直径、非晶特征转变温度(如玻璃化转变温度、约化玻璃转变温度、液相线温度)和弹性性能等数据样本,利用符号回归建立了以原子体积和Pauling电负性为变量的体积模量正相关的合金因子,以原子体积和混合熵为变量的剪切模量正相关的合金因子,以及分别以混合焓、混合熵、热导率等为变量和以玻璃转变温度、晶化温度、液相线温度等为变量的非晶形成临界直径的合金因子,利用最小二乘法拟合建立了非晶形成临界直径与上述4个合金因子的数学表达式.根据该数学表达式,提出了指导大尺寸块状非晶合金筛选的原则是具有高的混合熵、高的平均热导率和适中的混合焓,非晶合金特征转变温度与合金组元的平均熔点强相关,非晶合金剪切模量和体积模量与合金的平均原子体积呈负相关等. ...
... [34 ~37 , 39 ~41 ].Xiong等[35 ] 基于6000个涵盖非晶类型、非晶形成临界直径、非晶特征转变温度(如玻璃化转变温度、约化玻璃转变温度、液相线温度)和弹性性能等数据样本,利用符号回归建立了以原子体积和Pauling电负性为变量的体积模量正相关的合金因子,以原子体积和混合熵为变量的剪切模量正相关的合金因子,以及分别以混合焓、混合熵、热导率等为变量和以玻璃转变温度、晶化温度、液相线温度等为变量的非晶形成临界直径的合金因子,利用最小二乘法拟合建立了非晶形成临界直径与上述4个合金因子的数学表达式.根据该数学表达式,提出了指导大尺寸块状非晶合金筛选的原则是具有高的混合熵、高的平均热导率和适中的混合焓,非晶合金特征转变温度与合金组元的平均熔点强相关,非晶合金剪切模量和体积模量与合金的平均原子体积呈负相关等. ...
A machine-learning approach to predicting and understanding the properties of amorphous metallic alloys
2
2020
... 非晶形成能力尚没有明确的定义和科学的实验表征方法,冷却速率是最直接可量化非晶形成能力的实验手段,但实验测量困难.因此,利用能够形成非晶的数据样本,建立机器学习分类模型,深入分析模型的材料特征,辅助理解非晶形成能力的物理机制,指导非晶设计,是非晶领域机器学习的研究热点[33 ~40 ] .Xiong等[35 ] 基于6471个数据样本(1211个块体非晶合金,1552个带状非晶合金和3708个晶态合金),利用合金元素电子、原子和热力学参数构建合金因子,通过相关系数筛选、方差分析、顺序选择法等三步特征筛选,筛选出平均价电子数、s轨道电子数、熔化焓差、沸点、元素族数和功函数差等6个特征,建立的随机森林分类模型准确率为88.13%,根据预测结果,从13种带状非晶合金中成功发现了5种新的块体非晶合金,并进行了实验验证.Xiong等[34 ] 还利用非晶形成临界直径在1~40 mm的695个块体非晶合金数据样本,将数据分成376个临界直径在1~5 mm的低非晶形成能力(L-GFA)和319个临界直径大于5 mm的高非晶形成能力(G-GFA) 2个数据样本集,分别建立极端梯度提升树(XGboost)分类模型对2个数据样本集进行分类,同时,对G-GFA数据样本集进行回归,以便更准确地预测具有高非晶形成能力的合金临界直径.Sun等[38 ] 基于339个利用甩带方式形成非晶合金和1131组二元非晶合金数据样本,选取原子质量、混合焓、原子半径、单质材料的液化温度、虚拟液化温度、液化温差、元素含量等构建合金因子,建立支持向量机分类模型,对二元合金的非晶形成能力进行预测和分析,发现液相线温度是二元合金非晶形成能力的关键参量.采用机器学习辅助方法还提出了许多预测合金非晶形成能力的准则和参数,如混合熵、混合焓、过冷液体温度区间、约化玻璃转化温度、黏度、临界冷却速率等,通过建立回归模型预测非晶的形成能力[34 ~37 , 39 ~41 ] .Xiong等[35 ] 基于6000个涵盖非晶类型、非晶形成临界直径、非晶特征转变温度(如玻璃化转变温度、约化玻璃转变温度、液相线温度)和弹性性能等数据样本,利用符号回归建立了以原子体积和Pauling电负性为变量的体积模量正相关的合金因子,以原子体积和混合熵为变量的剪切模量正相关的合金因子,以及分别以混合焓、混合熵、热导率等为变量和以玻璃转变温度、晶化温度、液相线温度等为变量的非晶形成临界直径的合金因子,利用最小二乘法拟合建立了非晶形成临界直径与上述4个合金因子的数学表达式.根据该数学表达式,提出了指导大尺寸块状非晶合金筛选的原则是具有高的混合熵、高的平均热导率和适中的混合焓,非晶合金特征转变温度与合金组元的平均熔点强相关,非晶合金剪切模量和体积模量与合金的平均原子体积呈负相关等. ...
... [35 ]基于6000个涵盖非晶类型、非晶形成临界直径、非晶特征转变温度(如玻璃化转变温度、约化玻璃转变温度、液相线温度)和弹性性能等数据样本,利用符号回归建立了以原子体积和Pauling电负性为变量的体积模量正相关的合金因子,以原子体积和混合熵为变量的剪切模量正相关的合金因子,以及分别以混合焓、混合熵、热导率等为变量和以玻璃转变温度、晶化温度、液相线温度等为变量的非晶形成临界直径的合金因子,利用最小二乘法拟合建立了非晶形成临界直径与上述4个合金因子的数学表达式.根据该数学表达式,提出了指导大尺寸块状非晶合金筛选的原则是具有高的混合熵、高的平均热导率和适中的混合焓,非晶合金特征转变温度与合金组元的平均熔点强相关,非晶合金剪切模量和体积模量与合金的平均原子体积呈负相关等. ...
A machine learning approach for engineering bulk metallic glass alloys
0
2018
Multivariate analysis and classification of bulk metallic glasses using principal component analysis
1
2015
... 非晶形成能力尚没有明确的定义和科学的实验表征方法,冷却速率是最直接可量化非晶形成能力的实验手段,但实验测量困难.因此,利用能够形成非晶的数据样本,建立机器学习分类模型,深入分析模型的材料特征,辅助理解非晶形成能力的物理机制,指导非晶设计,是非晶领域机器学习的研究热点[33 ~40 ] .Xiong等[35 ] 基于6471个数据样本(1211个块体非晶合金,1552个带状非晶合金和3708个晶态合金),利用合金元素电子、原子和热力学参数构建合金因子,通过相关系数筛选、方差分析、顺序选择法等三步特征筛选,筛选出平均价电子数、s轨道电子数、熔化焓差、沸点、元素族数和功函数差等6个特征,建立的随机森林分类模型准确率为88.13%,根据预测结果,从13种带状非晶合金中成功发现了5种新的块体非晶合金,并进行了实验验证.Xiong等[34 ] 还利用非晶形成临界直径在1~40 mm的695个块体非晶合金数据样本,将数据分成376个临界直径在1~5 mm的低非晶形成能力(L-GFA)和319个临界直径大于5 mm的高非晶形成能力(G-GFA) 2个数据样本集,分别建立极端梯度提升树(XGboost)分类模型对2个数据样本集进行分类,同时,对G-GFA数据样本集进行回归,以便更准确地预测具有高非晶形成能力的合金临界直径.Sun等[38 ] 基于339个利用甩带方式形成非晶合金和1131组二元非晶合金数据样本,选取原子质量、混合焓、原子半径、单质材料的液化温度、虚拟液化温度、液化温差、元素含量等构建合金因子,建立支持向量机分类模型,对二元合金的非晶形成能力进行预测和分析,发现液相线温度是二元合金非晶形成能力的关键参量.采用机器学习辅助方法还提出了许多预测合金非晶形成能力的准则和参数,如混合熵、混合焓、过冷液体温度区间、约化玻璃转化温度、黏度、临界冷却速率等,通过建立回归模型预测非晶的形成能力[34 ~37 , 39 ~41 ] .Xiong等[35 ] 基于6000个涵盖非晶类型、非晶形成临界直径、非晶特征转变温度(如玻璃化转变温度、约化玻璃转变温度、液相线温度)和弹性性能等数据样本,利用符号回归建立了以原子体积和Pauling电负性为变量的体积模量正相关的合金因子,以原子体积和混合熵为变量的剪切模量正相关的合金因子,以及分别以混合焓、混合熵、热导率等为变量和以玻璃转变温度、晶化温度、液相线温度等为变量的非晶形成临界直径的合金因子,利用最小二乘法拟合建立了非晶形成临界直径与上述4个合金因子的数学表达式.根据该数学表达式,提出了指导大尺寸块状非晶合金筛选的原则是具有高的混合熵、高的平均热导率和适中的混合焓,非晶合金特征转变温度与合金组元的平均熔点强相关,非晶合金剪切模量和体积模量与合金的平均原子体积呈负相关等. ...
Machine learning approach for prediction and understanding of glass-forming ability
1
2017
... 非晶形成能力尚没有明确的定义和科学的实验表征方法,冷却速率是最直接可量化非晶形成能力的实验手段,但实验测量困难.因此,利用能够形成非晶的数据样本,建立机器学习分类模型,深入分析模型的材料特征,辅助理解非晶形成能力的物理机制,指导非晶设计,是非晶领域机器学习的研究热点[33 ~40 ] .Xiong等[35 ] 基于6471个数据样本(1211个块体非晶合金,1552个带状非晶合金和3708个晶态合金),利用合金元素电子、原子和热力学参数构建合金因子,通过相关系数筛选、方差分析、顺序选择法等三步特征筛选,筛选出平均价电子数、s轨道电子数、熔化焓差、沸点、元素族数和功函数差等6个特征,建立的随机森林分类模型准确率为88.13%,根据预测结果,从13种带状非晶合金中成功发现了5种新的块体非晶合金,并进行了实验验证.Xiong等[34 ] 还利用非晶形成临界直径在1~40 mm的695个块体非晶合金数据样本,将数据分成376个临界直径在1~5 mm的低非晶形成能力(L-GFA)和319个临界直径大于5 mm的高非晶形成能力(G-GFA) 2个数据样本集,分别建立极端梯度提升树(XGboost)分类模型对2个数据样本集进行分类,同时,对G-GFA数据样本集进行回归,以便更准确地预测具有高非晶形成能力的合金临界直径.Sun等[38 ] 基于339个利用甩带方式形成非晶合金和1131组二元非晶合金数据样本,选取原子质量、混合焓、原子半径、单质材料的液化温度、虚拟液化温度、液化温差、元素含量等构建合金因子,建立支持向量机分类模型,对二元合金的非晶形成能力进行预测和分析,发现液相线温度是二元合金非晶形成能力的关键参量.采用机器学习辅助方法还提出了许多预测合金非晶形成能力的准则和参数,如混合熵、混合焓、过冷液体温度区间、约化玻璃转化温度、黏度、临界冷却速率等,通过建立回归模型预测非晶的形成能力[34 ~37 , 39 ~41 ] .Xiong等[35 ] 基于6000个涵盖非晶类型、非晶形成临界直径、非晶特征转变温度(如玻璃化转变温度、约化玻璃转变温度、液相线温度)和弹性性能等数据样本,利用符号回归建立了以原子体积和Pauling电负性为变量的体积模量正相关的合金因子,以原子体积和混合熵为变量的剪切模量正相关的合金因子,以及分别以混合焓、混合熵、热导率等为变量和以玻璃转变温度、晶化温度、液相线温度等为变量的非晶形成临界直径的合金因子,利用最小二乘法拟合建立了非晶形成临界直径与上述4个合金因子的数学表达式.根据该数学表达式,提出了指导大尺寸块状非晶合金筛选的原则是具有高的混合熵、高的平均热导率和适中的混合焓,非晶合金特征转变温度与合金组元的平均熔点强相关,非晶合金剪切模量和体积模量与合金的平均原子体积呈负相关等. ...
A predictive structural model for bulk metallic glasses
1
2015
... 非晶形成能力尚没有明确的定义和科学的实验表征方法,冷却速率是最直接可量化非晶形成能力的实验手段,但实验测量困难.因此,利用能够形成非晶的数据样本,建立机器学习分类模型,深入分析模型的材料特征,辅助理解非晶形成能力的物理机制,指导非晶设计,是非晶领域机器学习的研究热点[33 ~40 ] .Xiong等[35 ] 基于6471个数据样本(1211个块体非晶合金,1552个带状非晶合金和3708个晶态合金),利用合金元素电子、原子和热力学参数构建合金因子,通过相关系数筛选、方差分析、顺序选择法等三步特征筛选,筛选出平均价电子数、s轨道电子数、熔化焓差、沸点、元素族数和功函数差等6个特征,建立的随机森林分类模型准确率为88.13%,根据预测结果,从13种带状非晶合金中成功发现了5种新的块体非晶合金,并进行了实验验证.Xiong等[34 ] 还利用非晶形成临界直径在1~40 mm的695个块体非晶合金数据样本,将数据分成376个临界直径在1~5 mm的低非晶形成能力(L-GFA)和319个临界直径大于5 mm的高非晶形成能力(G-GFA) 2个数据样本集,分别建立极端梯度提升树(XGboost)分类模型对2个数据样本集进行分类,同时,对G-GFA数据样本集进行回归,以便更准确地预测具有高非晶形成能力的合金临界直径.Sun等[38 ] 基于339个利用甩带方式形成非晶合金和1131组二元非晶合金数据样本,选取原子质量、混合焓、原子半径、单质材料的液化温度、虚拟液化温度、液化温差、元素含量等构建合金因子,建立支持向量机分类模型,对二元合金的非晶形成能力进行预测和分析,发现液相线温度是二元合金非晶形成能力的关键参量.采用机器学习辅助方法还提出了许多预测合金非晶形成能力的准则和参数,如混合熵、混合焓、过冷液体温度区间、约化玻璃转化温度、黏度、临界冷却速率等,通过建立回归模型预测非晶的形成能力[34 ~37 , 39 ~41 ] .Xiong等[35 ] 基于6000个涵盖非晶类型、非晶形成临界直径、非晶特征转变温度(如玻璃化转变温度、约化玻璃转变温度、液相线温度)和弹性性能等数据样本,利用符号回归建立了以原子体积和Pauling电负性为变量的体积模量正相关的合金因子,以原子体积和混合熵为变量的剪切模量正相关的合金因子,以及分别以混合焓、混合熵、热导率等为变量和以玻璃转变温度、晶化温度、液相线温度等为变量的非晶形成临界直径的合金因子,利用最小二乘法拟合建立了非晶形成临界直径与上述4个合金因子的数学表达式.根据该数学表达式,提出了指导大尺寸块状非晶合金筛选的原则是具有高的混合熵、高的平均热导率和适中的混合焓,非晶合金特征转变温度与合金组元的平均熔点强相关,非晶合金剪切模量和体积模量与合金的平均原子体积呈负相关等. ...
Artificial neural network modeling for undercooled liquid region of glass forming alloys
1
2010
... 非晶形成能力尚没有明确的定义和科学的实验表征方法,冷却速率是最直接可量化非晶形成能力的实验手段,但实验测量困难.因此,利用能够形成非晶的数据样本,建立机器学习分类模型,深入分析模型的材料特征,辅助理解非晶形成能力的物理机制,指导非晶设计,是非晶领域机器学习的研究热点[33 ~40 ] .Xiong等[35 ] 基于6471个数据样本(1211个块体非晶合金,1552个带状非晶合金和3708个晶态合金),利用合金元素电子、原子和热力学参数构建合金因子,通过相关系数筛选、方差分析、顺序选择法等三步特征筛选,筛选出平均价电子数、s轨道电子数、熔化焓差、沸点、元素族数和功函数差等6个特征,建立的随机森林分类模型准确率为88.13%,根据预测结果,从13种带状非晶合金中成功发现了5种新的块体非晶合金,并进行了实验验证.Xiong等[34 ] 还利用非晶形成临界直径在1~40 mm的695个块体非晶合金数据样本,将数据分成376个临界直径在1~5 mm的低非晶形成能力(L-GFA)和319个临界直径大于5 mm的高非晶形成能力(G-GFA) 2个数据样本集,分别建立极端梯度提升树(XGboost)分类模型对2个数据样本集进行分类,同时,对G-GFA数据样本集进行回归,以便更准确地预测具有高非晶形成能力的合金临界直径.Sun等[38 ] 基于339个利用甩带方式形成非晶合金和1131组二元非晶合金数据样本,选取原子质量、混合焓、原子半径、单质材料的液化温度、虚拟液化温度、液化温差、元素含量等构建合金因子,建立支持向量机分类模型,对二元合金的非晶形成能力进行预测和分析,发现液相线温度是二元合金非晶形成能力的关键参量.采用机器学习辅助方法还提出了许多预测合金非晶形成能力的准则和参数,如混合熵、混合焓、过冷液体温度区间、约化玻璃转化温度、黏度、临界冷却速率等,通过建立回归模型预测非晶的形成能力[34 ~37 , 39 ~41 ] .Xiong等[35 ] 基于6000个涵盖非晶类型、非晶形成临界直径、非晶特征转变温度(如玻璃化转变温度、约化玻璃转变温度、液相线温度)和弹性性能等数据样本,利用符号回归建立了以原子体积和Pauling电负性为变量的体积模量正相关的合金因子,以原子体积和混合熵为变量的剪切模量正相关的合金因子,以及分别以混合焓、混合熵、热导率等为变量和以玻璃转变温度、晶化温度、液相线温度等为变量的非晶形成临界直径的合金因子,利用最小二乘法拟合建立了非晶形成临界直径与上述4个合金因子的数学表达式.根据该数学表达式,提出了指导大尺寸块状非晶合金筛选的原则是具有高的混合熵、高的平均热导率和适中的混合焓,非晶合金特征转变温度与合金组元的平均熔点强相关,非晶合金剪切模量和体积模量与合金的平均原子体积呈负相关等. ...
Accelerated discovery of metallic glasses through iteration of machine learning and high-throughput experiments
1
2018
... 非晶形成能力尚没有明确的定义和科学的实验表征方法,冷却速率是最直接可量化非晶形成能力的实验手段,但实验测量困难.因此,利用能够形成非晶的数据样本,建立机器学习分类模型,深入分析模型的材料特征,辅助理解非晶形成能力的物理机制,指导非晶设计,是非晶领域机器学习的研究热点[33 ~40 ] .Xiong等[35 ] 基于6471个数据样本(1211个块体非晶合金,1552个带状非晶合金和3708个晶态合金),利用合金元素电子、原子和热力学参数构建合金因子,通过相关系数筛选、方差分析、顺序选择法等三步特征筛选,筛选出平均价电子数、s轨道电子数、熔化焓差、沸点、元素族数和功函数差等6个特征,建立的随机森林分类模型准确率为88.13%,根据预测结果,从13种带状非晶合金中成功发现了5种新的块体非晶合金,并进行了实验验证.Xiong等[34 ] 还利用非晶形成临界直径在1~40 mm的695个块体非晶合金数据样本,将数据分成376个临界直径在1~5 mm的低非晶形成能力(L-GFA)和319个临界直径大于5 mm的高非晶形成能力(G-GFA) 2个数据样本集,分别建立极端梯度提升树(XGboost)分类模型对2个数据样本集进行分类,同时,对G-GFA数据样本集进行回归,以便更准确地预测具有高非晶形成能力的合金临界直径.Sun等[38 ] 基于339个利用甩带方式形成非晶合金和1131组二元非晶合金数据样本,选取原子质量、混合焓、原子半径、单质材料的液化温度、虚拟液化温度、液化温差、元素含量等构建合金因子,建立支持向量机分类模型,对二元合金的非晶形成能力进行预测和分析,发现液相线温度是二元合金非晶形成能力的关键参量.采用机器学习辅助方法还提出了许多预测合金非晶形成能力的准则和参数,如混合熵、混合焓、过冷液体温度区间、约化玻璃转化温度、黏度、临界冷却速率等,通过建立回归模型预测非晶的形成能力[34 ~37 , 39 ~41 ] .Xiong等[35 ] 基于6000个涵盖非晶类型、非晶形成临界直径、非晶特征转变温度(如玻璃化转变温度、约化玻璃转变温度、液相线温度)和弹性性能等数据样本,利用符号回归建立了以原子体积和Pauling电负性为变量的体积模量正相关的合金因子,以原子体积和混合熵为变量的剪切模量正相关的合金因子,以及分别以混合焓、混合熵、热导率等为变量和以玻璃转变温度、晶化温度、液相线温度等为变量的非晶形成临界直径的合金因子,利用最小二乘法拟合建立了非晶形成临界直径与上述4个合金因子的数学表达式.根据该数学表达式,提出了指导大尺寸块状非晶合金筛选的原则是具有高的混合熵、高的平均热导率和适中的混合焓,非晶合金特征转变温度与合金组元的平均熔点强相关,非晶合金剪切模量和体积模量与合金的平均原子体积呈负相关等. ...
Neural network model for correlating microstructural features and hardness properties of nickel-based superalloys
1
2020
... 镍基高温合金γ′ 相的组织特征对合金力学性能、组织稳定性、高温蠕变和抗疲劳性能等具有重要影响.Li等[42 ] 基于483张镍基高温合金扫描电子显微镜图像,利用模式识别技术从图像中定义并提取了γ' 相体积分数、面积和数量等23个显微组织特征,使用浅层神经网络(SNN)从23个特征中筛选出10个组织特征,同时增加γ′ 相面积分布和冷却速率2个经验参数为特征,建立了高温合金硬度的深层神经网络(DNN)预测模型,预测误差(< 0.6%)远低于物理模型误差(> 4.5%).Fu等[43 ] 从138张DZ125镍基高温合金高通量蠕变实验的显微组织图像提取了γ' 相体积分数、γ' 相筏排化程度、筏化γ' 相厚度等显微组织特征,连同服役时间,建立了显微组织特征和服役时间与服役温度和服役应力间的反向传播人工神经网络(BPANN)预测模型,模型平均绝对预测误差分别达到1.2℃和16 MPa,并利用服役900 h涡轮机叶片验证了模型的准确性.Jiang等[44 ] 利用136个数据样本,基于多层感知器算法,以镍基单晶高温合金成分、样品厚度和测量温度等为特征,建立了γ-γ′ 相界面晶格错配度预测模型,预测精度优于WATANABE模型.Jung等[45 ] 利用83个数据样本,提取了多边形铁素体、针状铁素体、粒状贝氏体、贝氏体中铁素体和马氏体等体积分数为显微组织特征,建立了贝氏体钢屈服强度和抗拉强度的反向传播线性回归(BPLR)和人工神经网络预测模型,工作流程如图2 [45 ] 所示,验证集和测试集的平均绝对百分比误差(MAPE)分别为6.59%和10.78%.Gebhardt等[46 ] 利用70个有限元模拟数据样本,提取了球墨铸铁中石墨夹杂物形状和尺寸等组织特征,以安定极限(shakedown)为目标量,建立了简化的残差神经网络(SimResNet)预测模型,模型的绝对平均误差和偏差相对于有限元模拟均小于3.5,但模拟计算时间由8 h缩短到40 s. ...
Evaluation of service conditions of high pressure turbine blades made of DS Ni-base superalloy by artificial neural networks
1
2020
... 镍基高温合金γ′ 相的组织特征对合金力学性能、组织稳定性、高温蠕变和抗疲劳性能等具有重要影响.Li等[42 ] 基于483张镍基高温合金扫描电子显微镜图像,利用模式识别技术从图像中定义并提取了γ' 相体积分数、面积和数量等23个显微组织特征,使用浅层神经网络(SNN)从23个特征中筛选出10个组织特征,同时增加γ′ 相面积分布和冷却速率2个经验参数为特征,建立了高温合金硬度的深层神经网络(DNN)预测模型,预测误差(< 0.6%)远低于物理模型误差(> 4.5%).Fu等[43 ] 从138张DZ125镍基高温合金高通量蠕变实验的显微组织图像提取了γ' 相体积分数、γ' 相筏排化程度、筏化γ' 相厚度等显微组织特征,连同服役时间,建立了显微组织特征和服役时间与服役温度和服役应力间的反向传播人工神经网络(BPANN)预测模型,模型平均绝对预测误差分别达到1.2℃和16 MPa,并利用服役900 h涡轮机叶片验证了模型的准确性.Jiang等[44 ] 利用136个数据样本,基于多层感知器算法,以镍基单晶高温合金成分、样品厚度和测量温度等为特征,建立了γ-γ′ 相界面晶格错配度预测模型,预测精度优于WATANABE模型.Jung等[45 ] 利用83个数据样本,提取了多边形铁素体、针状铁素体、粒状贝氏体、贝氏体中铁素体和马氏体等体积分数为显微组织特征,建立了贝氏体钢屈服强度和抗拉强度的反向传播线性回归(BPLR)和人工神经网络预测模型,工作流程如图2 [45 ] 所示,验证集和测试集的平均绝对百分比误差(MAPE)分别为6.59%和10.78%.Gebhardt等[46 ] 利用70个有限元模拟数据样本,提取了球墨铸铁中石墨夹杂物形状和尺寸等组织特征,以安定极限(shakedown)为目标量,建立了简化的残差神经网络(SimResNet)预测模型,模型的绝对平均误差和偏差相对于有限元模拟均小于3.5,但模拟计算时间由8 h缩短到40 s. ...
An materials informatics approach to Ni-based single crystal superalloys lattice misfit prediction
1
2018
... 镍基高温合金γ′ 相的组织特征对合金力学性能、组织稳定性、高温蠕变和抗疲劳性能等具有重要影响.Li等[42 ] 基于483张镍基高温合金扫描电子显微镜图像,利用模式识别技术从图像中定义并提取了γ' 相体积分数、面积和数量等23个显微组织特征,使用浅层神经网络(SNN)从23个特征中筛选出10个组织特征,同时增加γ′ 相面积分布和冷却速率2个经验参数为特征,建立了高温合金硬度的深层神经网络(DNN)预测模型,预测误差(< 0.6%)远低于物理模型误差(> 4.5%).Fu等[43 ] 从138张DZ125镍基高温合金高通量蠕变实验的显微组织图像提取了γ' 相体积分数、γ' 相筏排化程度、筏化γ' 相厚度等显微组织特征,连同服役时间,建立了显微组织特征和服役时间与服役温度和服役应力间的反向传播人工神经网络(BPANN)预测模型,模型平均绝对预测误差分别达到1.2℃和16 MPa,并利用服役900 h涡轮机叶片验证了模型的准确性.Jiang等[44 ] 利用136个数据样本,基于多层感知器算法,以镍基单晶高温合金成分、样品厚度和测量温度等为特征,建立了γ-γ′ 相界面晶格错配度预测模型,预测精度优于WATANABE模型.Jung等[45 ] 利用83个数据样本,提取了多边形铁素体、针状铁素体、粒状贝氏体、贝氏体中铁素体和马氏体等体积分数为显微组织特征,建立了贝氏体钢屈服强度和抗拉强度的反向传播线性回归(BPLR)和人工神经网络预测模型,工作流程如图2 [45 ] 所示,验证集和测试集的平均绝对百分比误差(MAPE)分别为6.59%和10.78%.Gebhardt等[46 ] 利用70个有限元模拟数据样本,提取了球墨铸铁中石墨夹杂物形状和尺寸等组织特征,以安定极限(shakedown)为目标量,建立了简化的残差神经网络(SimResNet)预测模型,模型的绝对平均误差和偏差相对于有限元模拟均小于3.5,但模拟计算时间由8 h缩短到40 s. ...
Artificial intelligence for the prediction of tensile properties by using microstructural parameters in high strength steels
4
2020
... 镍基高温合金γ′ 相的组织特征对合金力学性能、组织稳定性、高温蠕变和抗疲劳性能等具有重要影响.Li等[42 ] 基于483张镍基高温合金扫描电子显微镜图像,利用模式识别技术从图像中定义并提取了γ' 相体积分数、面积和数量等23个显微组织特征,使用浅层神经网络(SNN)从23个特征中筛选出10个组织特征,同时增加γ′ 相面积分布和冷却速率2个经验参数为特征,建立了高温合金硬度的深层神经网络(DNN)预测模型,预测误差(< 0.6%)远低于物理模型误差(> 4.5%).Fu等[43 ] 从138张DZ125镍基高温合金高通量蠕变实验的显微组织图像提取了γ' 相体积分数、γ' 相筏排化程度、筏化γ' 相厚度等显微组织特征,连同服役时间,建立了显微组织特征和服役时间与服役温度和服役应力间的反向传播人工神经网络(BPANN)预测模型,模型平均绝对预测误差分别达到1.2℃和16 MPa,并利用服役900 h涡轮机叶片验证了模型的准确性.Jiang等[44 ] 利用136个数据样本,基于多层感知器算法,以镍基单晶高温合金成分、样品厚度和测量温度等为特征,建立了γ-γ′ 相界面晶格错配度预测模型,预测精度优于WATANABE模型.Jung等[45 ] 利用83个数据样本,提取了多边形铁素体、针状铁素体、粒状贝氏体、贝氏体中铁素体和马氏体等体积分数为显微组织特征,建立了贝氏体钢屈服强度和抗拉强度的反向传播线性回归(BPLR)和人工神经网络预测模型,工作流程如图2 [45 ] 所示,验证集和测试集的平均绝对百分比误差(MAPE)分别为6.59%和10.78%.Gebhardt等[46 ] 利用70个有限元模拟数据样本,提取了球墨铸铁中石墨夹杂物形状和尺寸等组织特征,以安定极限(shakedown)为目标量,建立了简化的残差神经网络(SimResNet)预测模型,模型的绝对平均误差和偏差相对于有限元模拟均小于3.5,但模拟计算时间由8 h缩短到40 s. ...
... [45 ]所示,验证集和测试集的平均绝对百分比误差(MAPE)分别为6.59%和10.78%.Gebhardt等[46 ] 利用70个有限元模拟数据样本,提取了球墨铸铁中石墨夹杂物形状和尺寸等组织特征,以安定极限(shakedown)为目标量,建立了简化的残差神经网络(SimResNet)预测模型,模型的绝对平均误差和偏差相对于有限元模拟均小于3.5,但模拟计算时间由8 h缩短到40 s. ...
... [
45 ]
Flow map for the design of microstructure and mechanical property of steels with artificial neural network (ANN) (PF—polygonal ferrite; AF—acicular ferrite; GB—granular bainite; BF—bainitic ferrite; M—martensite; BH, DP, CP, and TRIP represent bake-hardening steel, dual phase steel, complex phase steel, and transformation induced plasticity steel; HSLA—high strength low alloys; L.R.Y.S represents linear regression of yield strength)<sup>[<xref ref-type="bibr" rid="R45">45</xref>]</sup> Fig.2 ![]()
Herriott等[47 ] 从7700个基于物理模型模拟的增材制造316L不锈钢显微组织数据,以人工提取的晶粒平均体积、纵横比、表面积与体积比等35个组织特征训练岭回归(ridge regression)和XGBoost模型,以3D显微图像和晶粒编号、3D显微图像和晶粒晶体学取向为输入分别训练了卷积神经网络(CNN)模型,发现增加晶粒晶体学取向信息的3D显微图像训练,其CNN模型精度最高,R 2 和均方根误差(RMSE)分别为0.95和9.23 MPa,表明几乎不需要预处理(组织特征提取)就可在几秒内预测出材料屈服强度等力学性能.Kondo等[48 ] 利用CNN建立了多孔ZrO2 -Y2 O3 固体电解质显微组织与离子导电率的关系模型,直接利用7张显微组织图像为输入训练的CNN模型的R 2 为0.64,明显优于以人工提取的显微组织特征(空洞数量和平均面积)为输入建立的核岭回归(kernel ridge regression)模型(R 2 为0.55),并提出了深度学习模型特征可视化的方法.可视化结果表明,CNN模型能够捕获到与科学家先验知识一致的决定材料宏观性质的主要显微组织特征. ...
... [
45 ]
Fig.2 ![]()
Herriott等[47 ] 从7700个基于物理模型模拟的增材制造316L不锈钢显微组织数据,以人工提取的晶粒平均体积、纵横比、表面积与体积比等35个组织特征训练岭回归(ridge regression)和XGBoost模型,以3D显微图像和晶粒编号、3D显微图像和晶粒晶体学取向为输入分别训练了卷积神经网络(CNN)模型,发现增加晶粒晶体学取向信息的3D显微图像训练,其CNN模型精度最高,R 2 和均方根误差(RMSE)分别为0.95和9.23 MPa,表明几乎不需要预处理(组织特征提取)就可在几秒内预测出材料屈服强度等力学性能.Kondo等[48 ] 利用CNN建立了多孔ZrO2 -Y2 O3 固体电解质显微组织与离子导电率的关系模型,直接利用7张显微组织图像为输入训练的CNN模型的R 2 为0.64,明显优于以人工提取的显微组织特征(空洞数量和平均面积)为输入建立的核岭回归(kernel ridge regression)模型(R 2 为0.55),并提出了深度学习模型特征可视化的方法.可视化结果表明,CNN模型能够捕获到与科学家先验知识一致的决定材料宏观性质的主要显微组织特征. ...
Simplified ResNet approach for data driven prediction of microstructure-fatigue relationship
1
2020
... 镍基高温合金γ′ 相的组织特征对合金力学性能、组织稳定性、高温蠕变和抗疲劳性能等具有重要影响.Li等[42 ] 基于483张镍基高温合金扫描电子显微镜图像,利用模式识别技术从图像中定义并提取了γ' 相体积分数、面积和数量等23个显微组织特征,使用浅层神经网络(SNN)从23个特征中筛选出10个组织特征,同时增加γ′ 相面积分布和冷却速率2个经验参数为特征,建立了高温合金硬度的深层神经网络(DNN)预测模型,预测误差(< 0.6%)远低于物理模型误差(> 4.5%).Fu等[43 ] 从138张DZ125镍基高温合金高通量蠕变实验的显微组织图像提取了γ' 相体积分数、γ' 相筏排化程度、筏化γ' 相厚度等显微组织特征,连同服役时间,建立了显微组织特征和服役时间与服役温度和服役应力间的反向传播人工神经网络(BPANN)预测模型,模型平均绝对预测误差分别达到1.2℃和16 MPa,并利用服役900 h涡轮机叶片验证了模型的准确性.Jiang等[44 ] 利用136个数据样本,基于多层感知器算法,以镍基单晶高温合金成分、样品厚度和测量温度等为特征,建立了γ-γ′ 相界面晶格错配度预测模型,预测精度优于WATANABE模型.Jung等[45 ] 利用83个数据样本,提取了多边形铁素体、针状铁素体、粒状贝氏体、贝氏体中铁素体和马氏体等体积分数为显微组织特征,建立了贝氏体钢屈服强度和抗拉强度的反向传播线性回归(BPLR)和人工神经网络预测模型,工作流程如图2 [45 ] 所示,验证集和测试集的平均绝对百分比误差(MAPE)分别为6.59%和10.78%.Gebhardt等[46 ] 利用70个有限元模拟数据样本,提取了球墨铸铁中石墨夹杂物形状和尺寸等组织特征,以安定极限(shakedown)为目标量,建立了简化的残差神经网络(SimResNet)预测模型,模型的绝对平均误差和偏差相对于有限元模拟均小于3.5,但模拟计算时间由8 h缩短到40 s. ...
Predicting microstructure-dependent mechanical properties in additively manufactured metals with machine- and deep-learning methods
1
2020
... Herriott等[47 ] 从7700个基于物理模型模拟的增材制造316L不锈钢显微组织数据,以人工提取的晶粒平均体积、纵横比、表面积与体积比等35个组织特征训练岭回归(ridge regression)和XGBoost模型,以3D显微图像和晶粒编号、3D显微图像和晶粒晶体学取向为输入分别训练了卷积神经网络(CNN)模型,发现增加晶粒晶体学取向信息的3D显微图像训练,其CNN模型精度最高,R 2 和均方根误差(RMSE)分别为0.95和9.23 MPa,表明几乎不需要预处理(组织特征提取)就可在几秒内预测出材料屈服强度等力学性能.Kondo等[48 ] 利用CNN建立了多孔ZrO2 -Y2 O3 固体电解质显微组织与离子导电率的关系模型,直接利用7张显微组织图像为输入训练的CNN模型的R 2 为0.64,明显优于以人工提取的显微组织特征(空洞数量和平均面积)为输入建立的核岭回归(kernel ridge regression)模型(R 2 为0.55),并提出了深度学习模型特征可视化的方法.可视化结果表明,CNN模型能够捕获到与科学家先验知识一致的决定材料宏观性质的主要显微组织特征. ...
Microstructure recognition using convolutional neural networks for prediction of ionic conductivity in ceramics
1
2017
... Herriott等[47 ] 从7700个基于物理模型模拟的增材制造316L不锈钢显微组织数据,以人工提取的晶粒平均体积、纵横比、表面积与体积比等35个组织特征训练岭回归(ridge regression)和XGBoost模型,以3D显微图像和晶粒编号、3D显微图像和晶粒晶体学取向为输入分别训练了卷积神经网络(CNN)模型,发现增加晶粒晶体学取向信息的3D显微图像训练,其CNN模型精度最高,R 2 和均方根误差(RMSE)分别为0.95和9.23 MPa,表明几乎不需要预处理(组织特征提取)就可在几秒内预测出材料屈服强度等力学性能.Kondo等[48 ] 利用CNN建立了多孔ZrO2 -Y2 O3 固体电解质显微组织与离子导电率的关系模型,直接利用7张显微组织图像为输入训练的CNN模型的R 2 为0.64,明显优于以人工提取的显微组织特征(空洞数量和平均面积)为输入建立的核岭回归(kernel ridge regression)模型(R 2 为0.55),并提出了深度学习模型特征可视化的方法.可视化结果表明,CNN模型能够捕获到与科学家先验知识一致的决定材料宏观性质的主要显微组织特征. ...
Tensile property prediction by feature engineering guided machine learning in reduced activation ferritic/martensitic steels
1
2020
... 钢铁材料的屈服强度、抗拉强度和延伸率等力学性能与成分和热处理工艺密切相关,以力学性能为目标量,以成分和工艺参数等材料参数为输入建立预测模型,辅助材料设计和工艺优化,在钢铁材料领域得到较多应用.Wang等[49 ] 利用60个铁素体/马氏体钢数据样本,从回火温度、回火时间、C含量、Cr含量等19个材料参数中筛选出7个参数作为输入,建立随机森林模型,分别对屈服强度和延伸率进行预测,得到同时提升铁素体/马氏体钢屈服强度和延伸率的成分和热处理工艺,分别是Cr含量8%~9% (质量分数)和回火温度750~760℃,回火时间30~120 min.Guo等[50 ] 基于65288个钢的工业数据样本,经过数据清洗得到63127个有效样本,以S和Cu等元素含量、炉温、退火温度等材料参数为输入,建立随机森林模型,对屈服强度、抗拉强度和延伸率进行预测,为了设计出同时满足3种性能指标(如屈服强度为600 MPa,屈强比为0.8)的成分和工艺参数,将预测模型作为目标函数,以多性能间的关系为约束,通过内点法(interior point method)对非线性凸优化问题求解,计算出钢的屈服强度、抗拉强度和延伸率的可能边界,以及潜在的最佳成分和工艺参数,设计出了综合性能满足要求的新钢种.人工神经网络等机器学习模型在热轧AISI 10xx系列碳钢棒材[51 ] 、马氏体时效钢[52 ] 、DP800双相钢[53 ] 等力学性能预测方面均取得了良好的效果. ...
A predicting model for properties of steel using the industrial big data based on machine learning
1
2019
... 钢铁材料的屈服强度、抗拉强度和延伸率等力学性能与成分和热处理工艺密切相关,以力学性能为目标量,以成分和工艺参数等材料参数为输入建立预测模型,辅助材料设计和工艺优化,在钢铁材料领域得到较多应用.Wang等[49 ] 利用60个铁素体/马氏体钢数据样本,从回火温度、回火时间、C含量、Cr含量等19个材料参数中筛选出7个参数作为输入,建立随机森林模型,分别对屈服强度和延伸率进行预测,得到同时提升铁素体/马氏体钢屈服强度和延伸率的成分和热处理工艺,分别是Cr含量8%~9% (质量分数)和回火温度750~760℃,回火时间30~120 min.Guo等[50 ] 基于65288个钢的工业数据样本,经过数据清洗得到63127个有效样本,以S和Cu等元素含量、炉温、退火温度等材料参数为输入,建立随机森林模型,对屈服强度、抗拉强度和延伸率进行预测,为了设计出同时满足3种性能指标(如屈服强度为600 MPa,屈强比为0.8)的成分和工艺参数,将预测模型作为目标函数,以多性能间的关系为约束,通过内点法(interior point method)对非线性凸优化问题求解,计算出钢的屈服强度、抗拉强度和延伸率的可能边界,以及潜在的最佳成分和工艺参数,设计出了综合性能满足要求的新钢种.人工神经网络等机器学习模型在热轧AISI 10xx系列碳钢棒材[51 ] 、马氏体时效钢[52 ] 、DP800双相钢[53 ] 等力学性能预测方面均取得了良好的效果. ...
Artificial neural network approach to predict mechanical properties of hot rolled, nonresulfurized, AISI 10xx series carbon steel bars
1
2008
... 钢铁材料的屈服强度、抗拉强度和延伸率等力学性能与成分和热处理工艺密切相关,以力学性能为目标量,以成分和工艺参数等材料参数为输入建立预测模型,辅助材料设计和工艺优化,在钢铁材料领域得到较多应用.Wang等[49 ] 利用60个铁素体/马氏体钢数据样本,从回火温度、回火时间、C含量、Cr含量等19个材料参数中筛选出7个参数作为输入,建立随机森林模型,分别对屈服强度和延伸率进行预测,得到同时提升铁素体/马氏体钢屈服强度和延伸率的成分和热处理工艺,分别是Cr含量8%~9% (质量分数)和回火温度750~760℃,回火时间30~120 min.Guo等[50 ] 基于65288个钢的工业数据样本,经过数据清洗得到63127个有效样本,以S和Cu等元素含量、炉温、退火温度等材料参数为输入,建立随机森林模型,对屈服强度、抗拉强度和延伸率进行预测,为了设计出同时满足3种性能指标(如屈服强度为600 MPa,屈强比为0.8)的成分和工艺参数,将预测模型作为目标函数,以多性能间的关系为约束,通过内点法(interior point method)对非线性凸优化问题求解,计算出钢的屈服强度、抗拉强度和延伸率的可能边界,以及潜在的最佳成分和工艺参数,设计出了综合性能满足要求的新钢种.人工神经网络等机器学习模型在热轧AISI 10xx系列碳钢棒材[51 ] 、马氏体时效钢[52 ] 、DP800双相钢[53 ] 等力学性能预测方面均取得了良好的效果. ...
Modelling the correlation between processing parameters and properties of maraging steels using artificial neural network
1
2004
... 钢铁材料的屈服强度、抗拉强度和延伸率等力学性能与成分和热处理工艺密切相关,以力学性能为目标量,以成分和工艺参数等材料参数为输入建立预测模型,辅助材料设计和工艺优化,在钢铁材料领域得到较多应用.Wang等[49 ] 利用60个铁素体/马氏体钢数据样本,从回火温度、回火时间、C含量、Cr含量等19个材料参数中筛选出7个参数作为输入,建立随机森林模型,分别对屈服强度和延伸率进行预测,得到同时提升铁素体/马氏体钢屈服强度和延伸率的成分和热处理工艺,分别是Cr含量8%~9% (质量分数)和回火温度750~760℃,回火时间30~120 min.Guo等[50 ] 基于65288个钢的工业数据样本,经过数据清洗得到63127个有效样本,以S和Cu等元素含量、炉温、退火温度等材料参数为输入,建立随机森林模型,对屈服强度、抗拉强度和延伸率进行预测,为了设计出同时满足3种性能指标(如屈服强度为600 MPa,屈强比为0.8)的成分和工艺参数,将预测模型作为目标函数,以多性能间的关系为约束,通过内点法(interior point method)对非线性凸优化问题求解,计算出钢的屈服强度、抗拉强度和延伸率的可能边界,以及潜在的最佳成分和工艺参数,设计出了综合性能满足要求的新钢种.人工神经网络等机器学习模型在热轧AISI 10xx系列碳钢棒材[51 ] 、马氏体时效钢[52 ] 、DP800双相钢[53 ] 等力学性能预测方面均取得了良好的效果. ...
Machine-learning based temperature- and rate-dependent plasticity model: Application to analysis of fracture experiments on DP steel
1
2019
... 钢铁材料的屈服强度、抗拉强度和延伸率等力学性能与成分和热处理工艺密切相关,以力学性能为目标量,以成分和工艺参数等材料参数为输入建立预测模型,辅助材料设计和工艺优化,在钢铁材料领域得到较多应用.Wang等[49 ] 利用60个铁素体/马氏体钢数据样本,从回火温度、回火时间、C含量、Cr含量等19个材料参数中筛选出7个参数作为输入,建立随机森林模型,分别对屈服强度和延伸率进行预测,得到同时提升铁素体/马氏体钢屈服强度和延伸率的成分和热处理工艺,分别是Cr含量8%~9% (质量分数)和回火温度750~760℃,回火时间30~120 min.Guo等[50 ] 基于65288个钢的工业数据样本,经过数据清洗得到63127个有效样本,以S和Cu等元素含量、炉温、退火温度等材料参数为输入,建立随机森林模型,对屈服强度、抗拉强度和延伸率进行预测,为了设计出同时满足3种性能指标(如屈服强度为600 MPa,屈强比为0.8)的成分和工艺参数,将预测模型作为目标函数,以多性能间的关系为约束,通过内点法(interior point method)对非线性凸优化问题求解,计算出钢的屈服强度、抗拉强度和延伸率的可能边界,以及潜在的最佳成分和工艺参数,设计出了综合性能满足要求的新钢种.人工神经网络等机器学习模型在热轧AISI 10xx系列碳钢棒材[51 ] 、马氏体时效钢[52 ] 、DP800双相钢[53 ] 等力学性能预测方面均取得了良好的效果. ...
Predicting tensile properties of AZ31 magnesium alloys by machine learning
1
2020
... Xu等[54 ] 为了建立AZ31镁合金中Zn、Al、Mn、Ca、Si含量,以及均匀化温度、均匀化时间、挤压温度、挤压比、挤压速率、轧制温度、轧制比、轧制速率等加工参数与屈服强度、抗拉强度和延伸率等性能之间的构效关系,基于112个数据样本,以材料参数为输入建立了人工神经网络和支持向量机模型,2个模型对屈服强度、抗拉强度和延伸率的预测均有较高的精度,人工神经网络模型对屈服强度、抗拉伸强度和延伸率的R 2 分别为0.83、0.83和0.86,支持向量机模型的R 2 分别为0.79、0.93和0.79.刘彬等[55 ] 利用AZ31镁合金力学性能的38个实验数据样本,以取样方向、退火温度、退火时间等材料参数为输入,建立了抗拉强度、屈服强度和延伸率等的人工神经网络预测模型,利用全排列组合训练方式对模型参数优化,发现相比于试探法确定的模型参数,预测模型具有更高的平均决定系数和更低的平均误差,更准确地预测了AZ31镁合金不同退火条件下的力学性能.Li等[56 ] 以镁合金元素质量分数、铸造和变形工艺、热处理工艺、合金性能的实验温度等为输入,以抗拉强度、屈服强度、延伸率和腐蚀速率为目标量(输出),建立了LASSO (least absolute shrinkage and selection operator)回归、随机森林回归和支持向量回归模型,通过比较3个模型的平均绝对误差、均方误差和决定系数,发现随机森林模型的预测效果最好.Chaudry等[57 ] 利用1592个Al-Cu-Mg-x (x = Zn、Zr等)合金的硬度数据样本,以成分和时效温度、时效时间等材料参数为输入,建立了铝合金在各种时效处理条件下的硬度预测模型,梯度提升树模型的决定系数和均方误差分别达到0.94和7.27,准确地预测了Al-4Cu-0.5Mg-0.15Si-0.1Sc合金在175和225℃时效的性能.Cao等[58 ] 以单级时效、双级时效、回归再时效时间和温度等材料参数为输入,建立了多元线性回归、支持向量回归和广义回归神经网络等机器学习模型,预测不同时效处理的7N01铝合金硬度和耐腐蚀性能,预测结果表明单级时效和回归再时效均能使7N01铝合金达到比双级时效更高的强度,但双级时效铝合金的耐腐蚀性优于单级时效. ...
基于参数优化的人工神经网络的AZ31镁合金力学性能预测模型
1
2011
... Xu等[54 ] 为了建立AZ31镁合金中Zn、Al、Mn、Ca、Si含量,以及均匀化温度、均匀化时间、挤压温度、挤压比、挤压速率、轧制温度、轧制比、轧制速率等加工参数与屈服强度、抗拉强度和延伸率等性能之间的构效关系,基于112个数据样本,以材料参数为输入建立了人工神经网络和支持向量机模型,2个模型对屈服强度、抗拉强度和延伸率的预测均有较高的精度,人工神经网络模型对屈服强度、抗拉伸强度和延伸率的R 2 分别为0.83、0.83和0.86,支持向量机模型的R 2 分别为0.79、0.93和0.79.刘彬等[55 ] 利用AZ31镁合金力学性能的38个实验数据样本,以取样方向、退火温度、退火时间等材料参数为输入,建立了抗拉强度、屈服强度和延伸率等的人工神经网络预测模型,利用全排列组合训练方式对模型参数优化,发现相比于试探法确定的模型参数,预测模型具有更高的平均决定系数和更低的平均误差,更准确地预测了AZ31镁合金不同退火条件下的力学性能.Li等[56 ] 以镁合金元素质量分数、铸造和变形工艺、热处理工艺、合金性能的实验温度等为输入,以抗拉强度、屈服强度、延伸率和腐蚀速率为目标量(输出),建立了LASSO (least absolute shrinkage and selection operator)回归、随机森林回归和支持向量回归模型,通过比较3个模型的平均绝对误差、均方误差和决定系数,发现随机森林模型的预测效果最好.Chaudry等[57 ] 利用1592个Al-Cu-Mg-x (x = Zn、Zr等)合金的硬度数据样本,以成分和时效温度、时效时间等材料参数为输入,建立了铝合金在各种时效处理条件下的硬度预测模型,梯度提升树模型的决定系数和均方误差分别达到0.94和7.27,准确地预测了Al-4Cu-0.5Mg-0.15Si-0.1Sc合金在175和225℃时效的性能.Cao等[58 ] 以单级时效、双级时效、回归再时效时间和温度等材料参数为输入,建立了多元线性回归、支持向量回归和广义回归神经网络等机器学习模型,预测不同时效处理的7N01铝合金硬度和耐腐蚀性能,预测结果表明单级时效和回归再时效均能使7N01铝合金达到比双级时效更高的强度,但双级时效铝合金的耐腐蚀性优于单级时效. ...
基于参数优化的人工神经网络的AZ31镁合金力学性能预测模型
1
2011
... Xu等[54 ] 为了建立AZ31镁合金中Zn、Al、Mn、Ca、Si含量,以及均匀化温度、均匀化时间、挤压温度、挤压比、挤压速率、轧制温度、轧制比、轧制速率等加工参数与屈服强度、抗拉强度和延伸率等性能之间的构效关系,基于112个数据样本,以材料参数为输入建立了人工神经网络和支持向量机模型,2个模型对屈服强度、抗拉强度和延伸率的预测均有较高的精度,人工神经网络模型对屈服强度、抗拉伸强度和延伸率的R 2 分别为0.83、0.83和0.86,支持向量机模型的R 2 分别为0.79、0.93和0.79.刘彬等[55 ] 利用AZ31镁合金力学性能的38个实验数据样本,以取样方向、退火温度、退火时间等材料参数为输入,建立了抗拉强度、屈服强度和延伸率等的人工神经网络预测模型,利用全排列组合训练方式对模型参数优化,发现相比于试探法确定的模型参数,预测模型具有更高的平均决定系数和更低的平均误差,更准确地预测了AZ31镁合金不同退火条件下的力学性能.Li等[56 ] 以镁合金元素质量分数、铸造和变形工艺、热处理工艺、合金性能的实验温度等为输入,以抗拉强度、屈服强度、延伸率和腐蚀速率为目标量(输出),建立了LASSO (least absolute shrinkage and selection operator)回归、随机森林回归和支持向量回归模型,通过比较3个模型的平均绝对误差、均方误差和决定系数,发现随机森林模型的预测效果最好.Chaudry等[57 ] 利用1592个Al-Cu-Mg-x (x = Zn、Zr等)合金的硬度数据样本,以成分和时效温度、时效时间等材料参数为输入,建立了铝合金在各种时效处理条件下的硬度预测模型,梯度提升树模型的决定系数和均方误差分别达到0.94和7.27,准确地预测了Al-4Cu-0.5Mg-0.15Si-0.1Sc合金在175和225℃时效的性能.Cao等[58 ] 以单级时效、双级时效、回归再时效时间和温度等材料参数为输入,建立了多元线性回归、支持向量回归和广义回归神经网络等机器学习模型,预测不同时效处理的7N01铝合金硬度和耐腐蚀性能,预测结果表明单级时效和回归再时效均能使7N01铝合金达到比双级时效更高的强度,但双级时效铝合金的耐腐蚀性优于单级时效. ...
Property prediction of medical magnesium alloy based on machine learning
1
2021
... Xu等[54 ] 为了建立AZ31镁合金中Zn、Al、Mn、Ca、Si含量,以及均匀化温度、均匀化时间、挤压温度、挤压比、挤压速率、轧制温度、轧制比、轧制速率等加工参数与屈服强度、抗拉强度和延伸率等性能之间的构效关系,基于112个数据样本,以材料参数为输入建立了人工神经网络和支持向量机模型,2个模型对屈服强度、抗拉强度和延伸率的预测均有较高的精度,人工神经网络模型对屈服强度、抗拉伸强度和延伸率的R 2 分别为0.83、0.83和0.86,支持向量机模型的R 2 分别为0.79、0.93和0.79.刘彬等[55 ] 利用AZ31镁合金力学性能的38个实验数据样本,以取样方向、退火温度、退火时间等材料参数为输入,建立了抗拉强度、屈服强度和延伸率等的人工神经网络预测模型,利用全排列组合训练方式对模型参数优化,发现相比于试探法确定的模型参数,预测模型具有更高的平均决定系数和更低的平均误差,更准确地预测了AZ31镁合金不同退火条件下的力学性能.Li等[56 ] 以镁合金元素质量分数、铸造和变形工艺、热处理工艺、合金性能的实验温度等为输入,以抗拉强度、屈服强度、延伸率和腐蚀速率为目标量(输出),建立了LASSO (least absolute shrinkage and selection operator)回归、随机森林回归和支持向量回归模型,通过比较3个模型的平均绝对误差、均方误差和决定系数,发现随机森林模型的预测效果最好.Chaudry等[57 ] 利用1592个Al-Cu-Mg-x (x = Zn、Zr等)合金的硬度数据样本,以成分和时效温度、时效时间等材料参数为输入,建立了铝合金在各种时效处理条件下的硬度预测模型,梯度提升树模型的决定系数和均方误差分别达到0.94和7.27,准确地预测了Al-4Cu-0.5Mg-0.15Si-0.1Sc合金在175和225℃时效的性能.Cao等[58 ] 以单级时效、双级时效、回归再时效时间和温度等材料参数为输入,建立了多元线性回归、支持向量回归和广义回归神经网络等机器学习模型,预测不同时效处理的7N01铝合金硬度和耐腐蚀性能,预测结果表明单级时效和回归再时效均能使7N01铝合金达到比双级时效更高的强度,但双级时效铝合金的耐腐蚀性优于单级时效. ...
Machine learning-aided design of aluminum alloys with high performance
1
2021
... Xu等[54 ] 为了建立AZ31镁合金中Zn、Al、Mn、Ca、Si含量,以及均匀化温度、均匀化时间、挤压温度、挤压比、挤压速率、轧制温度、轧制比、轧制速率等加工参数与屈服强度、抗拉强度和延伸率等性能之间的构效关系,基于112个数据样本,以材料参数为输入建立了人工神经网络和支持向量机模型,2个模型对屈服强度、抗拉强度和延伸率的预测均有较高的精度,人工神经网络模型对屈服强度、抗拉伸强度和延伸率的R 2 分别为0.83、0.83和0.86,支持向量机模型的R 2 分别为0.79、0.93和0.79.刘彬等[55 ] 利用AZ31镁合金力学性能的38个实验数据样本,以取样方向、退火温度、退火时间等材料参数为输入,建立了抗拉强度、屈服强度和延伸率等的人工神经网络预测模型,利用全排列组合训练方式对模型参数优化,发现相比于试探法确定的模型参数,预测模型具有更高的平均决定系数和更低的平均误差,更准确地预测了AZ31镁合金不同退火条件下的力学性能.Li等[56 ] 以镁合金元素质量分数、铸造和变形工艺、热处理工艺、合金性能的实验温度等为输入,以抗拉强度、屈服强度、延伸率和腐蚀速率为目标量(输出),建立了LASSO (least absolute shrinkage and selection operator)回归、随机森林回归和支持向量回归模型,通过比较3个模型的平均绝对误差、均方误差和决定系数,发现随机森林模型的预测效果最好.Chaudry等[57 ] 利用1592个Al-Cu-Mg-x (x = Zn、Zr等)合金的硬度数据样本,以成分和时效温度、时效时间等材料参数为输入,建立了铝合金在各种时效处理条件下的硬度预测模型,梯度提升树模型的决定系数和均方误差分别达到0.94和7.27,准确地预测了Al-4Cu-0.5Mg-0.15Si-0.1Sc合金在175和225℃时效的性能.Cao等[58 ] 以单级时效、双级时效、回归再时效时间和温度等材料参数为输入,建立了多元线性回归、支持向量回归和广义回归神经网络等机器学习模型,预测不同时效处理的7N01铝合金硬度和耐腐蚀性能,预测结果表明单级时效和回归再时效均能使7N01铝合金达到比双级时效更高的强度,但双级时效铝合金的耐腐蚀性优于单级时效. ...
Predicting mechanical properties and corrosion resistance of heat-treated 7N01 aluminum alloy by machine learning methods
1
2020
... Xu等[54 ] 为了建立AZ31镁合金中Zn、Al、Mn、Ca、Si含量,以及均匀化温度、均匀化时间、挤压温度、挤压比、挤压速率、轧制温度、轧制比、轧制速率等加工参数与屈服强度、抗拉强度和延伸率等性能之间的构效关系,基于112个数据样本,以材料参数为输入建立了人工神经网络和支持向量机模型,2个模型对屈服强度、抗拉强度和延伸率的预测均有较高的精度,人工神经网络模型对屈服强度、抗拉伸强度和延伸率的R 2 分别为0.83、0.83和0.86,支持向量机模型的R 2 分别为0.79、0.93和0.79.刘彬等[55 ] 利用AZ31镁合金力学性能的38个实验数据样本,以取样方向、退火温度、退火时间等材料参数为输入,建立了抗拉强度、屈服强度和延伸率等的人工神经网络预测模型,利用全排列组合训练方式对模型参数优化,发现相比于试探法确定的模型参数,预测模型具有更高的平均决定系数和更低的平均误差,更准确地预测了AZ31镁合金不同退火条件下的力学性能.Li等[56 ] 以镁合金元素质量分数、铸造和变形工艺、热处理工艺、合金性能的实验温度等为输入,以抗拉强度、屈服强度、延伸率和腐蚀速率为目标量(输出),建立了LASSO (least absolute shrinkage and selection operator)回归、随机森林回归和支持向量回归模型,通过比较3个模型的平均绝对误差、均方误差和决定系数,发现随机森林模型的预测效果最好.Chaudry等[57 ] 利用1592个Al-Cu-Mg-x (x = Zn、Zr等)合金的硬度数据样本,以成分和时效温度、时效时间等材料参数为输入,建立了铝合金在各种时效处理条件下的硬度预测模型,梯度提升树模型的决定系数和均方误差分别达到0.94和7.27,准确地预测了Al-4Cu-0.5Mg-0.15Si-0.1Sc合金在175和225℃时效的性能.Cao等[58 ] 以单级时效、双级时效、回归再时效时间和温度等材料参数为输入,建立了多元线性回归、支持向量回归和广义回归神经网络等机器学习模型,预测不同时效处理的7N01铝合金硬度和耐腐蚀性能,预测结果表明单级时效和回归再时效均能使7N01铝合金达到比双级时效更高的强度,但双级时效铝合金的耐腐蚀性优于单级时效. ...
Modelling the correlation between processing parameters and properties in titanium alloys using artificial neural network
1
2001
... Malinov等[59 ] 基于764个钛合金数据样本,以成分、热处理条件和工作温度等材料参数为输入,建立了屈服强度、抗拉强度、延伸率、洛氏硬度、弹性模量、疲劳强度等力学性能的神经网络模型,利用预测结果得到的钛合金延伸率随温度变化及硬度随成分变化趋势与实验结果相符.相变诱导塑性(TRIP)钛合金具有较好的强度和延展性,获得广泛关注,但合金中通常包含昂贵的V、Nb、Mo等高熔点β 相稳定元素,Oh等[60 ] 利用人工神经网络,如图3 [60 ] 所示,基于30个Ti-4Al-2Fe-x Mn-0.18O合金的实验数据样本,以Mn含量和热处理温度为输入,建立拉伸强度和延伸率的机器学习模型,预测结果与实验结果的决定系数为99.9%,通过预测非昂贵合金化元素对钛合金性能的影响,开发出了具有更优性能的Ti-Al-Fe-Mn基TRIP合金,883℃热处理的Ti-4Al-2Fe-1.4Mn合金比强度和延伸分别达到289 MPa/(g·cm-3 )和34%.Yang等[61 ] 融合金属团簇理论与机器学习算法,基于82个β -Ti合金数据样本,以等效Mo当量(Mo-equivalent)和团簇公式(cluster-formula)为输入,建立了β -Ti合金弹性模量的XGBoost模型,预测了Ti-Mo-Nb-Zr-Sn-Ta合金的弹性模量,设计出了具有目标性能的合金成分,并进行了实验验证.Wu等[62 ] 将冶金理论融入类神经网络算法,开发出了“beta Low”学习器,基于164个Young's模量数据样本和112个相变温度数据样本,以材料成分为输入建立机器学习模型,开发出了Ti-12Nb-12Zr-12Sn (Ti-12)新型钛合金,Young's模量为43 GPa,且密度低、强度高(抗拉强度近900 MPa). ...
Property optimization of TRIP Ti alloys based on artificial neural network
4
2021
... Malinov等[59 ] 基于764个钛合金数据样本,以成分、热处理条件和工作温度等材料参数为输入,建立了屈服强度、抗拉强度、延伸率、洛氏硬度、弹性模量、疲劳强度等力学性能的神经网络模型,利用预测结果得到的钛合金延伸率随温度变化及硬度随成分变化趋势与实验结果相符.相变诱导塑性(TRIP)钛合金具有较好的强度和延展性,获得广泛关注,但合金中通常包含昂贵的V、Nb、Mo等高熔点β 相稳定元素,Oh等[60 ] 利用人工神经网络,如图3 [60 ] 所示,基于30个Ti-4Al-2Fe-x Mn-0.18O合金的实验数据样本,以Mn含量和热处理温度为输入,建立拉伸强度和延伸率的机器学习模型,预测结果与实验结果的决定系数为99.9%,通过预测非昂贵合金化元素对钛合金性能的影响,开发出了具有更优性能的Ti-Al-Fe-Mn基TRIP合金,883℃热处理的Ti-4Al-2Fe-1.4Mn合金比强度和延伸分别达到289 MPa/(g·cm-3 )和34%.Yang等[61 ] 融合金属团簇理论与机器学习算法,基于82个β -Ti合金数据样本,以等效Mo当量(Mo-equivalent)和团簇公式(cluster-formula)为输入,建立了β -Ti合金弹性模量的XGBoost模型,预测了Ti-Mo-Nb-Zr-Sn-Ta合金的弹性模量,设计出了具有目标性能的合金成分,并进行了实验验证.Wu等[62 ] 将冶金理论融入类神经网络算法,开发出了“beta Low”学习器,基于164个Young's模量数据样本和112个相变温度数据样本,以材料成分为输入建立机器学习模型,开发出了Ti-12Nb-12Zr-12Sn (Ti-12)新型钛合金,Young's模量为43 GPa,且密度低、强度高(抗拉强度近900 MPa). ...
... [60 ]所示,基于30个Ti-4Al-2Fe-x Mn-0.18O合金的实验数据样本,以Mn含量和热处理温度为输入,建立拉伸强度和延伸率的机器学习模型,预测结果与实验结果的决定系数为99.9%,通过预测非昂贵合金化元素对钛合金性能的影响,开发出了具有更优性能的Ti-Al-Fe-Mn基TRIP合金,883℃热处理的Ti-4Al-2Fe-1.4Mn合金比强度和延伸分别达到289 MPa/(g·cm-3 )和34%.Yang等[61 ] 融合金属团簇理论与机器学习算法,基于82个β -Ti合金数据样本,以等效Mo当量(Mo-equivalent)和团簇公式(cluster-formula)为输入,建立了β -Ti合金弹性模量的XGBoost模型,预测了Ti-Mo-Nb-Zr-Sn-Ta合金的弹性模量,设计出了具有目标性能的合金成分,并进行了实验验证.Wu等[62 ] 将冶金理论融入类神经网络算法,开发出了“beta Low”学习器,基于164个Young's模量数据样本和112个相变温度数据样本,以材料成分为输入建立机器学习模型,开发出了Ti-12Nb-12Zr-12Sn (Ti-12)新型钛合金,Young's模量为43 GPa,且密度低、强度高(抗拉强度近900 MPa). ...
... [
60 ]
Property optimization workflow of TRIP Ti alloys based on artificial neural network (UTS—ultimate tensile strength, El—elongation, HT—heat treatment) (a, b)<sup>[<xref ref-type="bibr" rid="R60">60</xref>]</sup> Fig.3 ![]()
<strong>2.4 </strong>服役行为预测 材料服役行为是指材料在实际环境中使用时的表现.以材料服役环境因素为输入,以服役性能(如腐蚀速率、疲劳强度、蠕变寿命)为目标量,建立机器学习模型,可以对材料服役行为进行预测.如果以材料参数和环境因素为输入建立机器学习模型,亦可设计出高性能的材料. ...
... [
60 ]
Fig.3 ![]()
<strong>2.4 </strong>服役行为预测 材料服役行为是指材料在实际环境中使用时的表现.以材料服役环境因素为输入,以服役性能(如腐蚀速率、疲劳强度、蠕变寿命)为目标量,建立机器学习模型,可以对材料服役行为进行预测.如果以材料参数和环境因素为输入建立机器学习模型,亦可设计出高性能的材料. ...
Cluster-formula-embedded machine learning for design of multicomponent β -Ti alloys with low Young's modulus
1
2020
... Malinov等[59 ] 基于764个钛合金数据样本,以成分、热处理条件和工作温度等材料参数为输入,建立了屈服强度、抗拉强度、延伸率、洛氏硬度、弹性模量、疲劳强度等力学性能的神经网络模型,利用预测结果得到的钛合金延伸率随温度变化及硬度随成分变化趋势与实验结果相符.相变诱导塑性(TRIP)钛合金具有较好的强度和延展性,获得广泛关注,但合金中通常包含昂贵的V、Nb、Mo等高熔点β 相稳定元素,Oh等[60 ] 利用人工神经网络,如图3 [60 ] 所示,基于30个Ti-4Al-2Fe-x Mn-0.18O合金的实验数据样本,以Mn含量和热处理温度为输入,建立拉伸强度和延伸率的机器学习模型,预测结果与实验结果的决定系数为99.9%,通过预测非昂贵合金化元素对钛合金性能的影响,开发出了具有更优性能的Ti-Al-Fe-Mn基TRIP合金,883℃热处理的Ti-4Al-2Fe-1.4Mn合金比强度和延伸分别达到289 MPa/(g·cm-3 )和34%.Yang等[61 ] 融合金属团簇理论与机器学习算法,基于82个β -Ti合金数据样本,以等效Mo当量(Mo-equivalent)和团簇公式(cluster-formula)为输入,建立了β -Ti合金弹性模量的XGBoost模型,预测了Ti-Mo-Nb-Zr-Sn-Ta合金的弹性模量,设计出了具有目标性能的合金成分,并进行了实验验证.Wu等[62 ] 将冶金理论融入类神经网络算法,开发出了“beta Low”学习器,基于164个Young's模量数据样本和112个相变温度数据样本,以材料成分为输入建立机器学习模型,开发出了Ti-12Nb-12Zr-12Sn (Ti-12)新型钛合金,Young's模量为43 GPa,且密度低、强度高(抗拉强度近900 MPa). ...
Machine learning recommends affordable new Ti alloy with bone-like modulus
1
2020
... Malinov等[59 ] 基于764个钛合金数据样本,以成分、热处理条件和工作温度等材料参数为输入,建立了屈服强度、抗拉强度、延伸率、洛氏硬度、弹性模量、疲劳强度等力学性能的神经网络模型,利用预测结果得到的钛合金延伸率随温度变化及硬度随成分变化趋势与实验结果相符.相变诱导塑性(TRIP)钛合金具有较好的强度和延展性,获得广泛关注,但合金中通常包含昂贵的V、Nb、Mo等高熔点β 相稳定元素,Oh等[60 ] 利用人工神经网络,如图3 [60 ] 所示,基于30个Ti-4Al-2Fe-x Mn-0.18O合金的实验数据样本,以Mn含量和热处理温度为输入,建立拉伸强度和延伸率的机器学习模型,预测结果与实验结果的决定系数为99.9%,通过预测非昂贵合金化元素对钛合金性能的影响,开发出了具有更优性能的Ti-Al-Fe-Mn基TRIP合金,883℃热处理的Ti-4Al-2Fe-1.4Mn合金比强度和延伸分别达到289 MPa/(g·cm-3 )和34%.Yang等[61 ] 融合金属团簇理论与机器学习算法,基于82个β -Ti合金数据样本,以等效Mo当量(Mo-equivalent)和团簇公式(cluster-formula)为输入,建立了β -Ti合金弹性模量的XGBoost模型,预测了Ti-Mo-Nb-Zr-Sn-Ta合金的弹性模量,设计出了具有目标性能的合金成分,并进行了实验验证.Wu等[62 ] 将冶金理论融入类神经网络算法,开发出了“beta Low”学习器,基于164个Young's模量数据样本和112个相变温度数据样本,以材料成分为输入建立机器学习模型,开发出了Ti-12Nb-12Zr-12Sn (Ti-12)新型钛合金,Young's模量为43 GPa,且密度低、强度高(抗拉强度近900 MPa). ...
An artificial neural network for predicting corrosion rate and hardness of magnesium alloys
1
2016
... Xia等[63 ] 基于53个镁合金腐蚀数据样本,以合金成分为输入训练人工神经网络模型,准确地预测了镁合金在海水(0.1 mol/L NaCl溶液)中的腐蚀速率,同时利用模糊曲线分析得到了Zn、Ca、Zr、Gd、Sr等合金元素对镁合金海水腐蚀的影响规律和协同效应,指导耐蚀镁合金的设计.Wen等[64 ] 基于46个3C钢海水腐蚀数据样本,以水温、含氧量、含盐量、pH值、开路电位等5个环境因素为输入,采用粒子群算法优化机器学习模型参数,建立支持向量机模型预测腐蚀速率,精度达80%,并分析了环境因素对碳钢腐蚀速率的影响规律.Fang等[65 ] 利用407个锌大气环境腐蚀数据样本、315个钢腐蚀数据样本,以温度、暴露时间、润湿时间、SO2 浓度、Cl- 浓度等环境因素为输入,建立了腐蚀失厚的人工神经网络和支持向量机模型,预测了金属大气环境腐蚀速率.Cavanaugh等[66 ] 利用人工神经网络算法,研究了环境因素对铝合金点蚀的影响.Diao等[67 ] 利用支持向量机对不同成分低合金钢在不同海域的腐蚀速率进行了准确预测.Shi等[68 ] 利用神经网络算法,以屈服强度、电导率、温度、主应力因子等材料性能和环境因素为输入,准确预测了600镍基合金在高温高压水环境中应力腐蚀裂纹的扩展速率,预测结果与实验的相关系数达0.98;基于预测结果,通过模糊曲线敏感性分析,研究了各变量对裂纹扩展速率的影响,筛选出应力强度因子和腐蚀电位是应力腐蚀裂纹扩展速率的主要影响因素. ...
Corrosion rate prediction of 3C steel under different seawater environment by using support vector regression
1
2009
... Xia等[63 ] 基于53个镁合金腐蚀数据样本,以合金成分为输入训练人工神经网络模型,准确地预测了镁合金在海水(0.1 mol/L NaCl溶液)中的腐蚀速率,同时利用模糊曲线分析得到了Zn、Ca、Zr、Gd、Sr等合金元素对镁合金海水腐蚀的影响规律和协同效应,指导耐蚀镁合金的设计.Wen等[64 ] 基于46个3C钢海水腐蚀数据样本,以水温、含氧量、含盐量、pH值、开路电位等5个环境因素为输入,采用粒子群算法优化机器学习模型参数,建立支持向量机模型预测腐蚀速率,精度达80%,并分析了环境因素对碳钢腐蚀速率的影响规律.Fang等[65 ] 利用407个锌大气环境腐蚀数据样本、315个钢腐蚀数据样本,以温度、暴露时间、润湿时间、SO2 浓度、Cl- 浓度等环境因素为输入,建立了腐蚀失厚的人工神经网络和支持向量机模型,预测了金属大气环境腐蚀速率.Cavanaugh等[66 ] 利用人工神经网络算法,研究了环境因素对铝合金点蚀的影响.Diao等[67 ] 利用支持向量机对不同成分低合金钢在不同海域的腐蚀速率进行了准确预测.Shi等[68 ] 利用神经网络算法,以屈服强度、电导率、温度、主应力因子等材料性能和环境因素为输入,准确预测了600镍基合金在高温高压水环境中应力腐蚀裂纹的扩展速率,预测结果与实验的相关系数达0.98;基于预测结果,通过模糊曲线敏感性分析,研究了各变量对裂纹扩展速率的影响,筛选出应力强度因子和腐蚀电位是应力腐蚀裂纹扩展速率的主要影响因素. ...
Hybrid genetic algorithms and support vector regression in forecasting atmospheric corrosion of metallic materials
1
2008
... Xia等[63 ] 基于53个镁合金腐蚀数据样本,以合金成分为输入训练人工神经网络模型,准确地预测了镁合金在海水(0.1 mol/L NaCl溶液)中的腐蚀速率,同时利用模糊曲线分析得到了Zn、Ca、Zr、Gd、Sr等合金元素对镁合金海水腐蚀的影响规律和协同效应,指导耐蚀镁合金的设计.Wen等[64 ] 基于46个3C钢海水腐蚀数据样本,以水温、含氧量、含盐量、pH值、开路电位等5个环境因素为输入,采用粒子群算法优化机器学习模型参数,建立支持向量机模型预测腐蚀速率,精度达80%,并分析了环境因素对碳钢腐蚀速率的影响规律.Fang等[65 ] 利用407个锌大气环境腐蚀数据样本、315个钢腐蚀数据样本,以温度、暴露时间、润湿时间、SO2 浓度、Cl- 浓度等环境因素为输入,建立了腐蚀失厚的人工神经网络和支持向量机模型,预测了金属大气环境腐蚀速率.Cavanaugh等[66 ] 利用人工神经网络算法,研究了环境因素对铝合金点蚀的影响.Diao等[67 ] 利用支持向量机对不同成分低合金钢在不同海域的腐蚀速率进行了准确预测.Shi等[68 ] 利用神经网络算法,以屈服强度、电导率、温度、主应力因子等材料性能和环境因素为输入,准确预测了600镍基合金在高温高压水环境中应力腐蚀裂纹的扩展速率,预测结果与实验的相关系数达0.98;基于预测结果,通过模糊曲线敏感性分析,研究了各变量对裂纹扩展速率的影响,筛选出应力强度因子和腐蚀电位是应力腐蚀裂纹扩展速率的主要影响因素. ...
Modeling the environmental dependence of pit growth using neural network approaches
1
2010
... Xia等[63 ] 基于53个镁合金腐蚀数据样本,以合金成分为输入训练人工神经网络模型,准确地预测了镁合金在海水(0.1 mol/L NaCl溶液)中的腐蚀速率,同时利用模糊曲线分析得到了Zn、Ca、Zr、Gd、Sr等合金元素对镁合金海水腐蚀的影响规律和协同效应,指导耐蚀镁合金的设计.Wen等[64 ] 基于46个3C钢海水腐蚀数据样本,以水温、含氧量、含盐量、pH值、开路电位等5个环境因素为输入,采用粒子群算法优化机器学习模型参数,建立支持向量机模型预测腐蚀速率,精度达80%,并分析了环境因素对碳钢腐蚀速率的影响规律.Fang等[65 ] 利用407个锌大气环境腐蚀数据样本、315个钢腐蚀数据样本,以温度、暴露时间、润湿时间、SO2 浓度、Cl- 浓度等环境因素为输入,建立了腐蚀失厚的人工神经网络和支持向量机模型,预测了金属大气环境腐蚀速率.Cavanaugh等[66 ] 利用人工神经网络算法,研究了环境因素对铝合金点蚀的影响.Diao等[67 ] 利用支持向量机对不同成分低合金钢在不同海域的腐蚀速率进行了准确预测.Shi等[68 ] 利用神经网络算法,以屈服强度、电导率、温度、主应力因子等材料性能和环境因素为输入,准确预测了600镍基合金在高温高压水环境中应力腐蚀裂纹的扩展速率,预测结果与实验的相关系数达0.98;基于预测结果,通过模糊曲线敏感性分析,研究了各变量对裂纹扩展速率的影响,筛选出应力强度因子和腐蚀电位是应力腐蚀裂纹扩展速率的主要影响因素. ...
Improvement of the machine learning-based corrosion rate prediction model through the optimization of input features
1
2021
... Xia等[63 ] 基于53个镁合金腐蚀数据样本,以合金成分为输入训练人工神经网络模型,准确地预测了镁合金在海水(0.1 mol/L NaCl溶液)中的腐蚀速率,同时利用模糊曲线分析得到了Zn、Ca、Zr、Gd、Sr等合金元素对镁合金海水腐蚀的影响规律和协同效应,指导耐蚀镁合金的设计.Wen等[64 ] 基于46个3C钢海水腐蚀数据样本,以水温、含氧量、含盐量、pH值、开路电位等5个环境因素为输入,采用粒子群算法优化机器学习模型参数,建立支持向量机模型预测腐蚀速率,精度达80%,并分析了环境因素对碳钢腐蚀速率的影响规律.Fang等[65 ] 利用407个锌大气环境腐蚀数据样本、315个钢腐蚀数据样本,以温度、暴露时间、润湿时间、SO2 浓度、Cl- 浓度等环境因素为输入,建立了腐蚀失厚的人工神经网络和支持向量机模型,预测了金属大气环境腐蚀速率.Cavanaugh等[66 ] 利用人工神经网络算法,研究了环境因素对铝合金点蚀的影响.Diao等[67 ] 利用支持向量机对不同成分低合金钢在不同海域的腐蚀速率进行了准确预测.Shi等[68 ] 利用神经网络算法,以屈服强度、电导率、温度、主应力因子等材料性能和环境因素为输入,准确预测了600镍基合金在高温高压水环境中应力腐蚀裂纹的扩展速率,预测结果与实验的相关系数达0.98;基于预测结果,通过模糊曲线敏感性分析,研究了各变量对裂纹扩展速率的影响,筛选出应力强度因子和腐蚀电位是应力腐蚀裂纹扩展速率的主要影响因素. ...
Prediction of primary water stress corrosion crack growth rates in Alloy 600 using artificial neural networks
1
2015
... Xia等[63 ] 基于53个镁合金腐蚀数据样本,以合金成分为输入训练人工神经网络模型,准确地预测了镁合金在海水(0.1 mol/L NaCl溶液)中的腐蚀速率,同时利用模糊曲线分析得到了Zn、Ca、Zr、Gd、Sr等合金元素对镁合金海水腐蚀的影响规律和协同效应,指导耐蚀镁合金的设计.Wen等[64 ] 基于46个3C钢海水腐蚀数据样本,以水温、含氧量、含盐量、pH值、开路电位等5个环境因素为输入,采用粒子群算法优化机器学习模型参数,建立支持向量机模型预测腐蚀速率,精度达80%,并分析了环境因素对碳钢腐蚀速率的影响规律.Fang等[65 ] 利用407个锌大气环境腐蚀数据样本、315个钢腐蚀数据样本,以温度、暴露时间、润湿时间、SO2 浓度、Cl- 浓度等环境因素为输入,建立了腐蚀失厚的人工神经网络和支持向量机模型,预测了金属大气环境腐蚀速率.Cavanaugh等[66 ] 利用人工神经网络算法,研究了环境因素对铝合金点蚀的影响.Diao等[67 ] 利用支持向量机对不同成分低合金钢在不同海域的腐蚀速率进行了准确预测.Shi等[68 ] 利用神经网络算法,以屈服强度、电导率、温度、主应力因子等材料性能和环境因素为输入,准确预测了600镍基合金在高温高压水环境中应力腐蚀裂纹的扩展速率,预测结果与实验的相关系数达0.98;基于预测结果,通过模糊曲线敏感性分析,研究了各变量对裂纹扩展速率的影响,筛选出应力强度因子和腐蚀电位是应力腐蚀裂纹扩展速率的主要影响因素. ...
Exploration of data science techniques to predict fatigue strength of steel from composition and processing parameters
1
2014
... Agrawal等[69 ] 基于437个钢的疲劳强度数据样本,以成分、变形量、回火温度、冷却速率等25个材料参数为输入,建立了钢的疲劳强度预测模型,评估对比了人工神经网络、决策树、支持向量机等12种机器学习模型的预测效果,模型的最低误差小于4%,基于相关性分析讨论了各种材料参数对钢疲劳强度的影响.Kamble等[70 ] 利用钢在6种实验条件的疲劳数据样本,以试样厚度、载荷、加载频率等实验参量为输入,建立K近邻和岭回归模型,对稳态和非稳态疲劳裂纹扩展速率进行预测,准确率超过85%,同时讨论了数据预处理、模型参数优化等对裂纹扩展速率预测结果的影响.He等[71 ] 基于AISI316、AISI4140和CA6NM等3个钢种的24、58、89个数据样本,以材料成分、力学性能(如抗拉强度、硬度),以及加载应力等为输入,训练并评估了人工神经网络、支持向量机和随机森林等机器学习模型,准确预测了钢的疲劳寿命,预测相关性超过0.9,基于机器学习模型预测结果,利用Bayesian优化方法对疲劳极限进行了逆向分析与设计. ...
Machine learning approach to predict fatigue crack growth
1
2021
... Agrawal等[69 ] 基于437个钢的疲劳强度数据样本,以成分、变形量、回火温度、冷却速率等25个材料参数为输入,建立了钢的疲劳强度预测模型,评估对比了人工神经网络、决策树、支持向量机等12种机器学习模型的预测效果,模型的最低误差小于4%,基于相关性分析讨论了各种材料参数对钢疲劳强度的影响.Kamble等[70 ] 利用钢在6种实验条件的疲劳数据样本,以试样厚度、载荷、加载频率等实验参量为输入,建立K近邻和岭回归模型,对稳态和非稳态疲劳裂纹扩展速率进行预测,准确率超过85%,同时讨论了数据预处理、模型参数优化等对裂纹扩展速率预测结果的影响.He等[71 ] 基于AISI316、AISI4140和CA6NM等3个钢种的24、58、89个数据样本,以材料成分、力学性能(如抗拉强度、硬度),以及加载应力等为输入,训练并评估了人工神经网络、支持向量机和随机森林等机器学习模型,准确预测了钢的疲劳寿命,预测相关性超过0.9,基于机器学习模型预测结果,利用Bayesian优化方法对疲劳极限进行了逆向分析与设计. ...
Machine learning-based predictions of fatigue life and fatigue limit for steels
1
2021
... Agrawal等[69 ] 基于437个钢的疲劳强度数据样本,以成分、变形量、回火温度、冷却速率等25个材料参数为输入,建立了钢的疲劳强度预测模型,评估对比了人工神经网络、决策树、支持向量机等12种机器学习模型的预测效果,模型的最低误差小于4%,基于相关性分析讨论了各种材料参数对钢疲劳强度的影响.Kamble等[70 ] 利用钢在6种实验条件的疲劳数据样本,以试样厚度、载荷、加载频率等实验参量为输入,建立K近邻和岭回归模型,对稳态和非稳态疲劳裂纹扩展速率进行预测,准确率超过85%,同时讨论了数据预处理、模型参数优化等对裂纹扩展速率预测结果的影响.He等[71 ] 基于AISI316、AISI4140和CA6NM等3个钢种的24、58、89个数据样本,以材料成分、力学性能(如抗拉强度、硬度),以及加载应力等为输入,训练并评估了人工神经网络、支持向量机和随机森林等机器学习模型,准确预测了钢的疲劳寿命,预测相关性超过0.9,基于机器学习模型预测结果,利用Bayesian优化方法对疲劳极限进行了逆向分析与设计. ...
Predicting creep rupture life of Ni-based single crystal superalloys using divide-and-conquer approach based machine learning
1
2020
... Liu等[72 ] 利用合金成分,固溶温度、时效时间、晶格常数、层错能,以及蠕变温度、加载压力等27个参量特征,对具有不同蠕变机制的266个数据样本进行聚类,分别训练并评估了随机森林、支持向量机、岭回归等机器学习模型对各类蠕变寿命的预测精度,最优模型的预测相关性超过0.9.Shin等[73 ] 基于高通量热力学计算得到了166种成分耐热钢的85502个不同固溶处理和蠕变条件下的相体积、相成分,以及蠕变寿命数据样本,建立了包括合金成分、相体积比、相成分、实验温度等466个特征,采用相关系数和最大信息系数法进行特征筛选,以高排序特征为输入,评估了随机森林、核岭回归等5种机器学习模型,准确预测了耐热钢的蠕变寿命,精度超过90%.Hu等[74 ] 基于580个镍基高温合金数据样本,以成分、γ 相体积分数、γ ′相体积分数等14个材料参数为输入,建立高温合金蠕变寿命的人工神经网络预测模型,利用遗传算法对模型参数进行优化,预测精度超过90%. ...
Modern data analytics approach to predict creep of high-temperature alloys
1
2019
... Liu等[72 ] 利用合金成分,固溶温度、时效时间、晶格常数、层错能,以及蠕变温度、加载压力等27个参量特征,对具有不同蠕变机制的266个数据样本进行聚类,分别训练并评估了随机森林、支持向量机、岭回归等机器学习模型对各类蠕变寿命的预测精度,最优模型的预测相关性超过0.9.Shin等[73 ] 基于高通量热力学计算得到了166种成分耐热钢的85502个不同固溶处理和蠕变条件下的相体积、相成分,以及蠕变寿命数据样本,建立了包括合金成分、相体积比、相成分、实验温度等466个特征,采用相关系数和最大信息系数法进行特征筛选,以高排序特征为输入,评估了随机森林、核岭回归等5种机器学习模型,准确预测了耐热钢的蠕变寿命,精度超过90%.Hu等[74 ] 基于580个镍基高温合金数据样本,以成分、γ 相体积分数、γ ′相体积分数等14个材料参数为输入,建立高温合金蠕变寿命的人工神经网络预测模型,利用遗传算法对模型参数进行优化,预测精度超过90%. ...
Two-way design of alloys for advanced ultra supercritical plants based on machine learning
1
2018
... Liu等[72 ] 利用合金成分,固溶温度、时效时间、晶格常数、层错能,以及蠕变温度、加载压力等27个参量特征,对具有不同蠕变机制的266个数据样本进行聚类,分别训练并评估了随机森林、支持向量机、岭回归等机器学习模型对各类蠕变寿命的预测精度,最优模型的预测相关性超过0.9.Shin等[73 ] 基于高通量热力学计算得到了166种成分耐热钢的85502个不同固溶处理和蠕变条件下的相体积、相成分,以及蠕变寿命数据样本,建立了包括合金成分、相体积比、相成分、实验温度等466个特征,采用相关系数和最大信息系数法进行特征筛选,以高排序特征为输入,评估了随机森林、核岭回归等5种机器学习模型,准确预测了耐热钢的蠕变寿命,精度超过90%.Hu等[74 ] 基于580个镍基高温合金数据样本,以成分、γ 相体积分数、γ ′相体积分数等14个材料参数为输入,建立高温合金蠕变寿命的人工神经网络预测模型,利用遗传算法对模型参数进行优化,预测精度超过90%. ...
Information-theoretic approach for the discovery of design rules for crystal chemistry
1
2012
... Kong等[75 ] 利用价电子浓度、电负性差、Zunger赝势半径差等7个材料因子为输入建立决策树模型,对34种不同晶体结构的840个AB 2 型化合物结构进行分类,基于决策树模型分支的特点,挖掘出了决定AB 2 型化合物晶体结构的主要控制参量.为了探究形状记忆合金相变温度的主要决定因素,Xue等[76 ] 通过比较多元线性回归、多项式回归、不同核函数支持向量机回归等5个机器学习模型在训练集中的预测误差,筛选出了以掺杂元素电负性、d电子轨道半径、价电子浓度等材料因子为输入的二阶多项式模型,基于元素电负性和价电子浓度与合金化合键强度相关,d电子轨道半径与原子尺寸相关的先验知识,分析得到了形状记忆合金相变温度与弹性模量,以及掺杂元素引入的局域应变场的相关性. ...
An informatics approach to transformation temperatures of NiTi-based shape memory alloys
1
2017
... Kong等[75 ] 利用价电子浓度、电负性差、Zunger赝势半径差等7个材料因子为输入建立决策树模型,对34种不同晶体结构的840个AB 2 型化合物结构进行分类,基于决策树模型分支的特点,挖掘出了决定AB 2 型化合物晶体结构的主要控制参量.为了探究形状记忆合金相变温度的主要决定因素,Xue等[76 ] 通过比较多元线性回归、多项式回归、不同核函数支持向量机回归等5个机器学习模型在训练集中的预测误差,筛选出了以掺杂元素电负性、d电子轨道半径、价电子浓度等材料因子为输入的二阶多项式模型,基于元素电负性和价电子浓度与合金化合键强度相关,d电子轨道半径与原子尺寸相关的先验知识,分析得到了形状记忆合金相变温度与弹性模量,以及掺杂元素引入的局域应变场的相关性. ...
Machine-learning-assisted materials discovery using failed experiments
1
2016
... 在机器学习预测模型的基础上,建立“白箱模型”或进行统计和可视化分析,可以辅助分析和理解目标量的主要影响因素.Raccuglia等[77 ] 基于3955条模板亚硒酸钒杂化材料合成反应实验数据,以元素原子性质构建反应物的材料因子,以反应温度、反应时间、溶液pH值等为材料参数,训练支持向量机模型对能否成功合成杂化材料进行预测,准确率达89%,超过经验化学家78%的预测准确率.他们利用支持向量机模型的预测数据训练决策树模型,建立了可解释的if-then准则,分析了反应物和反应条件的阈值,得到了合成该类杂化材料新工艺,指导反应物及合成条件的选择和设计.Iwasaki等[78 ] 使用因子分解渐近Bayesian推理分层专家混合(FAB/HME)的可解释机器学习方法指导新型热电材料开发,通过分段稀疏化线性建模,兼顾模型泛化能力和可解释性,如图4 [78 ] 所示,从机器学习模型训练到决策树,将搜索空间分为4类,对每类空间进行回归建模,发现自旋轨道相互作用较大的原子具有局域自旋极化,能够增强反常能斯特(Nernst)效应,利用这一发现指导自旋驱动的热电材料研发,制备出了Sebek系数(S )达13.04 μV/K的Co48.9 Pt51.1 N7.2 热电材料.Wu等[79 ] 基于321个“近共晶”(亚共晶,过共晶)高熵合金数据,建立了成分和共晶偏离度的人工神经网络模型,通过对400个预测数据的元素分布规律统计和可视化分析,发现Al和Cr狭窄分布的现象,说明2种元素在共晶高熵合金形成过程中存在协同效应,提出了共晶高熵合金新设计原则,基于该原则设计的共晶高熵合金抗拉强度达到约1300 MPa,延伸率约20%.Wen等[80 ] 利用领域知识构建了高熵合金固溶强化的材料因子,利用多种机器学习算法对材料因子和高熵合金传统固溶强化模型(S-模型、T-模型、V-模型)的关键参量进行筛选,发现原子电负性差是高熵合金固溶强化的控制参量,建立了基于电负性差的高熵合金固溶强化数学表达式,模型精度相对于传统模型有所提升且简洁易用,如图5 [80 ] 所示.Si等[81 ] 利用多个机器学习模型对14个材料特征进行筛选,发现原子半径差、价电子浓度、电负性差、经验参数Λ 、经验参数Ω 和剪切模量错配度等是决定Zr-Ti-Nb-O固溶体强度的关键特征,通过添加氧和金属原子间电负性差的参量,提升了传统屈服强度公式精度,同时发现价电子浓度、经验参数Λ 、剪切模量错配度和局域模量错配度是合金塑性的主要影响因素,通过可视化断裂应变与关键特征,提出了高塑性固溶体的设计准则.Xie等[82 ] 基于11101个数据样本,利用热轧钢板成分和生产工艺等27个材料参数为输入,建立深度神经网络模型预测热轧钢板屈服强度、抗拉强度、延伸率和冲击功等力学性能,均方根相对误差分别为4.7%、2.9%、7.7%和16.2%,基于预测模型,采用局部可解释算法(LIME)对深度神经网络模型进行了解释和知识提取,分析表明均匀化后的最后冷却温度是屈服强度和抗拉强度最重要的影响参量,Nb、Cr和V等是延伸率的重要影响元素,C含量主要影响材料的冲击功等. ...
Identification of advanced spin-driven thermoelectric materials via interpretable machine learning
4
2019
... 在机器学习预测模型的基础上,建立“白箱模型”或进行统计和可视化分析,可以辅助分析和理解目标量的主要影响因素.Raccuglia等[77 ] 基于3955条模板亚硒酸钒杂化材料合成反应实验数据,以元素原子性质构建反应物的材料因子,以反应温度、反应时间、溶液pH值等为材料参数,训练支持向量机模型对能否成功合成杂化材料进行预测,准确率达89%,超过经验化学家78%的预测准确率.他们利用支持向量机模型的预测数据训练决策树模型,建立了可解释的if-then准则,分析了反应物和反应条件的阈值,得到了合成该类杂化材料新工艺,指导反应物及合成条件的选择和设计.Iwasaki等[78 ] 使用因子分解渐近Bayesian推理分层专家混合(FAB/HME)的可解释机器学习方法指导新型热电材料开发,通过分段稀疏化线性建模,兼顾模型泛化能力和可解释性,如图4 [78 ] 所示,从机器学习模型训练到决策树,将搜索空间分为4类,对每类空间进行回归建模,发现自旋轨道相互作用较大的原子具有局域自旋极化,能够增强反常能斯特(Nernst)效应,利用这一发现指导自旋驱动的热电材料研发,制备出了Sebek系数(S )达13.04 μV/K的Co48.9 Pt51.1 N7.2 热电材料.Wu等[79 ] 基于321个“近共晶”(亚共晶,过共晶)高熵合金数据,建立了成分和共晶偏离度的人工神经网络模型,通过对400个预测数据的元素分布规律统计和可视化分析,发现Al和Cr狭窄分布的现象,说明2种元素在共晶高熵合金形成过程中存在协同效应,提出了共晶高熵合金新设计原则,基于该原则设计的共晶高熵合金抗拉强度达到约1300 MPa,延伸率约20%.Wen等[80 ] 利用领域知识构建了高熵合金固溶强化的材料因子,利用多种机器学习算法对材料因子和高熵合金传统固溶强化模型(S-模型、T-模型、V-模型)的关键参量进行筛选,发现原子电负性差是高熵合金固溶强化的控制参量,建立了基于电负性差的高熵合金固溶强化数学表达式,模型精度相对于传统模型有所提升且简洁易用,如图5 [80 ] 所示.Si等[81 ] 利用多个机器学习模型对14个材料特征进行筛选,发现原子半径差、价电子浓度、电负性差、经验参数Λ 、经验参数Ω 和剪切模量错配度等是决定Zr-Ti-Nb-O固溶体强度的关键特征,通过添加氧和金属原子间电负性差的参量,提升了传统屈服强度公式精度,同时发现价电子浓度、经验参数Λ 、剪切模量错配度和局域模量错配度是合金塑性的主要影响因素,通过可视化断裂应变与关键特征,提出了高塑性固溶体的设计准则.Xie等[82 ] 基于11101个数据样本,利用热轧钢板成分和生产工艺等27个材料参数为输入,建立深度神经网络模型预测热轧钢板屈服强度、抗拉强度、延伸率和冲击功等力学性能,均方根相对误差分别为4.7%、2.9%、7.7%和16.2%,基于预测模型,采用局部可解释算法(LIME)对深度神经网络模型进行了解释和知识提取,分析表明均匀化后的最后冷却温度是屈服强度和抗拉强度最重要的影响参量,Nb、Cr和V等是延伸率的重要影响元素,C含量主要影响材料的冲击功等. ...
... [78 ]所示,从机器学习模型训练到决策树,将搜索空间分为4类,对每类空间进行回归建模,发现自旋轨道相互作用较大的原子具有局域自旋极化,能够增强反常能斯特(Nernst)效应,利用这一发现指导自旋驱动的热电材料研发,制备出了Sebek系数(S )达13.04 μV/K的Co48.9 Pt51.1 N7.2 热电材料.Wu等[79 ] 基于321个“近共晶”(亚共晶,过共晶)高熵合金数据,建立了成分和共晶偏离度的人工神经网络模型,通过对400个预测数据的元素分布规律统计和可视化分析,发现Al和Cr狭窄分布的现象,说明2种元素在共晶高熵合金形成过程中存在协同效应,提出了共晶高熵合金新设计原则,基于该原则设计的共晶高熵合金抗拉强度达到约1300 MPa,延伸率约20%.Wen等[80 ] 利用领域知识构建了高熵合金固溶强化的材料因子,利用多种机器学习算法对材料因子和高熵合金传统固溶强化模型(S-模型、T-模型、V-模型)的关键参量进行筛选,发现原子电负性差是高熵合金固溶强化的控制参量,建立了基于电负性差的高熵合金固溶强化数学表达式,模型精度相对于传统模型有所提升且简洁易用,如图5 [80 ] 所示.Si等[81 ] 利用多个机器学习模型对14个材料特征进行筛选,发现原子半径差、价电子浓度、电负性差、经验参数Λ 、经验参数Ω 和剪切模量错配度等是决定Zr-Ti-Nb-O固溶体强度的关键特征,通过添加氧和金属原子间电负性差的参量,提升了传统屈服强度公式精度,同时发现价电子浓度、经验参数Λ 、剪切模量错配度和局域模量错配度是合金塑性的主要影响因素,通过可视化断裂应变与关键特征,提出了高塑性固溶体的设计准则.Xie等[82 ] 基于11101个数据样本,利用热轧钢板成分和生产工艺等27个材料参数为输入,建立深度神经网络模型预测热轧钢板屈服强度、抗拉强度、延伸率和冲击功等力学性能,均方根相对误差分别为4.7%、2.9%、7.7%和16.2%,基于预测模型,采用局部可解释算法(LIME)对深度神经网络模型进行了解释和知识提取,分析表明均匀化后的最后冷却温度是屈服强度和抗拉强度最重要的影响参量,Nb、Cr和V等是延伸率的重要影响元素,C含量主要影响材料的冲击功等. ...
... [
78 ]
Identification of tree structure (a) and regression models (b) via interpretable machine learning (<i>X<sub>i</sub></i>—the material parameter, GGG—gadolinium gallium garnet (Gd<sub>3</sub>Ga<sub>5</sub>O<sub>12</sub>) crystals, <i>S</i><sub>STE</sub>—the spin-driven thermopower)<sup>[<xref ref-type="bibr" rid="R78">78</xref>]</sup> Fig.4 ![]()
图5 高熵合金固溶强化模型精度(MRE)的对比<sup>[<xref ref-type="bibr" rid="R80">80</xref>]</sup> (a) the new model (b) S-model (c) T-model (d) V-model ...
... [
78 ]
Fig.4 ![]()
图5 高熵合金固溶强化模型精度(MRE)的对比<sup>[<xref ref-type="bibr" rid="R80">80</xref>]</sup> (a) the new model (b) S-model (c) T-model (d) V-model ...
Uncovering the eutectics design by machine learning in the Al-Co-Cr-Fe-Ni high entropy system
1
2020
... 在机器学习预测模型的基础上,建立“白箱模型”或进行统计和可视化分析,可以辅助分析和理解目标量的主要影响因素.Raccuglia等[77 ] 基于3955条模板亚硒酸钒杂化材料合成反应实验数据,以元素原子性质构建反应物的材料因子,以反应温度、反应时间、溶液pH值等为材料参数,训练支持向量机模型对能否成功合成杂化材料进行预测,准确率达89%,超过经验化学家78%的预测准确率.他们利用支持向量机模型的预测数据训练决策树模型,建立了可解释的if-then准则,分析了反应物和反应条件的阈值,得到了合成该类杂化材料新工艺,指导反应物及合成条件的选择和设计.Iwasaki等[78 ] 使用因子分解渐近Bayesian推理分层专家混合(FAB/HME)的可解释机器学习方法指导新型热电材料开发,通过分段稀疏化线性建模,兼顾模型泛化能力和可解释性,如图4 [78 ] 所示,从机器学习模型训练到决策树,将搜索空间分为4类,对每类空间进行回归建模,发现自旋轨道相互作用较大的原子具有局域自旋极化,能够增强反常能斯特(Nernst)效应,利用这一发现指导自旋驱动的热电材料研发,制备出了Sebek系数(S )达13.04 μV/K的Co48.9 Pt51.1 N7.2 热电材料.Wu等[79 ] 基于321个“近共晶”(亚共晶,过共晶)高熵合金数据,建立了成分和共晶偏离度的人工神经网络模型,通过对400个预测数据的元素分布规律统计和可视化分析,发现Al和Cr狭窄分布的现象,说明2种元素在共晶高熵合金形成过程中存在协同效应,提出了共晶高熵合金新设计原则,基于该原则设计的共晶高熵合金抗拉强度达到约1300 MPa,延伸率约20%.Wen等[80 ] 利用领域知识构建了高熵合金固溶强化的材料因子,利用多种机器学习算法对材料因子和高熵合金传统固溶强化模型(S-模型、T-模型、V-模型)的关键参量进行筛选,发现原子电负性差是高熵合金固溶强化的控制参量,建立了基于电负性差的高熵合金固溶强化数学表达式,模型精度相对于传统模型有所提升且简洁易用,如图5 [80 ] 所示.Si等[81 ] 利用多个机器学习模型对14个材料特征进行筛选,发现原子半径差、价电子浓度、电负性差、经验参数Λ 、经验参数Ω 和剪切模量错配度等是决定Zr-Ti-Nb-O固溶体强度的关键特征,通过添加氧和金属原子间电负性差的参量,提升了传统屈服强度公式精度,同时发现价电子浓度、经验参数Λ 、剪切模量错配度和局域模量错配度是合金塑性的主要影响因素,通过可视化断裂应变与关键特征,提出了高塑性固溶体的设计准则.Xie等[82 ] 基于11101个数据样本,利用热轧钢板成分和生产工艺等27个材料参数为输入,建立深度神经网络模型预测热轧钢板屈服强度、抗拉强度、延伸率和冲击功等力学性能,均方根相对误差分别为4.7%、2.9%、7.7%和16.2%,基于预测模型,采用局部可解释算法(LIME)对深度神经网络模型进行了解释和知识提取,分析表明均匀化后的最后冷却温度是屈服强度和抗拉强度最重要的影响参量,Nb、Cr和V等是延伸率的重要影响元素,C含量主要影响材料的冲击功等. ...
Modeling solid solution strengthening in high entropy alloys using machine learning
4
2021
... 在机器学习预测模型的基础上,建立“白箱模型”或进行统计和可视化分析,可以辅助分析和理解目标量的主要影响因素.Raccuglia等[77 ] 基于3955条模板亚硒酸钒杂化材料合成反应实验数据,以元素原子性质构建反应物的材料因子,以反应温度、反应时间、溶液pH值等为材料参数,训练支持向量机模型对能否成功合成杂化材料进行预测,准确率达89%,超过经验化学家78%的预测准确率.他们利用支持向量机模型的预测数据训练决策树模型,建立了可解释的if-then准则,分析了反应物和反应条件的阈值,得到了合成该类杂化材料新工艺,指导反应物及合成条件的选择和设计.Iwasaki等[78 ] 使用因子分解渐近Bayesian推理分层专家混合(FAB/HME)的可解释机器学习方法指导新型热电材料开发,通过分段稀疏化线性建模,兼顾模型泛化能力和可解释性,如图4 [78 ] 所示,从机器学习模型训练到决策树,将搜索空间分为4类,对每类空间进行回归建模,发现自旋轨道相互作用较大的原子具有局域自旋极化,能够增强反常能斯特(Nernst)效应,利用这一发现指导自旋驱动的热电材料研发,制备出了Sebek系数(S )达13.04 μV/K的Co48.9 Pt51.1 N7.2 热电材料.Wu等[79 ] 基于321个“近共晶”(亚共晶,过共晶)高熵合金数据,建立了成分和共晶偏离度的人工神经网络模型,通过对400个预测数据的元素分布规律统计和可视化分析,发现Al和Cr狭窄分布的现象,说明2种元素在共晶高熵合金形成过程中存在协同效应,提出了共晶高熵合金新设计原则,基于该原则设计的共晶高熵合金抗拉强度达到约1300 MPa,延伸率约20%.Wen等[80 ] 利用领域知识构建了高熵合金固溶强化的材料因子,利用多种机器学习算法对材料因子和高熵合金传统固溶强化模型(S-模型、T-模型、V-模型)的关键参量进行筛选,发现原子电负性差是高熵合金固溶强化的控制参量,建立了基于电负性差的高熵合金固溶强化数学表达式,模型精度相对于传统模型有所提升且简洁易用,如图5 [80 ] 所示.Si等[81 ] 利用多个机器学习模型对14个材料特征进行筛选,发现原子半径差、价电子浓度、电负性差、经验参数Λ 、经验参数Ω 和剪切模量错配度等是决定Zr-Ti-Nb-O固溶体强度的关键特征,通过添加氧和金属原子间电负性差的参量,提升了传统屈服强度公式精度,同时发现价电子浓度、经验参数Λ 、剪切模量错配度和局域模量错配度是合金塑性的主要影响因素,通过可视化断裂应变与关键特征,提出了高塑性固溶体的设计准则.Xie等[82 ] 基于11101个数据样本,利用热轧钢板成分和生产工艺等27个材料参数为输入,建立深度神经网络模型预测热轧钢板屈服强度、抗拉强度、延伸率和冲击功等力学性能,均方根相对误差分别为4.7%、2.9%、7.7%和16.2%,基于预测模型,采用局部可解释算法(LIME)对深度神经网络模型进行了解释和知识提取,分析表明均匀化后的最后冷却温度是屈服强度和抗拉强度最重要的影响参量,Nb、Cr和V等是延伸率的重要影响元素,C含量主要影响材料的冲击功等. ...
... [80 ]所示.Si等[81 ] 利用多个机器学习模型对14个材料特征进行筛选,发现原子半径差、价电子浓度、电负性差、经验参数Λ 、经验参数Ω 和剪切模量错配度等是决定Zr-Ti-Nb-O固溶体强度的关键特征,通过添加氧和金属原子间电负性差的参量,提升了传统屈服强度公式精度,同时发现价电子浓度、经验参数Λ 、剪切模量错配度和局域模量错配度是合金塑性的主要影响因素,通过可视化断裂应变与关键特征,提出了高塑性固溶体的设计准则.Xie等[82 ] 基于11101个数据样本,利用热轧钢板成分和生产工艺等27个材料参数为输入,建立深度神经网络模型预测热轧钢板屈服强度、抗拉强度、延伸率和冲击功等力学性能,均方根相对误差分别为4.7%、2.9%、7.7%和16.2%,基于预测模型,采用局部可解释算法(LIME)对深度神经网络模型进行了解释和知识提取,分析表明均匀化后的最后冷却温度是屈服强度和抗拉强度最重要的影响参量,Nb、Cr和V等是延伸率的重要影响元素,C含量主要影响材料的冲击功等. ...
... [
80 ]
(a) the new model (b) S-model (c) T-model (d) V-model ...
... (e) comparison of predicted and experimental solid solution strength (
Δ σ SSS ) (f) the revised model
The Solid solution strengthening prediction via different physical models (MRE—the mean relative error, <i>R</i>—correlation coefficient, DFT—density functional theory)<sup>[<xref ref-type="bibr" rid="R80">80</xref>]</sup> Fig.5 ![]()
符号回归是利用优化算法,将数学运算符(如:+、-、*、/、sin、cos、log等)和材料特征等进行数学组合,回归目标量和材料特征(输入)之间的数学表达式,从而建立材料构效关系(QSAR)的显性表达式.Weng等[15 ] 对d轨道电子数、容忍因子t 、八面体因子μ 、以及A 、B 、X 位点的氧化价态、离子半径、电负性等参量进行符号回归,通过平衡数学公式的准确性和简单性,建立了钙钛矿结构催化材料析氧反应活性可逆氢电极过电位的数学关系式,提出了A 位点选用大离子半径阳离子,B 位点选用小离子半径阳离子的高效钙钛矿结构催化材料的优选方案,指导合成了5种新型钙钛矿结构催化材料,其中4种材料的催化活性优于已有材料.Loftis等[83 ] 基于347种钙钛矿结构、立方结构、六方ZnS结构等化合物导热系数的计算数据样本,利用符号回归建立了晶格导热系数的数学表达式,均方根误差达到5.296,远小于Slack模型的误差(19.451).Yuan等[84 ] 使用LASSO模型和符号回归方法,基于82种典型介电材料电击穿数据样本,对带隙、声子截止频率、晶体密度、介电常数、原子最近邻距离、Young's模量等参量进行符号回归,通过帕累托(Pareto)前沿面平衡数学公式的复杂度和误差,回归出了以带隙和声子截止频率为变量的介电材料电击穿强度数学表达式,预测结果与第一性原理计算结果的Pearson相关系数为0.74.魏清华等[85 ] 基于360条钢的数据样本,以疲劳强度、拉伸强度、断裂强度和硬度等为目标量,利用Multi-Task-Lasso特征筛选算法从17个材料参数中筛选出成分、制备工艺与夹杂物尺寸等同时满足4种力学性能预测的特征,利用符号回归建立了4种力学性能的数学表达式,分析发现增加Cr、Mo、Ni、Mn元素含量,以及降低回火温度、减少不连续夹杂物、提高淬火温度等有利于同时提升钢的4种力学性能. ...
Study on strengthening effects of Zr-Ti-Nb-O alloys via high throughput powder metallurgy and data-driven machine learning
1
2021
... 在机器学习预测模型的基础上,建立“白箱模型”或进行统计和可视化分析,可以辅助分析和理解目标量的主要影响因素.Raccuglia等[77 ] 基于3955条模板亚硒酸钒杂化材料合成反应实验数据,以元素原子性质构建反应物的材料因子,以反应温度、反应时间、溶液pH值等为材料参数,训练支持向量机模型对能否成功合成杂化材料进行预测,准确率达89%,超过经验化学家78%的预测准确率.他们利用支持向量机模型的预测数据训练决策树模型,建立了可解释的if-then准则,分析了反应物和反应条件的阈值,得到了合成该类杂化材料新工艺,指导反应物及合成条件的选择和设计.Iwasaki等[78 ] 使用因子分解渐近Bayesian推理分层专家混合(FAB/HME)的可解释机器学习方法指导新型热电材料开发,通过分段稀疏化线性建模,兼顾模型泛化能力和可解释性,如图4 [78 ] 所示,从机器学习模型训练到决策树,将搜索空间分为4类,对每类空间进行回归建模,发现自旋轨道相互作用较大的原子具有局域自旋极化,能够增强反常能斯特(Nernst)效应,利用这一发现指导自旋驱动的热电材料研发,制备出了Sebek系数(S )达13.04 μV/K的Co48.9 Pt51.1 N7.2 热电材料.Wu等[79 ] 基于321个“近共晶”(亚共晶,过共晶)高熵合金数据,建立了成分和共晶偏离度的人工神经网络模型,通过对400个预测数据的元素分布规律统计和可视化分析,发现Al和Cr狭窄分布的现象,说明2种元素在共晶高熵合金形成过程中存在协同效应,提出了共晶高熵合金新设计原则,基于该原则设计的共晶高熵合金抗拉强度达到约1300 MPa,延伸率约20%.Wen等[80 ] 利用领域知识构建了高熵合金固溶强化的材料因子,利用多种机器学习算法对材料因子和高熵合金传统固溶强化模型(S-模型、T-模型、V-模型)的关键参量进行筛选,发现原子电负性差是高熵合金固溶强化的控制参量,建立了基于电负性差的高熵合金固溶强化数学表达式,模型精度相对于传统模型有所提升且简洁易用,如图5 [80 ] 所示.Si等[81 ] 利用多个机器学习模型对14个材料特征进行筛选,发现原子半径差、价电子浓度、电负性差、经验参数Λ 、经验参数Ω 和剪切模量错配度等是决定Zr-Ti-Nb-O固溶体强度的关键特征,通过添加氧和金属原子间电负性差的参量,提升了传统屈服强度公式精度,同时发现价电子浓度、经验参数Λ 、剪切模量错配度和局域模量错配度是合金塑性的主要影响因素,通过可视化断裂应变与关键特征,提出了高塑性固溶体的设计准则.Xie等[82 ] 基于11101个数据样本,利用热轧钢板成分和生产工艺等27个材料参数为输入,建立深度神经网络模型预测热轧钢板屈服强度、抗拉强度、延伸率和冲击功等力学性能,均方根相对误差分别为4.7%、2.9%、7.7%和16.2%,基于预测模型,采用局部可解释算法(LIME)对深度神经网络模型进行了解释和知识提取,分析表明均匀化后的最后冷却温度是屈服强度和抗拉强度最重要的影响参量,Nb、Cr和V等是延伸率的重要影响元素,C含量主要影响材料的冲击功等. ...
Online prediction of mechanical properties of hot rolled steel plate using machine learning
1
2021
... 在机器学习预测模型的基础上,建立“白箱模型”或进行统计和可视化分析,可以辅助分析和理解目标量的主要影响因素.Raccuglia等[77 ] 基于3955条模板亚硒酸钒杂化材料合成反应实验数据,以元素原子性质构建反应物的材料因子,以反应温度、反应时间、溶液pH值等为材料参数,训练支持向量机模型对能否成功合成杂化材料进行预测,准确率达89%,超过经验化学家78%的预测准确率.他们利用支持向量机模型的预测数据训练决策树模型,建立了可解释的if-then准则,分析了反应物和反应条件的阈值,得到了合成该类杂化材料新工艺,指导反应物及合成条件的选择和设计.Iwasaki等[78 ] 使用因子分解渐近Bayesian推理分层专家混合(FAB/HME)的可解释机器学习方法指导新型热电材料开发,通过分段稀疏化线性建模,兼顾模型泛化能力和可解释性,如图4 [78 ] 所示,从机器学习模型训练到决策树,将搜索空间分为4类,对每类空间进行回归建模,发现自旋轨道相互作用较大的原子具有局域自旋极化,能够增强反常能斯特(Nernst)效应,利用这一发现指导自旋驱动的热电材料研发,制备出了Sebek系数(S )达13.04 μV/K的Co48.9 Pt51.1 N7.2 热电材料.Wu等[79 ] 基于321个“近共晶”(亚共晶,过共晶)高熵合金数据,建立了成分和共晶偏离度的人工神经网络模型,通过对400个预测数据的元素分布规律统计和可视化分析,发现Al和Cr狭窄分布的现象,说明2种元素在共晶高熵合金形成过程中存在协同效应,提出了共晶高熵合金新设计原则,基于该原则设计的共晶高熵合金抗拉强度达到约1300 MPa,延伸率约20%.Wen等[80 ] 利用领域知识构建了高熵合金固溶强化的材料因子,利用多种机器学习算法对材料因子和高熵合金传统固溶强化模型(S-模型、T-模型、V-模型)的关键参量进行筛选,发现原子电负性差是高熵合金固溶强化的控制参量,建立了基于电负性差的高熵合金固溶强化数学表达式,模型精度相对于传统模型有所提升且简洁易用,如图5 [80 ] 所示.Si等[81 ] 利用多个机器学习模型对14个材料特征进行筛选,发现原子半径差、价电子浓度、电负性差、经验参数Λ 、经验参数Ω 和剪切模量错配度等是决定Zr-Ti-Nb-O固溶体强度的关键特征,通过添加氧和金属原子间电负性差的参量,提升了传统屈服强度公式精度,同时发现价电子浓度、经验参数Λ 、剪切模量错配度和局域模量错配度是合金塑性的主要影响因素,通过可视化断裂应变与关键特征,提出了高塑性固溶体的设计准则.Xie等[82 ] 基于11101个数据样本,利用热轧钢板成分和生产工艺等27个材料参数为输入,建立深度神经网络模型预测热轧钢板屈服强度、抗拉强度、延伸率和冲击功等力学性能,均方根相对误差分别为4.7%、2.9%、7.7%和16.2%,基于预测模型,采用局部可解释算法(LIME)对深度神经网络模型进行了解释和知识提取,分析表明均匀化后的最后冷却温度是屈服强度和抗拉强度最重要的影响参量,Nb、Cr和V等是延伸率的重要影响元素,C含量主要影响材料的冲击功等. ...
Lattice thermal conductivity prediction using symbolic regression and machine learning
1
2021
... 符号回归是利用优化算法,将数学运算符(如:+、-、*、/、sin、cos、log等)和材料特征等进行数学组合,回归目标量和材料特征(输入)之间的数学表达式,从而建立材料构效关系(QSAR)的显性表达式.Weng等[15 ] 对d轨道电子数、容忍因子t 、八面体因子μ 、以及A 、B 、X 位点的氧化价态、离子半径、电负性等参量进行符号回归,通过平衡数学公式的准确性和简单性,建立了钙钛矿结构催化材料析氧反应活性可逆氢电极过电位的数学关系式,提出了A 位点选用大离子半径阳离子,B 位点选用小离子半径阳离子的高效钙钛矿结构催化材料的优选方案,指导合成了5种新型钙钛矿结构催化材料,其中4种材料的催化活性优于已有材料.Loftis等[83 ] 基于347种钙钛矿结构、立方结构、六方ZnS结构等化合物导热系数的计算数据样本,利用符号回归建立了晶格导热系数的数学表达式,均方根误差达到5.296,远小于Slack模型的误差(19.451).Yuan等[84 ] 使用LASSO模型和符号回归方法,基于82种典型介电材料电击穿数据样本,对带隙、声子截止频率、晶体密度、介电常数、原子最近邻距离、Young's模量等参量进行符号回归,通过帕累托(Pareto)前沿面平衡数学公式的复杂度和误差,回归出了以带隙和声子截止频率为变量的介电材料电击穿强度数学表达式,预测结果与第一性原理计算结果的Pearson相关系数为0.74.魏清华等[85 ] 基于360条钢的数据样本,以疲劳强度、拉伸强度、断裂强度和硬度等为目标量,利用Multi-Task-Lasso特征筛选算法从17个材料参数中筛选出成分、制备工艺与夹杂物尺寸等同时满足4种力学性能预测的特征,利用符号回归建立了4种力学性能的数学表达式,分析发现增加Cr、Mo、Ni、Mn元素含量,以及降低回火温度、减少不连续夹杂物、提高淬火温度等有利于同时提升钢的4种力学性能. ...
Identifying models of dielectric breakdown strength from high-throughput data via genetic programming
1
2017
... 符号回归是利用优化算法,将数学运算符(如:+、-、*、/、sin、cos、log等)和材料特征等进行数学组合,回归目标量和材料特征(输入)之间的数学表达式,从而建立材料构效关系(QSAR)的显性表达式.Weng等[15 ] 对d轨道电子数、容忍因子t 、八面体因子μ 、以及A 、B 、X 位点的氧化价态、离子半径、电负性等参量进行符号回归,通过平衡数学公式的准确性和简单性,建立了钙钛矿结构催化材料析氧反应活性可逆氢电极过电位的数学关系式,提出了A 位点选用大离子半径阳离子,B 位点选用小离子半径阳离子的高效钙钛矿结构催化材料的优选方案,指导合成了5种新型钙钛矿结构催化材料,其中4种材料的催化活性优于已有材料.Loftis等[83 ] 基于347种钙钛矿结构、立方结构、六方ZnS结构等化合物导热系数的计算数据样本,利用符号回归建立了晶格导热系数的数学表达式,均方根误差达到5.296,远小于Slack模型的误差(19.451).Yuan等[84 ] 使用LASSO模型和符号回归方法,基于82种典型介电材料电击穿数据样本,对带隙、声子截止频率、晶体密度、介电常数、原子最近邻距离、Young's模量等参量进行符号回归,通过帕累托(Pareto)前沿面平衡数学公式的复杂度和误差,回归出了以带隙和声子截止频率为变量的介电材料电击穿强度数学表达式,预测结果与第一性原理计算结果的Pearson相关系数为0.74.魏清华等[85 ] 基于360条钢的数据样本,以疲劳强度、拉伸强度、断裂强度和硬度等为目标量,利用Multi-Task-Lasso特征筛选算法从17个材料参数中筛选出成分、制备工艺与夹杂物尺寸等同时满足4种力学性能预测的特征,利用符号回归建立了4种力学性能的数学表达式,分析发现增加Cr、Mo、Ni、Mn元素含量,以及降低回火温度、减少不连续夹杂物、提高淬火温度等有利于同时提升钢的4种力学性能. ...
多目标机器学习钢的四种力学性能
1
2021
... 符号回归是利用优化算法,将数学运算符(如:+、-、*、/、sin、cos、log等)和材料特征等进行数学组合,回归目标量和材料特征(输入)之间的数学表达式,从而建立材料构效关系(QSAR)的显性表达式.Weng等[15 ] 对d轨道电子数、容忍因子t 、八面体因子μ 、以及A 、B 、X 位点的氧化价态、离子半径、电负性等参量进行符号回归,通过平衡数学公式的准确性和简单性,建立了钙钛矿结构催化材料析氧反应活性可逆氢电极过电位的数学关系式,提出了A 位点选用大离子半径阳离子,B 位点选用小离子半径阳离子的高效钙钛矿结构催化材料的优选方案,指导合成了5种新型钙钛矿结构催化材料,其中4种材料的催化活性优于已有材料.Loftis等[83 ] 基于347种钙钛矿结构、立方结构、六方ZnS结构等化合物导热系数的计算数据样本,利用符号回归建立了晶格导热系数的数学表达式,均方根误差达到5.296,远小于Slack模型的误差(19.451).Yuan等[84 ] 使用LASSO模型和符号回归方法,基于82种典型介电材料电击穿数据样本,对带隙、声子截止频率、晶体密度、介电常数、原子最近邻距离、Young's模量等参量进行符号回归,通过帕累托(Pareto)前沿面平衡数学公式的复杂度和误差,回归出了以带隙和声子截止频率为变量的介电材料电击穿强度数学表达式,预测结果与第一性原理计算结果的Pearson相关系数为0.74.魏清华等[85 ] 基于360条钢的数据样本,以疲劳强度、拉伸强度、断裂强度和硬度等为目标量,利用Multi-Task-Lasso特征筛选算法从17个材料参数中筛选出成分、制备工艺与夹杂物尺寸等同时满足4种力学性能预测的特征,利用符号回归建立了4种力学性能的数学表达式,分析发现增加Cr、Mo、Ni、Mn元素含量,以及降低回火温度、减少不连续夹杂物、提高淬火温度等有利于同时提升钢的4种力学性能. ...
多目标机器学习钢的四种力学性能
1
2021
... 符号回归是利用优化算法,将数学运算符(如:+、-、*、/、sin、cos、log等)和材料特征等进行数学组合,回归目标量和材料特征(输入)之间的数学表达式,从而建立材料构效关系(QSAR)的显性表达式.Weng等[15 ] 对d轨道电子数、容忍因子t 、八面体因子μ 、以及A 、B 、X 位点的氧化价态、离子半径、电负性等参量进行符号回归,通过平衡数学公式的准确性和简单性,建立了钙钛矿结构催化材料析氧反应活性可逆氢电极过电位的数学关系式,提出了A 位点选用大离子半径阳离子,B 位点选用小离子半径阳离子的高效钙钛矿结构催化材料的优选方案,指导合成了5种新型钙钛矿结构催化材料,其中4种材料的催化活性优于已有材料.Loftis等[83 ] 基于347种钙钛矿结构、立方结构、六方ZnS结构等化合物导热系数的计算数据样本,利用符号回归建立了晶格导热系数的数学表达式,均方根误差达到5.296,远小于Slack模型的误差(19.451).Yuan等[84 ] 使用LASSO模型和符号回归方法,基于82种典型介电材料电击穿数据样本,对带隙、声子截止频率、晶体密度、介电常数、原子最近邻距离、Young's模量等参量进行符号回归,通过帕累托(Pareto)前沿面平衡数学公式的复杂度和误差,回归出了以带隙和声子截止频率为变量的介电材料电击穿强度数学表达式,预测结果与第一性原理计算结果的Pearson相关系数为0.74.魏清华等[85 ] 基于360条钢的数据样本,以疲劳强度、拉伸强度、断裂强度和硬度等为目标量,利用Multi-Task-Lasso特征筛选算法从17个材料参数中筛选出成分、制备工艺与夹杂物尺寸等同时满足4种力学性能预测的特征,利用符号回归建立了4种力学性能的数学表达式,分析发现增加Cr、Mo、Ni、Mn元素含量,以及降低回火温度、减少不连续夹杂物、提高淬火温度等有利于同时提升钢的4种力学性能. ...
Efficient global optimization of expensive black-box functions
1
1998
... 主动学习是在构建机器学习预测模型的基础上,通过模型的不确定性分析,建立平衡材料性能预测值与模型不确定性的效能方程(如期望提升(EI)[86 ] 、期望提升的可能性(PI)[87 ] 、上置信边界(UCB)[88 ] 等),预测具有最大收益的数据点进行实验验证,将验证数据反馈到机器学习模型,提升模型预测最优值的精度,如此反馈迭代,以最少的实验预测筛选出具有最优目标性能的材料. ...
A statistical learning framework for materials science: application to elastic moduli of k -nary inorganic polycrystalline compounds
1
2016
... 主动学习是在构建机器学习预测模型的基础上,通过模型的不确定性分析,建立平衡材料性能预测值与模型不确定性的效能方程(如期望提升(EI)[86 ] 、期望提升的可能性(PI)[87 ] 、上置信边界(UCB)[88 ] 等),预测具有最大收益的数据点进行实验验证,将验证数据反馈到机器学习模型,提升模型预测最优值的精度,如此反馈迭代,以最少的实验预测筛选出具有最优目标性能的材料. ...
A tutorial on Bayesian optimization
1
1807
... 主动学习是在构建机器学习预测模型的基础上,通过模型的不确定性分析,建立平衡材料性能预测值与模型不确定性的效能方程(如期望提升(EI)[86 ] 、期望提升的可能性(PI)[87 ] 、上置信边界(UCB)[88 ] 等),预测具有最大收益的数据点进行实验验证,将验证数据反馈到机器学习模型,提升模型预测最优值的精度,如此反馈迭代,以最少的实验预测筛选出具有最优目标性能的材料. ...
Accelerated search for materials with targeted properties by adaptive design
2
2016
... Xue等[89 ] 首先将主动学习策略用于具有最小相变热滞后的Ti-Ni基形状记忆合金的优化设计,基于22个实验数据,利用价电子浓度、电负性等材料因子为输入,建立相变热滞后的支持向量机模型,通过自助法获得预测结果的均值及其不确定性,选择期望提升值最大的合金成分进行实验验证,将验证值反馈到机器学习模型进行再次预测和实验验证,经过6次反馈迭代,在80万种候选材料成分中成功研发出了相变热滞后值(1.84 K)低于原始数据集的新型TiNiCuFePd形状记忆合金.Wen等[90 ] 强调了主动学习结合领域知识的材料设计策略,比较了仅用材料成分和成分结合材料因子建立预测模型的效率,发现增加领域知识可以有效地提高主动学习的效率,在200万种候选成分中快速优化出高硬度的高熵合金.Li等[91 ] 基于73个铝合金成分和抗拉强度的数据样本,建立克里金(Kriging)差值模型,通过计算模型的期望提升设计实验,经过4次实验迭代,筛选出了Zn含量(质量分数)小于7%的高强度铝合金成分,经传统时效处理后强度达950 MPa、延伸率为6%.Liu等[92 ] 采用主动学习优化Mg-Al-Sn-Zn-Ca-Mn合金的硬度,建立了以成分、时效温度、时效时间等为特征的XGBoost机器学习模型,仅用2次实验迭代就得到了超过初始数据集硬度最高值的合金成分和工艺.赵婉辰等[93 ] 利用主动学习指导实验,有效提高了机器学习模型的预测能力,获得了6061铝合金更优的工艺窗口. ...
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Machine learning assisted design of high entropy alloys with desired property
1
2019
... Xue等[89 ] 首先将主动学习策略用于具有最小相变热滞后的Ti-Ni基形状记忆合金的优化设计,基于22个实验数据,利用价电子浓度、电负性等材料因子为输入,建立相变热滞后的支持向量机模型,通过自助法获得预测结果的均值及其不确定性,选择期望提升值最大的合金成分进行实验验证,将验证值反馈到机器学习模型进行再次预测和实验验证,经过6次反馈迭代,在80万种候选材料成分中成功研发出了相变热滞后值(1.84 K)低于原始数据集的新型TiNiCuFePd形状记忆合金.Wen等[90 ] 强调了主动学习结合领域知识的材料设计策略,比较了仅用材料成分和成分结合材料因子建立预测模型的效率,发现增加领域知识可以有效地提高主动学习的效率,在200万种候选成分中快速优化出高硬度的高熵合金.Li等[91 ] 基于73个铝合金成分和抗拉强度的数据样本,建立克里金(Kriging)差值模型,通过计算模型的期望提升设计实验,经过4次实验迭代,筛选出了Zn含量(质量分数)小于7%的高强度铝合金成分,经传统时效处理后强度达950 MPa、延伸率为6%.Liu等[92 ] 采用主动学习优化Mg-Al-Sn-Zn-Ca-Mn合金的硬度,建立了以成分、时效温度、时效时间等为特征的XGBoost机器学习模型,仅用2次实验迭代就得到了超过初始数据集硬度最高值的合金成分和工艺.赵婉辰等[93 ] 利用主动学习指导实验,有效提高了机器学习模型的预测能力,获得了6061铝合金更优的工艺窗口. ...
Accelerated discovery of high-strength aluminum alloys by machine learning
1
2020
... Xue等[89 ] 首先将主动学习策略用于具有最小相变热滞后的Ti-Ni基形状记忆合金的优化设计,基于22个实验数据,利用价电子浓度、电负性等材料因子为输入,建立相变热滞后的支持向量机模型,通过自助法获得预测结果的均值及其不确定性,选择期望提升值最大的合金成分进行实验验证,将验证值反馈到机器学习模型进行再次预测和实验验证,经过6次反馈迭代,在80万种候选材料成分中成功研发出了相变热滞后值(1.84 K)低于原始数据集的新型TiNiCuFePd形状记忆合金.Wen等[90 ] 强调了主动学习结合领域知识的材料设计策略,比较了仅用材料成分和成分结合材料因子建立预测模型的效率,发现增加领域知识可以有效地提高主动学习的效率,在200万种候选成分中快速优化出高硬度的高熵合金.Li等[91 ] 基于73个铝合金成分和抗拉强度的数据样本,建立克里金(Kriging)差值模型,通过计算模型的期望提升设计实验,经过4次实验迭代,筛选出了Zn含量(质量分数)小于7%的高强度铝合金成分,经传统时效处理后强度达950 MPa、延伸率为6%.Liu等[92 ] 采用主动学习优化Mg-Al-Sn-Zn-Ca-Mn合金的硬度,建立了以成分、时效温度、时效时间等为特征的XGBoost机器学习模型,仅用2次实验迭代就得到了超过初始数据集硬度最高值的合金成分和工艺.赵婉辰等[93 ] 利用主动学习指导实验,有效提高了机器学习模型的预测能力,获得了6061铝合金更优的工艺窗口. ...
Accelerated development of high-strength magnesium alloys by machine learning
1
2021
... Xue等[89 ] 首先将主动学习策略用于具有最小相变热滞后的Ti-Ni基形状记忆合金的优化设计,基于22个实验数据,利用价电子浓度、电负性等材料因子为输入,建立相变热滞后的支持向量机模型,通过自助法获得预测结果的均值及其不确定性,选择期望提升值最大的合金成分进行实验验证,将验证值反馈到机器学习模型进行再次预测和实验验证,经过6次反馈迭代,在80万种候选材料成分中成功研发出了相变热滞后值(1.84 K)低于原始数据集的新型TiNiCuFePd形状记忆合金.Wen等[90 ] 强调了主动学习结合领域知识的材料设计策略,比较了仅用材料成分和成分结合材料因子建立预测模型的效率,发现增加领域知识可以有效地提高主动学习的效率,在200万种候选成分中快速优化出高硬度的高熵合金.Li等[91 ] 基于73个铝合金成分和抗拉强度的数据样本,建立克里金(Kriging)差值模型,通过计算模型的期望提升设计实验,经过4次实验迭代,筛选出了Zn含量(质量分数)小于7%的高强度铝合金成分,经传统时效处理后强度达950 MPa、延伸率为6%.Liu等[92 ] 采用主动学习优化Mg-Al-Sn-Zn-Ca-Mn合金的硬度,建立了以成分、时效温度、时效时间等为特征的XGBoost机器学习模型,仅用2次实验迭代就得到了超过初始数据集硬度最高值的合金成分和工艺.赵婉辰等[93 ] 利用主动学习指导实验,有效提高了机器学习模型的预测能力,获得了6061铝合金更优的工艺窗口. ...
基于Bayesian采样主动机器学习模型的6061铝合金成分精细优化
1
2021
... Xue等[89 ] 首先将主动学习策略用于具有最小相变热滞后的Ti-Ni基形状记忆合金的优化设计,基于22个实验数据,利用价电子浓度、电负性等材料因子为输入,建立相变热滞后的支持向量机模型,通过自助法获得预测结果的均值及其不确定性,选择期望提升值最大的合金成分进行实验验证,将验证值反馈到机器学习模型进行再次预测和实验验证,经过6次反馈迭代,在80万种候选材料成分中成功研发出了相变热滞后值(1.84 K)低于原始数据集的新型TiNiCuFePd形状记忆合金.Wen等[90 ] 强调了主动学习结合领域知识的材料设计策略,比较了仅用材料成分和成分结合材料因子建立预测模型的效率,发现增加领域知识可以有效地提高主动学习的效率,在200万种候选成分中快速优化出高硬度的高熵合金.Li等[91 ] 基于73个铝合金成分和抗拉强度的数据样本,建立克里金(Kriging)差值模型,通过计算模型的期望提升设计实验,经过4次实验迭代,筛选出了Zn含量(质量分数)小于7%的高强度铝合金成分,经传统时效处理后强度达950 MPa、延伸率为6%.Liu等[92 ] 采用主动学习优化Mg-Al-Sn-Zn-Ca-Mn合金的硬度,建立了以成分、时效温度、时效时间等为特征的XGBoost机器学习模型,仅用2次实验迭代就得到了超过初始数据集硬度最高值的合金成分和工艺.赵婉辰等[93 ] 利用主动学习指导实验,有效提高了机器学习模型的预测能力,获得了6061铝合金更优的工艺窗口. ...
基于Bayesian采样主动机器学习模型的6061铝合金成分精细优化
1
2021
... Xue等[89 ] 首先将主动学习策略用于具有最小相变热滞后的Ti-Ni基形状记忆合金的优化设计,基于22个实验数据,利用价电子浓度、电负性等材料因子为输入,建立相变热滞后的支持向量机模型,通过自助法获得预测结果的均值及其不确定性,选择期望提升值最大的合金成分进行实验验证,将验证值反馈到机器学习模型进行再次预测和实验验证,经过6次反馈迭代,在80万种候选材料成分中成功研发出了相变热滞后值(1.84 K)低于原始数据集的新型TiNiCuFePd形状记忆合金.Wen等[90 ] 强调了主动学习结合领域知识的材料设计策略,比较了仅用材料成分和成分结合材料因子建立预测模型的效率,发现增加领域知识可以有效地提高主动学习的效率,在200万种候选成分中快速优化出高硬度的高熵合金.Li等[91 ] 基于73个铝合金成分和抗拉强度的数据样本,建立克里金(Kriging)差值模型,通过计算模型的期望提升设计实验,经过4次实验迭代,筛选出了Zn含量(质量分数)小于7%的高强度铝合金成分,经传统时效处理后强度达950 MPa、延伸率为6%.Liu等[92 ] 采用主动学习优化Mg-Al-Sn-Zn-Ca-Mn合金的硬度,建立了以成分、时效温度、时效时间等为特征的XGBoost机器学习模型,仅用2次实验迭代就得到了超过初始数据集硬度最高值的合金成分和工艺.赵婉辰等[93 ] 利用主动学习指导实验,有效提高了机器学习模型的预测能力,获得了6061铝合金更优的工艺窗口. ...
Accelerated search for BaTiO3 -based piezoelectrics with vertical morphotropic phase boundary using Bayesian learning
1
2016
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Accelerated discovery of large electrostrains in BaTiO3 -based piezoelectrics using active learnIng
0
2018
Accelerated search for BaTiO3 -based ceramics with large energy storage at low fields using machine learning and experimental design
1
2019
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
An active learning approach for the design of doped LLZO ceramic garnets for battery applications
1
2021
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Mesoporous trimetallic PtPdAu alloy films toward enhanced electrocatalytic activity in methanol oxidation: Unexpected chemical compositions discovered by Bayesian optimization
1
2020
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Beyond ternary OPV: High-throughput experimentation and self-driving laboratories optimize multicomponent systems
1
2020
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Application of Bayesian optimization for improved passivation performance in TiOx y
1
2021
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Creating glasswing butterfly-inspired durable antifogging superomniphobic supertransmissive, superclear nanostructured glass through Bayesian learning and optimization
1
2019
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Closed-loop optimization of fast-charging protocols for batteries with machine learning
1
2020
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Accelerated knowledge discovery from omics data by optimal experimental design
1
2020
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Designing nanostructures for phonon transport via Bayesian optimization
1
2017
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Machine learning with systematic density-functional theory calculations: Application to melting temperatures of single- and binary-component solids
0
2014
Accelerating high-throughput searches for new alloys with active learning of interatomic potentials
1
2019
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
A mobile robotic chemist
2
2020
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
... 近年来,以实验和生产数据为基础的机器学习辅助材料设计在金属、陶瓷、高分子等结构和功能材料中得到较为广泛应用,以材料计算数据为基础的机器学习在能源材料、催化材料、拓扑材料等前沿材料领域取得了引人瞩目的进展[5 ] .机器学习与材料实验技术的融合,发展了材料自主实验技术[107 ,108 ,144 ~146 ] ,有效地提升了材料实验的效率和智能化水平.机器学习与材料第一性原理计算,以及相场和有限元模拟相结合,大幅度提升了材料计算设计和筛选的效率.限于篇幅,本文重点以实验和生产数据为基础,以在金属材料,特别是金属结构材料中的应用为案例,综述了机器学习在材料设计和优化中的研究进展. ...
A Bayesian experimental autonomous researcher for mechanical design
2
2020
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
... 近年来,以实验和生产数据为基础的机器学习辅助材料设计在金属、陶瓷、高分子等结构和功能材料中得到较为广泛应用,以材料计算数据为基础的机器学习在能源材料、催化材料、拓扑材料等前沿材料领域取得了引人瞩目的进展[5 ] .机器学习与材料实验技术的融合,发展了材料自主实验技术[107 ,108 ,144 ~146 ] ,有效地提升了材料实验的效率和智能化水平.机器学习与材料第一性原理计算,以及相场和有限元模拟相结合,大幅度提升了材料计算设计和筛选的效率.限于篇幅,本文重点以实验和生产数据为基础,以在金属材料,特别是金属结构材料中的应用为案例,综述了机器学习在材料设计和优化中的研究进展. ...
Efficient estimation of material property curves and surfaces via active learning
1
2021
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Determining multi-component phase diagrams with desired characteristics using active learning
1
2021
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Efficient construction method for phase diagrams using uncertainty sampling
1
2019
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Efficient phase diagram sampling by active learning
1
2020
... 主动学习策略还被较多地应用于压电材料和储能电介质[89 , 94 ~96 ] 、电池材料[97 ,98 ] 、光伏材料[99 ,100 ] 、纳米材料[101 ] 、生物材料[102 ,103 ] 等新材料的研发,以及相图构建、材料高效计算[104 ~106 ] 、材料自主实验[107 ,108 ] 等领域.以绘制相图为例,利用主动学习策略向训练集补充收益率更高的新数据样本,可以快速提升机器学习分类模型的准确性,有效减少了绘制相图所需的数据量.Tian等[109 ,110 ] 利用Kriging插值模型对未知相图的相边界进行预测时,通过预测相边界值及其不确定性,以最大方差为效能函数选择实验进行验证,反馈迭代减少相界预测的整体不确定性,仅通过3次实验就建立了具有较高转变温度和三相点的(1 - ω )(Ti0.309 Ni0.485 Hf0.20 Zr0.006 )-ω (Ti0.309 Ni0.485 Hf0.07 Zr0.068 Nb0.068 )材料相图.SiO2 -Al2 O3 -MgO体系存在10种相结构,Terayama等[111 ] 利用主动学习中的不确定性采样(US),选择当前基准分类器最不能确定其分类的样本进行标注,利用主动学习指导采样,建立相分类模型,绘制相图的采样数比随机采样策略减少了80%左右.Dai等[112 ] 将Bayesian优化中的局部惩罚技术推广到主动学习,提出了相图采样的主动学习策略,证明了通过异步采样设计思路选择采集函数比传统的网格搜索采样方法效率更高. ...
Materials informatics for the screening of multi-principal elements and high-entropy alloys
1
2019
... Rickman等[113 ] 基于82个高熵合金硬度数据样本,以混合焓、混合熵和价电子浓度等材料因子为输入建立多元回归模型,以多元回归模型为遗传算法的适应度函数,通过迭代进化,逐步优化目标性能,在由16个元素组成的1.7 × 108 种五元高熵合金候选成分空间中成功发现并实验制备了2种硬度超过1000 HV的高熵合金(Co33 W7 Al33 Nb24 Cr3 合金,硬度为(1084 ± 37) HV;Ti18 Ni24 Ta12 Cr22 Co24 合金,硬度为(1011 ± 20) HV).玻璃的组成成分(氧化物、氟化物、硅酸盐等)和配比的可选空间巨大,即使利用高通量实验也无法实现高性能玻璃的全局优化设计,Cassar等[114 ] 将人工神经网络与遗传算法相结合,研发出了半自动优化玻璃特定性能的成分配比选择方法,基于包含39种元素的45302个玻璃化转变温度数据样本,以及包含38种元素的41225个玻璃折射率数据集样本,建立了以成分为输入的玻璃化转变温度和折射率预测模型,利用遗传算法搜索具有特定性能的玻璃成分,成功研发出了高折射率(高于1.7)和低玻璃化转变温度(低于500℃)的玻璃.Reddy等[115 ] 基于140个钢的力学性能数据样本,以成分、冷却速率和温度等材料参数为输入,建立了屈服强度、极限抗拉强度、延伸率和冲击强度等的人工神经网络模型,以模型为遗传算法的适应度函数,优化了材料成分与工艺参数,有效地减少了新钢种设计的实验量.如图6 [116 ] 所示,Shen等[116 ] 将相体积分数和驱动力的物理冶金模型和材料成分、热处理参数等材料参数作为输入,将物理冶金知识融入机器学习,仅利用102个数据样本就得到了具有优异泛化能力的钢硬度支持向量机预测模型,测试集的决定系数为98.3%,平均绝对误差为0.75 HRC,结合遗传算法在原始参数范围内筛选出了R相析出强化高强度不锈钢(硬度达52.9 HRC)的成分和时效条件. ...
Designing optical glasses by machine learning coupled with a genetic algorithm
1
2021
... Rickman等[113 ] 基于82个高熵合金硬度数据样本,以混合焓、混合熵和价电子浓度等材料因子为输入建立多元回归模型,以多元回归模型为遗传算法的适应度函数,通过迭代进化,逐步优化目标性能,在由16个元素组成的1.7 × 108 种五元高熵合金候选成分空间中成功发现并实验制备了2种硬度超过1000 HV的高熵合金(Co33 W7 Al33 Nb24 Cr3 合金,硬度为(1084 ± 37) HV;Ti18 Ni24 Ta12 Cr22 Co24 合金,硬度为(1011 ± 20) HV).玻璃的组成成分(氧化物、氟化物、硅酸盐等)和配比的可选空间巨大,即使利用高通量实验也无法实现高性能玻璃的全局优化设计,Cassar等[114 ] 将人工神经网络与遗传算法相结合,研发出了半自动优化玻璃特定性能的成分配比选择方法,基于包含39种元素的45302个玻璃化转变温度数据样本,以及包含38种元素的41225个玻璃折射率数据集样本,建立了以成分为输入的玻璃化转变温度和折射率预测模型,利用遗传算法搜索具有特定性能的玻璃成分,成功研发出了高折射率(高于1.7)和低玻璃化转变温度(低于500℃)的玻璃.Reddy等[115 ] 基于140个钢的力学性能数据样本,以成分、冷却速率和温度等材料参数为输入,建立了屈服强度、极限抗拉强度、延伸率和冲击强度等的人工神经网络模型,以模型为遗传算法的适应度函数,优化了材料成分与工艺参数,有效地减少了新钢种设计的实验量.如图6 [116 ] 所示,Shen等[116 ] 将相体积分数和驱动力的物理冶金模型和材料成分、热处理参数等材料参数作为输入,将物理冶金知识融入机器学习,仅利用102个数据样本就得到了具有优异泛化能力的钢硬度支持向量机预测模型,测试集的决定系数为98.3%,平均绝对误差为0.75 HRC,结合遗传算法在原始参数范围内筛选出了R相析出强化高强度不锈钢(硬度达52.9 HRC)的成分和时效条件. ...
Design of medium carbon steels by computational intelligence techniques
1
2015
... Rickman等[113 ] 基于82个高熵合金硬度数据样本,以混合焓、混合熵和价电子浓度等材料因子为输入建立多元回归模型,以多元回归模型为遗传算法的适应度函数,通过迭代进化,逐步优化目标性能,在由16个元素组成的1.7 × 108 种五元高熵合金候选成分空间中成功发现并实验制备了2种硬度超过1000 HV的高熵合金(Co33 W7 Al33 Nb24 Cr3 合金,硬度为(1084 ± 37) HV;Ti18 Ni24 Ta12 Cr22 Co24 合金,硬度为(1011 ± 20) HV).玻璃的组成成分(氧化物、氟化物、硅酸盐等)和配比的可选空间巨大,即使利用高通量实验也无法实现高性能玻璃的全局优化设计,Cassar等[114 ] 将人工神经网络与遗传算法相结合,研发出了半自动优化玻璃特定性能的成分配比选择方法,基于包含39种元素的45302个玻璃化转变温度数据样本,以及包含38种元素的41225个玻璃折射率数据集样本,建立了以成分为输入的玻璃化转变温度和折射率预测模型,利用遗传算法搜索具有特定性能的玻璃成分,成功研发出了高折射率(高于1.7)和低玻璃化转变温度(低于500℃)的玻璃.Reddy等[115 ] 基于140个钢的力学性能数据样本,以成分、冷却速率和温度等材料参数为输入,建立了屈服强度、极限抗拉强度、延伸率和冲击强度等的人工神经网络模型,以模型为遗传算法的适应度函数,优化了材料成分与工艺参数,有效地减少了新钢种设计的实验量.如图6 [116 ] 所示,Shen等[116 ] 将相体积分数和驱动力的物理冶金模型和材料成分、热处理参数等材料参数作为输入,将物理冶金知识融入机器学习,仅利用102个数据样本就得到了具有优异泛化能力的钢硬度支持向量机预测模型,测试集的决定系数为98.3%,平均绝对误差为0.75 HRC,结合遗传算法在原始参数范围内筛选出了R相析出强化高强度不锈钢(硬度达52.9 HRC)的成分和时效条件. ...
Physical metallurgy-guided machine learning and artificial intelligent design of ultrahigh-strength stainless steel
4
2019
... Rickman等[113 ] 基于82个高熵合金硬度数据样本,以混合焓、混合熵和价电子浓度等材料因子为输入建立多元回归模型,以多元回归模型为遗传算法的适应度函数,通过迭代进化,逐步优化目标性能,在由16个元素组成的1.7 × 108 种五元高熵合金候选成分空间中成功发现并实验制备了2种硬度超过1000 HV的高熵合金(Co33 W7 Al33 Nb24 Cr3 合金,硬度为(1084 ± 37) HV;Ti18 Ni24 Ta12 Cr22 Co24 合金,硬度为(1011 ± 20) HV).玻璃的组成成分(氧化物、氟化物、硅酸盐等)和配比的可选空间巨大,即使利用高通量实验也无法实现高性能玻璃的全局优化设计,Cassar等[114 ] 将人工神经网络与遗传算法相结合,研发出了半自动优化玻璃特定性能的成分配比选择方法,基于包含39种元素的45302个玻璃化转变温度数据样本,以及包含38种元素的41225个玻璃折射率数据集样本,建立了以成分为输入的玻璃化转变温度和折射率预测模型,利用遗传算法搜索具有特定性能的玻璃成分,成功研发出了高折射率(高于1.7)和低玻璃化转变温度(低于500℃)的玻璃.Reddy等[115 ] 基于140个钢的力学性能数据样本,以成分、冷却速率和温度等材料参数为输入,建立了屈服强度、极限抗拉强度、延伸率和冲击强度等的人工神经网络模型,以模型为遗传算法的适应度函数,优化了材料成分与工艺参数,有效地减少了新钢种设计的实验量.如图6 [116 ] 所示,Shen等[116 ] 将相体积分数和驱动力的物理冶金模型和材料成分、热处理参数等材料参数作为输入,将物理冶金知识融入机器学习,仅利用102个数据样本就得到了具有优异泛化能力的钢硬度支持向量机预测模型,测试集的决定系数为98.3%,平均绝对误差为0.75 HRC,结合遗传算法在原始参数范围内筛选出了R相析出强化高强度不锈钢(硬度达52.9 HRC)的成分和时效条件. ...
... [116 ]将相体积分数和驱动力的物理冶金模型和材料成分、热处理参数等材料参数作为输入,将物理冶金知识融入机器学习,仅利用102个数据样本就得到了具有优异泛化能力的钢硬度支持向量机预测模型,测试集的决定系数为98.3%,平均绝对误差为0.75 HRC,结合遗传算法在原始参数范围内筛选出了R相析出强化高强度不锈钢(硬度达52.9 HRC)的成分和时效条件. ...
... [
116 ]
Strategy of combining machine learning and genetic algorithm to design ultrahigh-strength stainless steel (PM—physical metallurgy, MAE—mean absolute error, SVM—support vector machine, SVC—support vector classifier, GA—genetic algorithm, VF—equilibrium volume fraction, DF—driving force)<sup>[<xref ref-type="bibr" rid="R116">116</xref>]</sup> Fig.6 ![]()
<strong>4.2 </strong>多目标优化 综合性能是衡量材料能否满足工程应用的前提.但是,由于材料性能影响因素众多,性能间交互作用复杂,如材料的强度与塑性/韧性,强度与导电率等,往往相互冲突,呈此消彼长的矛盾关系.因此,设计研发平衡材料各类性能最优值、实现综合性能最优的材料,一直是材料领域的难题.本节综述了逐层筛选优化、多目标转单目标优化、Pareto前沿协同优化等优化策略在材料多目标优化设计方面的研究进展. ...
... [
116 ]
Fig.6 ![]()
<strong>4.2 </strong>多目标优化 综合性能是衡量材料能否满足工程应用的前提.但是,由于材料性能影响因素众多,性能间交互作用复杂,如材料的强度与塑性/韧性,强度与导电率等,往往相互冲突,呈此消彼长的矛盾关系.因此,设计研发平衡材料各类性能最优值、实现综合性能最优的材料,一直是材料领域的难题.本节综述了逐层筛选优化、多目标转单目标优化、Pareto前沿协同优化等优化策略在材料多目标优化设计方面的研究进展. ...
Machine learning assisted design of γ′ -strengthened Co-base superalloys with multi-performance optimization
4
2020
... 逐层筛选优化是利用专家领域知识或机器学习模型,以材料基本性能下限为过滤器,过滤出基本性能满足要求的材料筛选空间,再优化材料关键性能的策略.Liu等[117 ] 利用如图7 [117 ] 所示的逐层筛选策略,根据高温合金抗高温氧化性能和γ' 相体积分数(≥ 60%)的领域知识和经验,确定了CoAlWNiTiTaCr七元钴基高温合金中Al和Cr元素的成分范围,利用热力学计算和实验数据,以材料参数和合金因子为特征,分别建立了γ' 相组织稳定性的分类模型和固溶温度、固相线、液相线、密度等4个机器学习回归模型,对是否含有害相、热处理窗口、凝固区间,以及密度进行筛选,在此基础上利用有效全局优化策略对γ' 相溶解温度进行优化,通过3次实验迭代,成功研发出其他性能满足要求、承温能力达到1266℃的新型钴基高温合金.Yu等[118 ] 在363000余种可能的候选合金成分空间中,利用分类模型预测γ' 和有害相是否存在,利用回归模型预测γ' 固溶线温度和体积分数,通过逐层筛选,研发出了6种满足性能需求的钴基高温合金. ...
... [117 ]所示的逐层筛选策略,根据高温合金抗高温氧化性能和γ' 相体积分数(≥ 60%)的领域知识和经验,确定了CoAlWNiTiTaCr七元钴基高温合金中Al和Cr元素的成分范围,利用热力学计算和实验数据,以材料参数和合金因子为特征,分别建立了γ' 相组织稳定性的分类模型和固溶温度、固相线、液相线、密度等4个机器学习回归模型,对是否含有害相、热处理窗口、凝固区间,以及密度进行筛选,在此基础上利用有效全局优化策略对γ' 相溶解温度进行优化,通过3次实验迭代,成功研发出其他性能满足要求、承温能力达到1266℃的新型钴基高温合金.Yu等[118 ] 在363000余种可能的候选合金成分空间中,利用分类模型预测γ' 和有害相是否存在,利用回归模型预测γ' 固溶线温度和体积分数,通过逐层筛选,研发出了6种满足性能需求的钴基高温合金. ...
... [
117 ]
Sequential filter strategy for multi-objective optimization of Co-base superalloys<sup>[<xref ref-type="bibr" rid="R117">117</xref>]</sup> Fig.7 ![]()
4.2.2 多目标转单目标优化 通过应用场景分析确定材料所需的各项性能指标,将多目标性能进行加权线性组合转化为单目标,利用优化策略对单目标量进行优化设计,可以实现材料多个目标的优化,这种方法通常称为Ashby法[119 ] .功能材料的品质因子(figure of merit)就是通过数学运算将材料多目标性能转化成单目标性能的方法.Yamawaki等[120 ] 以利用热阻(R th )、电阻(R el )、Sebek系数(S )和温度(T )等构建的热电材料品质因子(ZT = R th S 2 T / R el )为目标量,利用声子和电子多功能交替传输的计算数据,通过Bayesian优化对潜在具有高热电性能的石墨烯纳米带进行结构优化,开发出了热电品质因子比原始材料高11倍的新型热电材料.硅有源芯片散热用导热介质对散热性高、附着性好、密度低等多种性能具有综合要求,Imanaka等[121 ] 构建了由热导率、热膨胀和比重等3个目标性能和2个约束项组成的等价于Ising模型的二次无约束二值优化能量方程,利用模拟退火算法,以最小化能量方程值为目标,优化出了高热导率、热膨胀系数接近Si、低比重的导热介质复合材料的最优成分.Nakamura等[122 ] 利用玻璃数据库INTERGRAD中的数据样本,以元素电负性、共价半径和Ahrens离子半径等构建了22个材料因子,建立玻璃折射率和阿贝(Abbe)数的高斯过程回归(Gaussian process regression)模型,通过线性组合将多目标转化为单目标进行优化设计,高效研发出了满足折射率和阿贝数性能要求的光学玻璃.Zhang等[123 ] 在主动学习框架下提出同时优化铜合金强度和导电性的策略,如图8 [123 ] 所示,利用成分-硬度-导电率数据样本,采用相关性筛选(correlation screening)、递归消除(recursive elimination)和穷举筛选(exhaustive screening)相结合的策略从170个初始特征中筛选出了原子体积、点阵常数和室温固溶度等5个影响合金硬度的合金因子,以及绝对电负性、第二电离能和核电子距离等6个影响导电率的合金因子,分别建立了硬度和导电率的支持向量机模型,以MOEI = EIHV × EIEC 为效能函数(MOEI表示硬度和导电率的共同期望提升,EIHV 和EIEC 分别表示硬度和导电率的期望提升),经过4次实验迭代,从上百万种合金成分中筛选出具有优良硬度和导热率的Cu-1.3Ni-1.4Co-0.56Si-0.03Mg合金,硬度、抗拉强度和导电率分别达到了275 HV、858 MPa和47.6% IACS,优于已报道的Cu-Ni-Co-Si系高强高导电铜合金.Chen等[124 ] 优化ZE62铸态镁合金屈服强度和塑形时,在欧氏空间中设立目标性能点,利用候选材料性能点与目标性能点之间的欧氏距离(Euclidean distance) (δ j )或原点与目标性能点和候选材料性能点向量之间的夹角(θ p ),如图9 [124 ] 所示,将多目标转化成单目标进行优化设计,基于正交设计的10种工艺参数制备的ZE62铸态镁合金的屈服强度和延伸率为数据样本,利用机器学习在23760种热处理工艺参数中筛选具有最优性能镁合金的热处理条件,利用有效全局优化算法,经过4次热处理工艺实验的反馈迭代,得到了ZE62铸态镁合金优化的热处理工艺,将镁合金屈服强度和塑性分别提高了27%和13.5%. ...
... [
117 ]
Fig.7 ![]()
4.2.2 多目标转单目标优化 通过应用场景分析确定材料所需的各项性能指标,将多目标性能进行加权线性组合转化为单目标,利用优化策略对单目标量进行优化设计,可以实现材料多个目标的优化,这种方法通常称为Ashby法[119 ] .功能材料的品质因子(figure of merit)就是通过数学运算将材料多目标性能转化成单目标性能的方法.Yamawaki等[120 ] 以利用热阻(R th )、电阻(R el )、Sebek系数(S )和温度(T )等构建的热电材料品质因子(ZT = R th S 2 T / R el )为目标量,利用声子和电子多功能交替传输的计算数据,通过Bayesian优化对潜在具有高热电性能的石墨烯纳米带进行结构优化,开发出了热电品质因子比原始材料高11倍的新型热电材料.硅有源芯片散热用导热介质对散热性高、附着性好、密度低等多种性能具有综合要求,Imanaka等[121 ] 构建了由热导率、热膨胀和比重等3个目标性能和2个约束项组成的等价于Ising模型的二次无约束二值优化能量方程,利用模拟退火算法,以最小化能量方程值为目标,优化出了高热导率、热膨胀系数接近Si、低比重的导热介质复合材料的最优成分.Nakamura等[122 ] 利用玻璃数据库INTERGRAD中的数据样本,以元素电负性、共价半径和Ahrens离子半径等构建了22个材料因子,建立玻璃折射率和阿贝(Abbe)数的高斯过程回归(Gaussian process regression)模型,通过线性组合将多目标转化为单目标进行优化设计,高效研发出了满足折射率和阿贝数性能要求的光学玻璃.Zhang等[123 ] 在主动学习框架下提出同时优化铜合金强度和导电性的策略,如图8 [123 ] 所示,利用成分-硬度-导电率数据样本,采用相关性筛选(correlation screening)、递归消除(recursive elimination)和穷举筛选(exhaustive screening)相结合的策略从170个初始特征中筛选出了原子体积、点阵常数和室温固溶度等5个影响合金硬度的合金因子,以及绝对电负性、第二电离能和核电子距离等6个影响导电率的合金因子,分别建立了硬度和导电率的支持向量机模型,以MOEI = EIHV × EIEC 为效能函数(MOEI表示硬度和导电率的共同期望提升,EIHV 和EIEC 分别表示硬度和导电率的期望提升),经过4次实验迭代,从上百万种合金成分中筛选出具有优良硬度和导热率的Cu-1.3Ni-1.4Co-0.56Si-0.03Mg合金,硬度、抗拉强度和导电率分别达到了275 HV、858 MPa和47.6% IACS,优于已报道的Cu-Ni-Co-Si系高强高导电铜合金.Chen等[124 ] 优化ZE62铸态镁合金屈服强度和塑形时,在欧氏空间中设立目标性能点,利用候选材料性能点与目标性能点之间的欧氏距离(Euclidean distance) (δ j )或原点与目标性能点和候选材料性能点向量之间的夹角(θ p ),如图9 [124 ] 所示,将多目标转化成单目标进行优化设计,基于正交设计的10种工艺参数制备的ZE62铸态镁合金的屈服强度和延伸率为数据样本,利用机器学习在23760种热处理工艺参数中筛选具有最优性能镁合金的热处理条件,利用有效全局优化算法,经过4次热处理工艺实验的反馈迭代,得到了ZE62铸态镁合金优化的热处理工艺,将镁合金屈服强度和塑性分别提高了27%和13.5%. ...
Accelerated design of L 12 -strengthened Co-base superalloys based on machine learning of experimental data
1
2020
... 逐层筛选优化是利用专家领域知识或机器学习模型,以材料基本性能下限为过滤器,过滤出基本性能满足要求的材料筛选空间,再优化材料关键性能的策略.Liu等[117 ] 利用如图7 [117 ] 所示的逐层筛选策略,根据高温合金抗高温氧化性能和γ' 相体积分数(≥ 60%)的领域知识和经验,确定了CoAlWNiTiTaCr七元钴基高温合金中Al和Cr元素的成分范围,利用热力学计算和实验数据,以材料参数和合金因子为特征,分别建立了γ' 相组织稳定性的分类模型和固溶温度、固相线、液相线、密度等4个机器学习回归模型,对是否含有害相、热处理窗口、凝固区间,以及密度进行筛选,在此基础上利用有效全局优化策略对γ' 相溶解温度进行优化,通过3次实验迭代,成功研发出其他性能满足要求、承温能力达到1266℃的新型钴基高温合金.Yu等[118 ] 在363000余种可能的候选合金成分空间中,利用分类模型预测γ' 和有害相是否存在,利用回归模型预测γ' 固溶线温度和体积分数,通过逐层筛选,研发出了6种满足性能需求的钴基高温合金. ...
Multi-objective optimization in material design and selection
1
2000
... 通过应用场景分析确定材料所需的各项性能指标,将多目标性能进行加权线性组合转化为单目标,利用优化策略对单目标量进行优化设计,可以实现材料多个目标的优化,这种方法通常称为Ashby法[119 ] .功能材料的品质因子(figure of merit)就是通过数学运算将材料多目标性能转化成单目标性能的方法.Yamawaki等[120 ] 以利用热阻(R th )、电阻(R el )、Sebek系数(S )和温度(T )等构建的热电材料品质因子(ZT = R th S 2 T / R el )为目标量,利用声子和电子多功能交替传输的计算数据,通过Bayesian优化对潜在具有高热电性能的石墨烯纳米带进行结构优化,开发出了热电品质因子比原始材料高11倍的新型热电材料.硅有源芯片散热用导热介质对散热性高、附着性好、密度低等多种性能具有综合要求,Imanaka等[121 ] 构建了由热导率、热膨胀和比重等3个目标性能和2个约束项组成的等价于Ising模型的二次无约束二值优化能量方程,利用模拟退火算法,以最小化能量方程值为目标,优化出了高热导率、热膨胀系数接近Si、低比重的导热介质复合材料的最优成分.Nakamura等[122 ] 利用玻璃数据库INTERGRAD中的数据样本,以元素电负性、共价半径和Ahrens离子半径等构建了22个材料因子,建立玻璃折射率和阿贝(Abbe)数的高斯过程回归(Gaussian process regression)模型,通过线性组合将多目标转化为单目标进行优化设计,高效研发出了满足折射率和阿贝数性能要求的光学玻璃.Zhang等[123 ] 在主动学习框架下提出同时优化铜合金强度和导电性的策略,如图8 [123 ] 所示,利用成分-硬度-导电率数据样本,采用相关性筛选(correlation screening)、递归消除(recursive elimination)和穷举筛选(exhaustive screening)相结合的策略从170个初始特征中筛选出了原子体积、点阵常数和室温固溶度等5个影响合金硬度的合金因子,以及绝对电负性、第二电离能和核电子距离等6个影响导电率的合金因子,分别建立了硬度和导电率的支持向量机模型,以MOEI = EIHV × EIEC 为效能函数(MOEI表示硬度和导电率的共同期望提升,EIHV 和EIEC 分别表示硬度和导电率的期望提升),经过4次实验迭代,从上百万种合金成分中筛选出具有优良硬度和导热率的Cu-1.3Ni-1.4Co-0.56Si-0.03Mg合金,硬度、抗拉强度和导电率分别达到了275 HV、858 MPa和47.6% IACS,优于已报道的Cu-Ni-Co-Si系高强高导电铜合金.Chen等[124 ] 优化ZE62铸态镁合金屈服强度和塑形时,在欧氏空间中设立目标性能点,利用候选材料性能点与目标性能点之间的欧氏距离(Euclidean distance) (δ j )或原点与目标性能点和候选材料性能点向量之间的夹角(θ p ),如图9 [124 ] 所示,将多目标转化成单目标进行优化设计,基于正交设计的10种工艺参数制备的ZE62铸态镁合金的屈服强度和延伸率为数据样本,利用机器学习在23760种热处理工艺参数中筛选具有最优性能镁合金的热处理条件,利用有效全局优化算法,经过4次热处理工艺实验的反馈迭代,得到了ZE62铸态镁合金优化的热处理工艺,将镁合金屈服强度和塑性分别提高了27%和13.5%. ...
Multifunctional structural design of graphene thermoelectrics by Bayesian optimization
1
2018
... 通过应用场景分析确定材料所需的各项性能指标,将多目标性能进行加权线性组合转化为单目标,利用优化策略对单目标量进行优化设计,可以实现材料多个目标的优化,这种方法通常称为Ashby法[119 ] .功能材料的品质因子(figure of merit)就是通过数学运算将材料多目标性能转化成单目标性能的方法.Yamawaki等[120 ] 以利用热阻(R th )、电阻(R el )、Sebek系数(S )和温度(T )等构建的热电材料品质因子(ZT = R th S 2 T / R el )为目标量,利用声子和电子多功能交替传输的计算数据,通过Bayesian优化对潜在具有高热电性能的石墨烯纳米带进行结构优化,开发出了热电品质因子比原始材料高11倍的新型热电材料.硅有源芯片散热用导热介质对散热性高、附着性好、密度低等多种性能具有综合要求,Imanaka等[121 ] 构建了由热导率、热膨胀和比重等3个目标性能和2个约束项组成的等价于Ising模型的二次无约束二值优化能量方程,利用模拟退火算法,以最小化能量方程值为目标,优化出了高热导率、热膨胀系数接近Si、低比重的导热介质复合材料的最优成分.Nakamura等[122 ] 利用玻璃数据库INTERGRAD中的数据样本,以元素电负性、共价半径和Ahrens离子半径等构建了22个材料因子,建立玻璃折射率和阿贝(Abbe)数的高斯过程回归(Gaussian process regression)模型,通过线性组合将多目标转化为单目标进行优化设计,高效研发出了满足折射率和阿贝数性能要求的光学玻璃.Zhang等[123 ] 在主动学习框架下提出同时优化铜合金强度和导电性的策略,如图8 [123 ] 所示,利用成分-硬度-导电率数据样本,采用相关性筛选(correlation screening)、递归消除(recursive elimination)和穷举筛选(exhaustive screening)相结合的策略从170个初始特征中筛选出了原子体积、点阵常数和室温固溶度等5个影响合金硬度的合金因子,以及绝对电负性、第二电离能和核电子距离等6个影响导电率的合金因子,分别建立了硬度和导电率的支持向量机模型,以MOEI = EIHV × EIEC 为效能函数(MOEI表示硬度和导电率的共同期望提升,EIHV 和EIEC 分别表示硬度和导电率的期望提升),经过4次实验迭代,从上百万种合金成分中筛选出具有优良硬度和导热率的Cu-1.3Ni-1.4Co-0.56Si-0.03Mg合金,硬度、抗拉强度和导电率分别达到了275 HV、858 MPa和47.6% IACS,优于已报道的Cu-Ni-Co-Si系高强高导电铜合金.Chen等[124 ] 优化ZE62铸态镁合金屈服强度和塑形时,在欧氏空间中设立目标性能点,利用候选材料性能点与目标性能点之间的欧氏距离(Euclidean distance) (δ j )或原点与目标性能点和候选材料性能点向量之间的夹角(θ p ),如图9 [124 ] 所示,将多目标转化成单目标进行优化设计,基于正交设计的10种工艺参数制备的ZE62铸态镁合金的屈服强度和延伸率为数据样本,利用机器学习在23760种热处理工艺参数中筛选具有最优性能镁合金的热处理条件,利用有效全局优化算法,经过4次热处理工艺实验的反馈迭代,得到了ZE62铸态镁合金优化的热处理工艺,将镁合金屈服强度和塑性分别提高了27%和13.5%. ...
Optimization of the composition in a composite material for microelectronics application using the Ising model
1
2021
... 通过应用场景分析确定材料所需的各项性能指标,将多目标性能进行加权线性组合转化为单目标,利用优化策略对单目标量进行优化设计,可以实现材料多个目标的优化,这种方法通常称为Ashby法[119 ] .功能材料的品质因子(figure of merit)就是通过数学运算将材料多目标性能转化成单目标性能的方法.Yamawaki等[120 ] 以利用热阻(R th )、电阻(R el )、Sebek系数(S )和温度(T )等构建的热电材料品质因子(ZT = R th S 2 T / R el )为目标量,利用声子和电子多功能交替传输的计算数据,通过Bayesian优化对潜在具有高热电性能的石墨烯纳米带进行结构优化,开发出了热电品质因子比原始材料高11倍的新型热电材料.硅有源芯片散热用导热介质对散热性高、附着性好、密度低等多种性能具有综合要求,Imanaka等[121 ] 构建了由热导率、热膨胀和比重等3个目标性能和2个约束项组成的等价于Ising模型的二次无约束二值优化能量方程,利用模拟退火算法,以最小化能量方程值为目标,优化出了高热导率、热膨胀系数接近Si、低比重的导热介质复合材料的最优成分.Nakamura等[122 ] 利用玻璃数据库INTERGRAD中的数据样本,以元素电负性、共价半径和Ahrens离子半径等构建了22个材料因子,建立玻璃折射率和阿贝(Abbe)数的高斯过程回归(Gaussian process regression)模型,通过线性组合将多目标转化为单目标进行优化设计,高效研发出了满足折射率和阿贝数性能要求的光学玻璃.Zhang等[123 ] 在主动学习框架下提出同时优化铜合金强度和导电性的策略,如图8 [123 ] 所示,利用成分-硬度-导电率数据样本,采用相关性筛选(correlation screening)、递归消除(recursive elimination)和穷举筛选(exhaustive screening)相结合的策略从170个初始特征中筛选出了原子体积、点阵常数和室温固溶度等5个影响合金硬度的合金因子,以及绝对电负性、第二电离能和核电子距离等6个影响导电率的合金因子,分别建立了硬度和导电率的支持向量机模型,以MOEI = EIHV × EIEC 为效能函数(MOEI表示硬度和导电率的共同期望提升,EIHV 和EIEC 分别表示硬度和导电率的期望提升),经过4次实验迭代,从上百万种合金成分中筛选出具有优良硬度和导热率的Cu-1.3Ni-1.4Co-0.56Si-0.03Mg合金,硬度、抗拉强度和导电率分别达到了275 HV、858 MPa和47.6% IACS,优于已报道的Cu-Ni-Co-Si系高强高导电铜合金.Chen等[124 ] 优化ZE62铸态镁合金屈服强度和塑形时,在欧氏空间中设立目标性能点,利用候选材料性能点与目标性能点之间的欧氏距离(Euclidean distance) (δ j )或原点与目标性能点和候选材料性能点向量之间的夹角(θ p ),如图9 [124 ] 所示,将多目标转化成单目标进行优化设计,基于正交设计的10种工艺参数制备的ZE62铸态镁合金的屈服强度和延伸率为数据样本,利用机器学习在23760种热处理工艺参数中筛选具有最优性能镁合金的热处理条件,利用有效全局优化算法,经过4次热处理工艺实验的反馈迭代,得到了ZE62铸态镁合金优化的热处理工艺,将镁合金屈服强度和塑性分别提高了27%和13.5%. ...
Multi-objective Bayesian optimization of optical glass compositions
1
2021
... 通过应用场景分析确定材料所需的各项性能指标,将多目标性能进行加权线性组合转化为单目标,利用优化策略对单目标量进行优化设计,可以实现材料多个目标的优化,这种方法通常称为Ashby法[119 ] .功能材料的品质因子(figure of merit)就是通过数学运算将材料多目标性能转化成单目标性能的方法.Yamawaki等[120 ] 以利用热阻(R th )、电阻(R el )、Sebek系数(S )和温度(T )等构建的热电材料品质因子(ZT = R th S 2 T / R el )为目标量,利用声子和电子多功能交替传输的计算数据,通过Bayesian优化对潜在具有高热电性能的石墨烯纳米带进行结构优化,开发出了热电品质因子比原始材料高11倍的新型热电材料.硅有源芯片散热用导热介质对散热性高、附着性好、密度低等多种性能具有综合要求,Imanaka等[121 ] 构建了由热导率、热膨胀和比重等3个目标性能和2个约束项组成的等价于Ising模型的二次无约束二值优化能量方程,利用模拟退火算法,以最小化能量方程值为目标,优化出了高热导率、热膨胀系数接近Si、低比重的导热介质复合材料的最优成分.Nakamura等[122 ] 利用玻璃数据库INTERGRAD中的数据样本,以元素电负性、共价半径和Ahrens离子半径等构建了22个材料因子,建立玻璃折射率和阿贝(Abbe)数的高斯过程回归(Gaussian process regression)模型,通过线性组合将多目标转化为单目标进行优化设计,高效研发出了满足折射率和阿贝数性能要求的光学玻璃.Zhang等[123 ] 在主动学习框架下提出同时优化铜合金强度和导电性的策略,如图8 [123 ] 所示,利用成分-硬度-导电率数据样本,采用相关性筛选(correlation screening)、递归消除(recursive elimination)和穷举筛选(exhaustive screening)相结合的策略从170个初始特征中筛选出了原子体积、点阵常数和室温固溶度等5个影响合金硬度的合金因子,以及绝对电负性、第二电离能和核电子距离等6个影响导电率的合金因子,分别建立了硬度和导电率的支持向量机模型,以MOEI = EIHV × EIEC 为效能函数(MOEI表示硬度和导电率的共同期望提升,EIHV 和EIEC 分别表示硬度和导电率的期望提升),经过4次实验迭代,从上百万种合金成分中筛选出具有优良硬度和导热率的Cu-1.3Ni-1.4Co-0.56Si-0.03Mg合金,硬度、抗拉强度和导电率分别达到了275 HV、858 MPa和47.6% IACS,优于已报道的Cu-Ni-Co-Si系高强高导电铜合金.Chen等[124 ] 优化ZE62铸态镁合金屈服强度和塑形时,在欧氏空间中设立目标性能点,利用候选材料性能点与目标性能点之间的欧氏距离(Euclidean distance) (δ j )或原点与目标性能点和候选材料性能点向量之间的夹角(θ p ),如图9 [124 ] 所示,将多目标转化成单目标进行优化设计,基于正交设计的10种工艺参数制备的ZE62铸态镁合金的屈服强度和延伸率为数据样本,利用机器学习在23760种热处理工艺参数中筛选具有最优性能镁合金的热处理条件,利用有效全局优化算法,经过4次热处理工艺实验的反馈迭代,得到了ZE62铸态镁合金优化的热处理工艺,将镁合金屈服强度和塑性分别提高了27%和13.5%. ...
Machine learning assisted composition effective design for precipitation strengthened copper alloys
4
2021
... 通过应用场景分析确定材料所需的各项性能指标,将多目标性能进行加权线性组合转化为单目标,利用优化策略对单目标量进行优化设计,可以实现材料多个目标的优化,这种方法通常称为Ashby法[119 ] .功能材料的品质因子(figure of merit)就是通过数学运算将材料多目标性能转化成单目标性能的方法.Yamawaki等[120 ] 以利用热阻(R th )、电阻(R el )、Sebek系数(S )和温度(T )等构建的热电材料品质因子(ZT = R th S 2 T / R el )为目标量,利用声子和电子多功能交替传输的计算数据,通过Bayesian优化对潜在具有高热电性能的石墨烯纳米带进行结构优化,开发出了热电品质因子比原始材料高11倍的新型热电材料.硅有源芯片散热用导热介质对散热性高、附着性好、密度低等多种性能具有综合要求,Imanaka等[121 ] 构建了由热导率、热膨胀和比重等3个目标性能和2个约束项组成的等价于Ising模型的二次无约束二值优化能量方程,利用模拟退火算法,以最小化能量方程值为目标,优化出了高热导率、热膨胀系数接近Si、低比重的导热介质复合材料的最优成分.Nakamura等[122 ] 利用玻璃数据库INTERGRAD中的数据样本,以元素电负性、共价半径和Ahrens离子半径等构建了22个材料因子,建立玻璃折射率和阿贝(Abbe)数的高斯过程回归(Gaussian process regression)模型,通过线性组合将多目标转化为单目标进行优化设计,高效研发出了满足折射率和阿贝数性能要求的光学玻璃.Zhang等[123 ] 在主动学习框架下提出同时优化铜合金强度和导电性的策略,如图8 [123 ] 所示,利用成分-硬度-导电率数据样本,采用相关性筛选(correlation screening)、递归消除(recursive elimination)和穷举筛选(exhaustive screening)相结合的策略从170个初始特征中筛选出了原子体积、点阵常数和室温固溶度等5个影响合金硬度的合金因子,以及绝对电负性、第二电离能和核电子距离等6个影响导电率的合金因子,分别建立了硬度和导电率的支持向量机模型,以MOEI = EIHV × EIEC 为效能函数(MOEI表示硬度和导电率的共同期望提升,EIHV 和EIEC 分别表示硬度和导电率的期望提升),经过4次实验迭代,从上百万种合金成分中筛选出具有优良硬度和导热率的Cu-1.3Ni-1.4Co-0.56Si-0.03Mg合金,硬度、抗拉强度和导电率分别达到了275 HV、858 MPa和47.6% IACS,优于已报道的Cu-Ni-Co-Si系高强高导电铜合金.Chen等[124 ] 优化ZE62铸态镁合金屈服强度和塑形时,在欧氏空间中设立目标性能点,利用候选材料性能点与目标性能点之间的欧氏距离(Euclidean distance) (δ j )或原点与目标性能点和候选材料性能点向量之间的夹角(θ p ),如图9 [124 ] 所示,将多目标转化成单目标进行优化设计,基于正交设计的10种工艺参数制备的ZE62铸态镁合金的屈服强度和延伸率为数据样本,利用机器学习在23760种热处理工艺参数中筛选具有最优性能镁合金的热处理条件,利用有效全局优化算法,经过4次热处理工艺实验的反馈迭代,得到了ZE62铸态镁合金优化的热处理工艺,将镁合金屈服强度和塑性分别提高了27%和13.5%. ...
... [123 ]所示,利用成分-硬度-导电率数据样本,采用相关性筛选(correlation screening)、递归消除(recursive elimination)和穷举筛选(exhaustive screening)相结合的策略从170个初始特征中筛选出了原子体积、点阵常数和室温固溶度等5个影响合金硬度的合金因子,以及绝对电负性、第二电离能和核电子距离等6个影响导电率的合金因子,分别建立了硬度和导电率的支持向量机模型,以MOEI = EIHV × EIEC 为效能函数(MOEI表示硬度和导电率的共同期望提升,EIHV 和EIEC 分别表示硬度和导电率的期望提升),经过4次实验迭代,从上百万种合金成分中筛选出具有优良硬度和导热率的Cu-1.3Ni-1.4Co-0.56Si-0.03Mg合金,硬度、抗拉强度和导电率分别达到了275 HV、858 MPa和47.6% IACS,优于已报道的Cu-Ni-Co-Si系高强高导电铜合金.Chen等[124 ] 优化ZE62铸态镁合金屈服强度和塑形时,在欧氏空间中设立目标性能点,利用候选材料性能点与目标性能点之间的欧氏距离(Euclidean distance) (δ j )或原点与目标性能点和候选材料性能点向量之间的夹角(θ p ),如图9 [124 ] 所示,将多目标转化成单目标进行优化设计,基于正交设计的10种工艺参数制备的ZE62铸态镁合金的屈服强度和延伸率为数据样本,利用机器学习在23760种热处理工艺参数中筛选具有最优性能镁合金的热处理条件,利用有效全局优化算法,经过4次热处理工艺实验的反馈迭代,得到了ZE62铸态镁合金优化的热处理工艺,将镁合金屈服强度和塑性分别提高了27%和13.5%. ...
... [
123 ]
Design strategy of precipitation strengthened copper alloys based on alloy factor screening and Bayesian optimization (MOEI represents the simultaneous improvement of mechanical and electrical properties based on the benchmark property <i>μ</i><sup>*</sup>, since EI<sub>HV</sub> and EI<sub>EC</sub>, respectively represent the property improvement (hardness, electrical conductivity) based on the benchmark properties <span class="formulaText"><inline-formula><math id="M2"><msubsup><mrow><mi>μ</mi></mrow><mrow><mi mathvariant="normal">H</mi><mi mathvariant="normal">V</mi></mrow><mrow><mi mathvariant="normal">*</mi></mrow></msubsup></math></span></inline-formula></span> and <span class="formulaText"><inline-formula><math id="M3"><msubsup><mrow><mi>μ</mi></mrow><mrow><mi mathvariant="normal">E</mi><mi mathvariant="normal">C</mi></mrow><mrow><mi mathvariant="normal">*</mi></mrow></msubsup></math></span></inline-formula></span><span class="formulaNumber">)</span><sup>[<xref ref-type="bibr" rid="R123">123</xref>]</sup> Fig.8 ![]()
图9 多目标转化为单目标优化的方法<sup>[<xref ref-type="bibr" rid="R124">124</xref>]</sup> Transformation of multi-objective into single-objective optimization methods (<i>θ<sup/></i><sup>p</sup>—the angle between the target vector (<i>ω</i><sup>t</sup>) and the Pareto front vector (<i>ω</i><sup>p</sup>), <i>δ<sup> j</sup></i>—the distance from a point in the virtual space to the target)<sup>[<xref ref-type="bibr" rid="R124">124</xref>]</sup> Fig.9 ![]()
4.2.3 Pareto前沿优化 材料多目标性能优化时,若候选样本A的某个(或某几个)目标性能值优于样本C,而其他目标性能劣于样本C,则称A样本无差别于C样本,如图10 所示,若候选样本A的所有目标性能均优于样本B,则称A支配B或B受支配于A.当样本A没有支配或受支配的样本时,则称A为非支配解.Pareto前沿是无差别样本组成空间曲面,Pareto优化是将Pareto前沿向非支配解空间推进,通过寻找非支配空间的最优解实现多目标协同优化. ...
... [
123 ]
Fig.8 ![]()
图9 多目标转化为单目标优化的方法<sup>[<xref ref-type="bibr" rid="R124">124</xref>]</sup> Transformation of multi-objective into single-objective optimization methods (<i>θ<sup/></i><sup>p</sup>—the angle between the target vector (<i>ω</i><sup>t</sup>) and the Pareto front vector (<i>ω</i><sup>p</sup>), <i>δ<sup> j</sup></i>—the distance from a point in the virtual space to the target)<sup>[<xref ref-type="bibr" rid="R124">124</xref>]</sup> Fig.9 ![]()
4.2.3 Pareto前沿优化 材料多目标性能优化时,若候选样本A的某个(或某几个)目标性能值优于样本C,而其他目标性能劣于样本C,则称A样本无差别于C样本,如图10 所示,若候选样本A的所有目标性能均优于样本B,则称A支配B或B受支配于A.当样本A没有支配或受支配的样本时,则称A为非支配解.Pareto前沿是无差别样本组成空间曲面,Pareto优化是将Pareto前沿向非支配解空间推进,通过寻找非支配空间的最优解实现多目标协同优化. ...
Machine learning assisted multi-objective optimization for materials processing parameters: A case study in Mg alloy
4
2020
... 通过应用场景分析确定材料所需的各项性能指标,将多目标性能进行加权线性组合转化为单目标,利用优化策略对单目标量进行优化设计,可以实现材料多个目标的优化,这种方法通常称为Ashby法[119 ] .功能材料的品质因子(figure of merit)就是通过数学运算将材料多目标性能转化成单目标性能的方法.Yamawaki等[120 ] 以利用热阻(R th )、电阻(R el )、Sebek系数(S )和温度(T )等构建的热电材料品质因子(ZT = R th S 2 T / R el )为目标量,利用声子和电子多功能交替传输的计算数据,通过Bayesian优化对潜在具有高热电性能的石墨烯纳米带进行结构优化,开发出了热电品质因子比原始材料高11倍的新型热电材料.硅有源芯片散热用导热介质对散热性高、附着性好、密度低等多种性能具有综合要求,Imanaka等[121 ] 构建了由热导率、热膨胀和比重等3个目标性能和2个约束项组成的等价于Ising模型的二次无约束二值优化能量方程,利用模拟退火算法,以最小化能量方程值为目标,优化出了高热导率、热膨胀系数接近Si、低比重的导热介质复合材料的最优成分.Nakamura等[122 ] 利用玻璃数据库INTERGRAD中的数据样本,以元素电负性、共价半径和Ahrens离子半径等构建了22个材料因子,建立玻璃折射率和阿贝(Abbe)数的高斯过程回归(Gaussian process regression)模型,通过线性组合将多目标转化为单目标进行优化设计,高效研发出了满足折射率和阿贝数性能要求的光学玻璃.Zhang等[123 ] 在主动学习框架下提出同时优化铜合金强度和导电性的策略,如图8 [123 ] 所示,利用成分-硬度-导电率数据样本,采用相关性筛选(correlation screening)、递归消除(recursive elimination)和穷举筛选(exhaustive screening)相结合的策略从170个初始特征中筛选出了原子体积、点阵常数和室温固溶度等5个影响合金硬度的合金因子,以及绝对电负性、第二电离能和核电子距离等6个影响导电率的合金因子,分别建立了硬度和导电率的支持向量机模型,以MOEI = EIHV × EIEC 为效能函数(MOEI表示硬度和导电率的共同期望提升,EIHV 和EIEC 分别表示硬度和导电率的期望提升),经过4次实验迭代,从上百万种合金成分中筛选出具有优良硬度和导热率的Cu-1.3Ni-1.4Co-0.56Si-0.03Mg合金,硬度、抗拉强度和导电率分别达到了275 HV、858 MPa和47.6% IACS,优于已报道的Cu-Ni-Co-Si系高强高导电铜合金.Chen等[124 ] 优化ZE62铸态镁合金屈服强度和塑形时,在欧氏空间中设立目标性能点,利用候选材料性能点与目标性能点之间的欧氏距离(Euclidean distance) (δ j )或原点与目标性能点和候选材料性能点向量之间的夹角(θ p ),如图9 [124 ] 所示,将多目标转化成单目标进行优化设计,基于正交设计的10种工艺参数制备的ZE62铸态镁合金的屈服强度和延伸率为数据样本,利用机器学习在23760种热处理工艺参数中筛选具有最优性能镁合金的热处理条件,利用有效全局优化算法,经过4次热处理工艺实验的反馈迭代,得到了ZE62铸态镁合金优化的热处理工艺,将镁合金屈服强度和塑性分别提高了27%和13.5%. ...
... [124 ]所示,将多目标转化成单目标进行优化设计,基于正交设计的10种工艺参数制备的ZE62铸态镁合金的屈服强度和延伸率为数据样本,利用机器学习在23760种热处理工艺参数中筛选具有最优性能镁合金的热处理条件,利用有效全局优化算法,经过4次热处理工艺实验的反馈迭代,得到了ZE62铸态镁合金优化的热处理工艺,将镁合金屈服强度和塑性分别提高了27%和13.5%. ...
... [
124 ]
Transformation of multi-objective into single-objective optimization methods (<i>θ<sup/></i><sup>p</sup>—the angle between the target vector (<i>ω</i><sup>t</sup>) and the Pareto front vector (<i>ω</i><sup>p</sup>), <i>δ<sup> j</sup></i>—the distance from a point in the virtual space to the target)<sup>[<xref ref-type="bibr" rid="R124">124</xref>]</sup> Fig.9 ![]()
4.2.3 Pareto前沿优化 材料多目标性能优化时,若候选样本A的某个(或某几个)目标性能值优于样本C,而其他目标性能劣于样本C,则称A样本无差别于C样本,如图10 所示,若候选样本A的所有目标性能均优于样本B,则称A支配B或B受支配于A.当样本A没有支配或受支配的样本时,则称A为非支配解.Pareto前沿是无差别样本组成空间曲面,Pareto优化是将Pareto前沿向非支配解空间推进,通过寻找非支配空间的最优解实现多目标协同优化. ...
... [
124 ]
Fig.9 ![]()
4.2.3 Pareto前沿优化 材料多目标性能优化时,若候选样本A的某个(或某几个)目标性能值优于样本C,而其他目标性能劣于样本C,则称A样本无差别于C样本,如图10 所示,若候选样本A的所有目标性能均优于样本B,则称A支配B或B受支配于A.当样本A没有支配或受支配的样本时,则称A为非支配解.Pareto前沿是无差别样本组成空间曲面,Pareto优化是将Pareto前沿向非支配解空间推进,通过寻找非支配空间的最优解实现多目标协同优化. ...
Evolutionary design of strong and stable high entropy alloys using multi-objective optimisation based on physical models, statistics and thermodynamics
1
2018
... Pareto前沿优化的搜索空间巨大,一般需要引入主动学习的思想(4.1.1节)或结合启发式优化算法(4.1.2节),提高Pareto前沿优化的效率.Menou等[125 ] 将固溶强化物理模型、热力学计算和机器学习相融合,利用Pareto优化遗传算法,搜索同时满足单相结构、高硬度和低密度需求的五元以上高熵合金,在Al、Cu、Fe等16种元素构成的巨大成分空间内,优化出了上千种高熵合金的候选合金成分,选择Al35 Cr35 -Mn8 Mo5 Ti17 合金进行实验验证,证明了制备的合金为单相固溶体,且满足高硬度(Vickers硬度1.78 GPa)和低密度(7.95 g/cm3 )的要求.Fang等[126 ] 利用52个Al-Zn-Mg-Cu系铝合金数据样本,建立最小二乘法支持向量机(LSSVM)预测模型,预测得到不同时效温度和时效时间处理下Al合金硬度和电导率的Pareto前沿,利用多目标遗传算法,优化高硬度和高电导率铝合金时效处理工艺.Gopakumar等[127 ] 利用100余条形状记忆合金的实验数据样本、223条M 2 AX 相第一性原理计算数据样本,以及704条压电材料的数据样本,建立支持向量机预测模型,将单目标优化的效能函数拓展至高维目标空间,提出了EICentroid 和EImaximin 策略,通过Pareto前沿优化了材料的多目标性能.Solomou等[128 ] 提出了基于Bayesian全局优化的材料多目标设计框架,如图11 [128 ] 所示,利用有限元计算和第一性原理计算数据,建立了Ti-Ni基形状记忆合金相变温度和热滞后温度双目标性能的Gaussian过程回归模型,以超体积的期望提升为效能方程进行优化设计,结果对比表明该设计框架与物理模型指导下的材料优化设计具有更高的效率. ...
An approach for the aging pro-cess optimization of Al?Zn?Mg?Cu series alloys
1
2009
... Pareto前沿优化的搜索空间巨大,一般需要引入主动学习的思想(4.1.1节)或结合启发式优化算法(4.1.2节),提高Pareto前沿优化的效率.Menou等[125 ] 将固溶强化物理模型、热力学计算和机器学习相融合,利用Pareto优化遗传算法,搜索同时满足单相结构、高硬度和低密度需求的五元以上高熵合金,在Al、Cu、Fe等16种元素构成的巨大成分空间内,优化出了上千种高熵合金的候选合金成分,选择Al35 Cr35 -Mn8 Mo5 Ti17 合金进行实验验证,证明了制备的合金为单相固溶体,且满足高硬度(Vickers硬度1.78 GPa)和低密度(7.95 g/cm3 )的要求.Fang等[126 ] 利用52个Al-Zn-Mg-Cu系铝合金数据样本,建立最小二乘法支持向量机(LSSVM)预测模型,预测得到不同时效温度和时效时间处理下Al合金硬度和电导率的Pareto前沿,利用多目标遗传算法,优化高硬度和高电导率铝合金时效处理工艺.Gopakumar等[127 ] 利用100余条形状记忆合金的实验数据样本、223条M 2 AX 相第一性原理计算数据样本,以及704条压电材料的数据样本,建立支持向量机预测模型,将单目标优化的效能函数拓展至高维目标空间,提出了EICentroid 和EImaximin 策略,通过Pareto前沿优化了材料的多目标性能.Solomou等[128 ] 提出了基于Bayesian全局优化的材料多目标设计框架,如图11 [128 ] 所示,利用有限元计算和第一性原理计算数据,建立了Ti-Ni基形状记忆合金相变温度和热滞后温度双目标性能的Gaussian过程回归模型,以超体积的期望提升为效能方程进行优化设计,结果对比表明该设计框架与物理模型指导下的材料优化设计具有更高的效率. ...
Multi-objective optimization for materials discovery via adaptive design
1
2018
... Pareto前沿优化的搜索空间巨大,一般需要引入主动学习的思想(4.1.1节)或结合启发式优化算法(4.1.2节),提高Pareto前沿优化的效率.Menou等[125 ] 将固溶强化物理模型、热力学计算和机器学习相融合,利用Pareto优化遗传算法,搜索同时满足单相结构、高硬度和低密度需求的五元以上高熵合金,在Al、Cu、Fe等16种元素构成的巨大成分空间内,优化出了上千种高熵合金的候选合金成分,选择Al35 Cr35 -Mn8 Mo5 Ti17 合金进行实验验证,证明了制备的合金为单相固溶体,且满足高硬度(Vickers硬度1.78 GPa)和低密度(7.95 g/cm3 )的要求.Fang等[126 ] 利用52个Al-Zn-Mg-Cu系铝合金数据样本,建立最小二乘法支持向量机(LSSVM)预测模型,预测得到不同时效温度和时效时间处理下Al合金硬度和电导率的Pareto前沿,利用多目标遗传算法,优化高硬度和高电导率铝合金时效处理工艺.Gopakumar等[127 ] 利用100余条形状记忆合金的实验数据样本、223条M 2 AX 相第一性原理计算数据样本,以及704条压电材料的数据样本,建立支持向量机预测模型,将单目标优化的效能函数拓展至高维目标空间,提出了EICentroid 和EImaximin 策略,通过Pareto前沿优化了材料的多目标性能.Solomou等[128 ] 提出了基于Bayesian全局优化的材料多目标设计框架,如图11 [128 ] 所示,利用有限元计算和第一性原理计算数据,建立了Ti-Ni基形状记忆合金相变温度和热滞后温度双目标性能的Gaussian过程回归模型,以超体积的期望提升为效能方程进行优化设计,结果对比表明该设计框架与物理模型指导下的材料优化设计具有更高的效率. ...
Multi-objective Bayesian materials discovery: Application on the discovery of precipitation strengthened NiTi shape memory alloys through micromechanical modeling
4
2018
... Pareto前沿优化的搜索空间巨大,一般需要引入主动学习的思想(4.1.1节)或结合启发式优化算法(4.1.2节),提高Pareto前沿优化的效率.Menou等[125 ] 将固溶强化物理模型、热力学计算和机器学习相融合,利用Pareto优化遗传算法,搜索同时满足单相结构、高硬度和低密度需求的五元以上高熵合金,在Al、Cu、Fe等16种元素构成的巨大成分空间内,优化出了上千种高熵合金的候选合金成分,选择Al35 Cr35 -Mn8 Mo5 Ti17 合金进行实验验证,证明了制备的合金为单相固溶体,且满足高硬度(Vickers硬度1.78 GPa)和低密度(7.95 g/cm3 )的要求.Fang等[126 ] 利用52个Al-Zn-Mg-Cu系铝合金数据样本,建立最小二乘法支持向量机(LSSVM)预测模型,预测得到不同时效温度和时效时间处理下Al合金硬度和电导率的Pareto前沿,利用多目标遗传算法,优化高硬度和高电导率铝合金时效处理工艺.Gopakumar等[127 ] 利用100余条形状记忆合金的实验数据样本、223条M 2 AX 相第一性原理计算数据样本,以及704条压电材料的数据样本,建立支持向量机预测模型,将单目标优化的效能函数拓展至高维目标空间,提出了EICentroid 和EImaximin 策略,通过Pareto前沿优化了材料的多目标性能.Solomou等[128 ] 提出了基于Bayesian全局优化的材料多目标设计框架,如图11 [128 ] 所示,利用有限元计算和第一性原理计算数据,建立了Ti-Ni基形状记忆合金相变温度和热滞后温度双目标性能的Gaussian过程回归模型,以超体积的期望提升为效能方程进行优化设计,结果对比表明该设计框架与物理模型指导下的材料优化设计具有更高的效率. ...
... [128 ]所示,利用有限元计算和第一性原理计算数据,建立了Ti-Ni基形状记忆合金相变温度和热滞后温度双目标性能的Gaussian过程回归模型,以超体积的期望提升为效能方程进行优化设计,结果对比表明该设计框架与物理模型指导下的材料优化设计具有更高的效率. ...
... [
128 ]
Multi-objective Bayesian optimization framework (SMA—shape memory alloy, EHVI—expected hyper-volume improvement)<sup>[<xref ref-type="bibr" rid="R128">128</xref>]</sup> Fig.11 ![]()
<strong>4.3 </strong>材料逆向设计 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
... [
128 ]
Fig.11 ![]()
<strong>4.3 </strong>材料逆向设计 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
Inverse design in search of materials with target functionalities
1
2018
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
Machine learning for molecular and materials science
1
2018
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
Inverse molecular design using machine learning: Generative models for matter engineering
1
2018
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
SegNet: A deep convolutional encoder-decoder architecture for image segmentation
1
2017
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
Describing multimedia content using attention-based encoder-decoder networks
0
2015
Planning chemical syntheses with deep neural networks and symbolic AI
1
2018
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
Automatic chemical design using a data-driven continuous representation of molecules
5
2018
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
... 变分自解码策略(VAE)是借助深度神经网络将离散的材料数据表示转换为多维连续的变量(编码器)进行设计,再将所设计多维连续变量转换为材料表示(解码器),如图12 [135 ] 所示.通过编码过程将提取的材料表示信息压缩到低维潜在空间形成变量,为了满足梯度式的性能优化,变量会被添加噪声形成潜在空间的概率分布,生成类似数据,迫使解码器学习如何解码对应空间之外更广泛的潜在点.该方法较适合于通过隐形空间的简单操作自动生成新材料结构,从而对开放的化合物空间进行有效的探索. ...
... [
135 ]
The materials reverse design process by encoding and decoding (SMILES—simplified molecular-input line-entry system)<sup>[<xref ref-type="bibr" rid="R135">135</xref>]</sup> Fig.12 ![]()
Gómez-Bombarelli等[135 ] 将变分自解码策略应用于类药物分子和少于9个重原子的分子设计,数据样本包括QM9数据库的10.8万个分子和ZINC数据库中的25万个类药物分子数据,通过对VAE体系结构和训练超参数进行随机优化,使QM9和ZINC数据集在潜在空间的表示分别具有156和196个维度,从而捕获数据最显著的信息;以ZINC数据集为例,对于给定潜在空间中的一个点,解码器网络产生相应的材料表示,以高斯过程(Gaussian process)为训练模型完成潜在空间目标属性的预测,以药物相似性QED和合成可得性SAS为目标属性,在潜在空间中进行基于梯度的属性优化,寻找到具有较高目标性能的新的潜在变量,解码为新获取的候选材料表示.相较传统的遗传算法局部优化,该策略最终全局优化出了性能优化的新材料.Noh等[136 ] 提出了一种针对固态材料逆向设计的变分自编码策略框架,基于图像的可逆生成模型成功地发现了实验中已探明的高性能钒氧化物,生成模型的计算效率可以通过学习已知材料的分布来有效地探索成分空间以进行晶体结构预测,并采用自动编码器生成了20000种设计材料,开发了多种可合成的全新亚稳态高性能钒氧化物. ...
... [
135 ]
Fig.12 ![]()
Gómez-Bombarelli等[135 ] 将变分自解码策略应用于类药物分子和少于9个重原子的分子设计,数据样本包括QM9数据库的10.8万个分子和ZINC数据库中的25万个类药物分子数据,通过对VAE体系结构和训练超参数进行随机优化,使QM9和ZINC数据集在潜在空间的表示分别具有156和196个维度,从而捕获数据最显著的信息;以ZINC数据集为例,对于给定潜在空间中的一个点,解码器网络产生相应的材料表示,以高斯过程(Gaussian process)为训练模型完成潜在空间目标属性的预测,以药物相似性QED和合成可得性SAS为目标属性,在潜在空间中进行基于梯度的属性优化,寻找到具有较高目标性能的新的潜在变量,解码为新获取的候选材料表示.相较传统的遗传算法局部优化,该策略最终全局优化出了性能优化的新材料.Noh等[136 ] 提出了一种针对固态材料逆向设计的变分自编码策略框架,基于图像的可逆生成模型成功地发现了实验中已探明的高性能钒氧化物,生成模型的计算效率可以通过学习已知材料的分布来有效地探索成分空间以进行晶体结构预测,并采用自动编码器生成了20000种设计材料,开发了多种可合成的全新亚稳态高性能钒氧化物. ...
... Gómez-Bombarelli等[135 ] 将变分自解码策略应用于类药物分子和少于9个重原子的分子设计,数据样本包括QM9数据库的10.8万个分子和ZINC数据库中的25万个类药物分子数据,通过对VAE体系结构和训练超参数进行随机优化,使QM9和ZINC数据集在潜在空间的表示分别具有156和196个维度,从而捕获数据最显著的信息;以ZINC数据集为例,对于给定潜在空间中的一个点,解码器网络产生相应的材料表示,以高斯过程(Gaussian process)为训练模型完成潜在空间目标属性的预测,以药物相似性QED和合成可得性SAS为目标属性,在潜在空间中进行基于梯度的属性优化,寻找到具有较高目标性能的新的潜在变量,解码为新获取的候选材料表示.相较传统的遗传算法局部优化,该策略最终全局优化出了性能优化的新材料.Noh等[136 ] 提出了一种针对固态材料逆向设计的变分自编码策略框架,基于图像的可逆生成模型成功地发现了实验中已探明的高性能钒氧化物,生成模型的计算效率可以通过学习已知材料的分布来有效地探索成分空间以进行晶体结构预测,并采用自动编码器生成了20000种设计材料,开发了多种可合成的全新亚稳态高性能钒氧化物. ...
Inverse design of solid-state materials via a continuous representation
2
2019
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
... Gómez-Bombarelli等[135 ] 将变分自解码策略应用于类药物分子和少于9个重原子的分子设计,数据样本包括QM9数据库的10.8万个分子和ZINC数据库中的25万个类药物分子数据,通过对VAE体系结构和训练超参数进行随机优化,使QM9和ZINC数据集在潜在空间的表示分别具有156和196个维度,从而捕获数据最显著的信息;以ZINC数据集为例,对于给定潜在空间中的一个点,解码器网络产生相应的材料表示,以高斯过程(Gaussian process)为训练模型完成潜在空间目标属性的预测,以药物相似性QED和合成可得性SAS为目标属性,在潜在空间中进行基于梯度的属性优化,寻找到具有较高目标性能的新的潜在变量,解码为新获取的候选材料表示.相较传统的遗传算法局部优化,该策略最终全局优化出了性能优化的新材料.Noh等[136 ] 提出了一种针对固态材料逆向设计的变分自编码策略框架,基于图像的可逆生成模型成功地发现了实验中已探明的高性能钒氧化物,生成模型的计算效率可以通过学习已知材料的分布来有效地探索成分空间以进行晶体结构预测,并采用自动编码器生成了20000种设计材料,开发了多种可合成的全新亚稳态高性能钒氧化物. ...
Deep learning for synthetic microstructure generation in a materials-by-design framework for heterogeneous energetic materials
2
2020
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
... 生成对抗网络(GAN)是在GAN框架下进行对抗训练,构建生成器,通过生成器和判别器2个网络互相迭代进行模型优化,即生成器从采样噪声空间中生成数据,判别器判断生成数据是否真实,生成器对结构性噪声进行学习,产生判别器无法识别真假的数据,生成器模型和判别器模型不断交替训练,实现2个模型的共同迭代优化.该方法广泛应用于材料图像的深度学习,通过识别材料结构图像进行材料设计.Kim等[138 ] 采用GAN对多孔材料进行逆向设计,以沸石材料逆向设计为研究对象,使用31713个数据样本进行建模,预测出了用户期望范围为4 kJ/mol甲烷吸附热的沸石.在异质高能材料的多尺度模拟中,由于无法轻易获得多种类型的高能材料,Chun等[137 ] 采用GAN产生逼近于真实并且控制生成形态的微观结构,为材料计算提供丰富的微观形态图像数据,指导设计新颖的微观结构和新的异质高能材料. ...
Inverse design of porous materials using artificial neural networks
2
2020
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
... 生成对抗网络(GAN)是在GAN框架下进行对抗训练,构建生成器,通过生成器和判别器2个网络互相迭代进行模型优化,即生成器从采样噪声空间中生成数据,判别器判断生成数据是否真实,生成器对结构性噪声进行学习,产生判别器无法识别真假的数据,生成器模型和判别器模型不断交替训练,实现2个模型的共同迭代优化.该方法广泛应用于材料图像的深度学习,通过识别材料结构图像进行材料设计.Kim等[138 ] 采用GAN对多孔材料进行逆向设计,以沸石材料逆向设计为研究对象,使用31713个数据样本进行建模,预测出了用户期望范围为4 kJ/mol甲烷吸附热的沸石.在异质高能材料的多尺度模拟中,由于无法轻易获得多种类型的高能材料,Chun等[137 ] 采用GAN产生逼近于真实并且控制生成形态的微观结构,为材料计算提供丰富的微观形态图像数据,指导设计新颖的微观结构和新的异质高能材料. ...
Discovery of aluminum alloys with ultra-strength and high-toughness via a property-oriented design strategy
2
2022
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
... 借鉴编码-解码材料逆向设计思想,Wang等[140 ] 通过BP (back propagation)神经网络建立从成分到性能正向预测和从性能到成分逆向设计2个模型,利用2个模型之间的互相对抗,开发了集建模、性能预测和成分设计为一体的MLDS系统,实现了面向性能要求的合金成分逆向设计,如图13 [140 ] 所示.MLDS系统包括模型训练、成分设计和性质预测等3个子系统,以目标性能为要求,利用P2C (性能→成分)模型筛选成分组合,将筛选出的成分组合作为C2P (成分→性能)模型的输入,根据模型预测性能和目标性能的误差,选择是否推荐该成分组合,若误差超过设定阈值,则重新训练C2P模型,从而自动筛选出有效的合金成分设计方案.将MLDS应用于多元复杂高性能铜合金设计,基于数百个数据样本,开发出了抗拉强度达800 MPa、导电率为50%IACS的高强高导电铜合金,满足高端集成电路引线框架的性能需求.Jiang等[139 ] 应用MLDS设计系统,逆向设计研发出了3种新型超强高韧铝合金,合金的塑性和韧性指标与目前最先进的7136高强高韧铝合金(延伸率δ = 8%~10%、断裂韧性K IC = 33~35 MPa·m1/2 )相当,抗拉强度达700~750 MPa,比7136铝合金提高了100 MPa,并得到了实验验证. ...
A property-oriented design strategy for high performance copper alloys via machine learning
5
2019
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
... 借鉴编码-解码材料逆向设计思想,Wang等[140 ] 通过BP (back propagation)神经网络建立从成分到性能正向预测和从性能到成分逆向设计2个模型,利用2个模型之间的互相对抗,开发了集建模、性能预测和成分设计为一体的MLDS系统,实现了面向性能要求的合金成分逆向设计,如图13 [140 ] 所示.MLDS系统包括模型训练、成分设计和性质预测等3个子系统,以目标性能为要求,利用P2C (性能→成分)模型筛选成分组合,将筛选出的成分组合作为C2P (成分→性能)模型的输入,根据模型预测性能和目标性能的误差,选择是否推荐该成分组合,若误差超过设定阈值,则重新训练C2P模型,从而自动筛选出有效的合金成分设计方案.将MLDS应用于多元复杂高性能铜合金设计,基于数百个数据样本,开发出了抗拉强度达800 MPa、导电率为50%IACS的高强高导电铜合金,满足高端集成电路引线框架的性能需求.Jiang等[139 ] 应用MLDS设计系统,逆向设计研发出了3种新型超强高韧铝合金,合金的塑性和韧性指标与目前最先进的7136高强高韧铝合金(延伸率δ = 8%~10%、断裂韧性K IC = 33~35 MPa·m1/2 )相当,抗拉强度达700~750 MPa,比7136铝合金提高了100 MPa,并得到了实验验证. ...
... [140 ]所示.MLDS系统包括模型训练、成分设计和性质预测等3个子系统,以目标性能为要求,利用P2C (性能→成分)模型筛选成分组合,将筛选出的成分组合作为C2P (成分→性能)模型的输入,根据模型预测性能和目标性能的误差,选择是否推荐该成分组合,若误差超过设定阈值,则重新训练C2P模型,从而自动筛选出有效的合金成分设计方案.将MLDS应用于多元复杂高性能铜合金设计,基于数百个数据样本,开发出了抗拉强度达800 MPa、导电率为50%IACS的高强高导电铜合金,满足高端集成电路引线框架的性能需求.Jiang等[139 ] 应用MLDS设计系统,逆向设计研发出了3种新型超强高韧铝合金,合金的塑性和韧性指标与目前最先进的7136高强高韧铝合金(延伸率δ = 8%~10%、断裂韧性K IC = 33~35 MPa·m1/2 )相当,抗拉强度达700~750 MPa,比7136铝合金提高了100 MPa,并得到了实验验证. ...
... [
140 ]
Flowchart of the machine learning design system (MLDS) (a) and the performance of Cu alloys (b) (P2C—property to composition, C2P—composition to property)<sup>[<xref ref-type="bibr" rid="R140">140</xref>]</sup> Fig.13 ![]()
<strong>5 </strong>总结与展望 近年来,以实验和生产数据为基础的机器学习辅助材料设计在金属、陶瓷、高分子等结构和功能材料中得到较为广泛应用,以材料计算数据为基础的机器学习在能源材料、催化材料、拓扑材料等前沿材料领域取得了引人瞩目的进展[5 ] .机器学习与材料实验技术的融合,发展了材料自主实验技术[107 ,108 ,144 ~146 ] ,有效地提升了材料实验的效率和智能化水平.机器学习与材料第一性原理计算,以及相场和有限元模拟相结合,大幅度提升了材料计算设计和筛选的效率.限于篇幅,本文重点以实验和生产数据为基础,以在金属材料,特别是金属结构材料中的应用为案例,综述了机器学习在材料设计和优化中的研究进展. ...
... [
140 ]
Fig.13 ![]()
<strong>5 </strong>总结与展望 近年来,以实验和生产数据为基础的机器学习辅助材料设计在金属、陶瓷、高分子等结构和功能材料中得到较为广泛应用,以材料计算数据为基础的机器学习在能源材料、催化材料、拓扑材料等前沿材料领域取得了引人瞩目的进展[5 ] .机器学习与材料实验技术的融合,发展了材料自主实验技术[107 ,108 ,144 ~146 ] ,有效地提升了材料实验的效率和智能化水平.机器学习与材料第一性原理计算,以及相场和有限元模拟相结合,大幅度提升了材料计算设计和筛选的效率.限于篇幅,本文重点以实验和生产数据为基础,以在金属材料,特别是金属结构材料中的应用为案例,综述了机器学习在材料设计和优化中的研究进展. ...
Molecular de-novo design through deep reinforcement learning
1
2017
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
Deep reinforcement learning for de novo drug design
1
2018
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
Fatigue life prediction of composite materials using polynomial classifiers and recurrent neural networks
1
2007
... 以材料参数和材料因子为输入,性能为目标量,通过穷举或优化材料特征(输入)设计新材料的方法称为正向设计[129 ] ,本文第2节、4.1节和4.2节的材料预测和设计均属于正向设计.但是,由于候选材料特征空间巨大[130 ] ,试图覆盖所有候选材料特征空间的正向设计需要大量数据,尽管融合了优化算法,也难以保障材料特征空间的全局优化.材料设计和应用过程中,最先明确的往往是材料的性能需求,需要面向性能需求进行材料设计,即逆向设计[131 ] .逆向设计是以材料目标性能为输入,预测对应的材料成分、工艺与组织等材料参数.逆向设计更为注重寻优策略和方法,高效地设计出满足工程需求的新材料.材料逆向设计主要是利用数据训练编码器和解码器2个机器学习模型,编码器将复杂(非结构化)的数据点(如原子占位、结构等)映射到连续的低维空间(隐空间),解码器将隐空间向量映射回数据点[132 ~134 ] .解码策略主要包括变分自解码策略[135 ,136 ] 、对抗神经网络策略[137 ,138 ] 、机器学习设计系统(MLDS)[139 ,140 ] 、强化学习策略[141 ,142 ] 、循环神经网络策略[143 ] 等. ...
Controlling an organic synthesis robot with machine learning to search for new reactivity
1
2018
... 近年来,以实验和生产数据为基础的机器学习辅助材料设计在金属、陶瓷、高分子等结构和功能材料中得到较为广泛应用,以材料计算数据为基础的机器学习在能源材料、催化材料、拓扑材料等前沿材料领域取得了引人瞩目的进展[5 ] .机器学习与材料实验技术的融合,发展了材料自主实验技术[107 ,108 ,144 ~146 ] ,有效地提升了材料实验的效率和智能化水平.机器学习与材料第一性原理计算,以及相场和有限元模拟相结合,大幅度提升了材料计算设计和筛选的效率.限于篇幅,本文重点以实验和生产数据为基础,以在金属材料,特别是金属结构材料中的应用为案例,综述了机器学习在材料设计和优化中的研究进展. ...
The automation of science
0
2009
Functional genomic hypothesis generation and experimentation by a robot scientist
1
2004
... 近年来,以实验和生产数据为基础的机器学习辅助材料设计在金属、陶瓷、高分子等结构和功能材料中得到较为广泛应用,以材料计算数据为基础的机器学习在能源材料、催化材料、拓扑材料等前沿材料领域取得了引人瞩目的进展[5 ] .机器学习与材料实验技术的融合,发展了材料自主实验技术[107 ,108 ,144 ~146 ] ,有效地提升了材料实验的效率和智能化水平.机器学习与材料第一性原理计算,以及相场和有限元模拟相结合,大幅度提升了材料计算设计和筛选的效率.限于篇幅,本文重点以实验和生产数据为基础,以在金属材料,特别是金属结构材料中的应用为案例,综述了机器学习在材料设计和优化中的研究进展. ...
An infrastructure with user-centered presentation data model for integrated management of materials data and services
1
2021
... 数据是机器学习的基础,数据的积累与共享将会极大地推动机器学习在材料领域的应用.因此,材料数据库建设和发展将成为未来材料研发的重点领域[147 ] .材料实验、计算和生产数据自动采集和处理技术的发展与应用,以及自然语言处理技术在材料科技文献数据挖掘中的应用[148 ] ,将会极大地促进材料数据的积累,规模化的数据库建设将会推动材料研发进入大数据时代.基于材料大数据的机器学习将会极大促进新材料的发展,快速预测和高效研发出满足工程需求的新材料,成为材料科技发展、新材料研发和生产应用的重要技术支撑,推动材料研发智能化发展. ...
Data-driven materials research enabled by natural language processing and information extraction
1
2020
... 数据是机器学习的基础,数据的积累与共享将会极大地推动机器学习在材料领域的应用.因此,材料数据库建设和发展将成为未来材料研发的重点领域[147 ] .材料实验、计算和生产数据自动采集和处理技术的发展与应用,以及自然语言处理技术在材料科技文献数据挖掘中的应用[148 ] ,将会极大地促进材料数据的积累,规模化的数据库建设将会推动材料研发进入大数据时代.基于材料大数据的机器学习将会极大促进新材料的发展,快速预测和高效研发出满足工程需求的新材料,成为材料科技发展、新材料研发和生产应用的重要技术支撑,推动材料研发智能化发展. ...



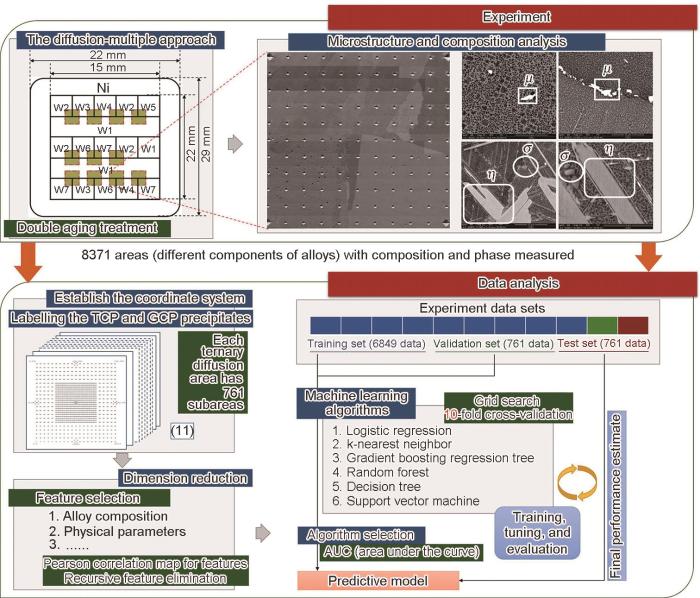
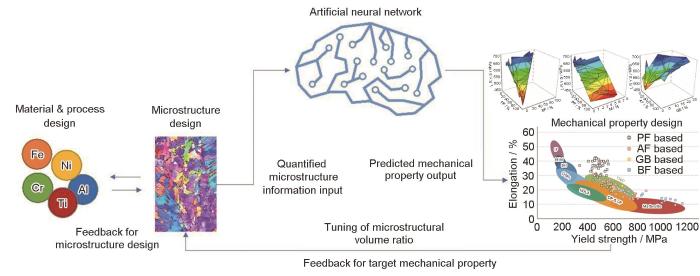
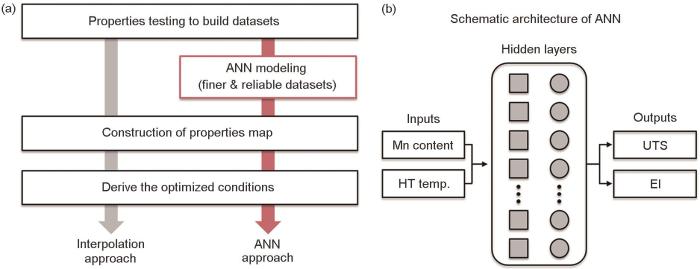
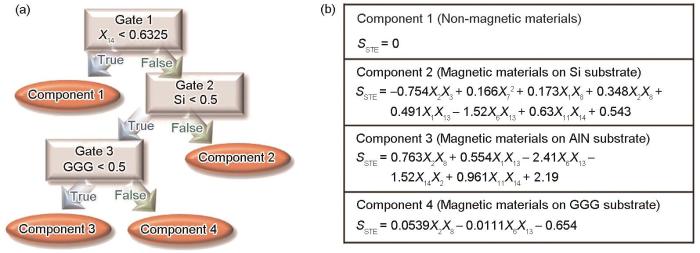
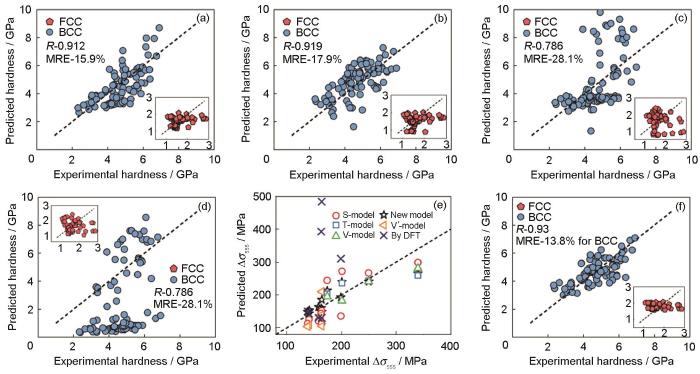
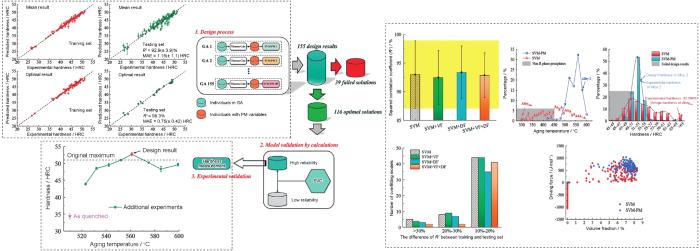
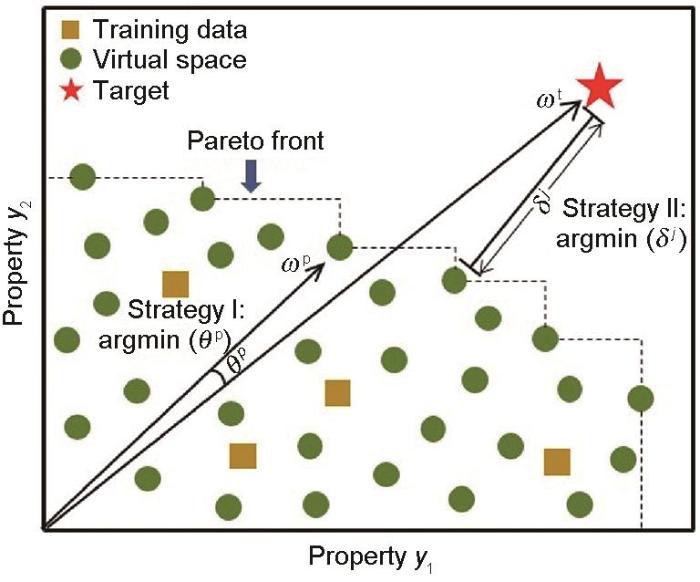
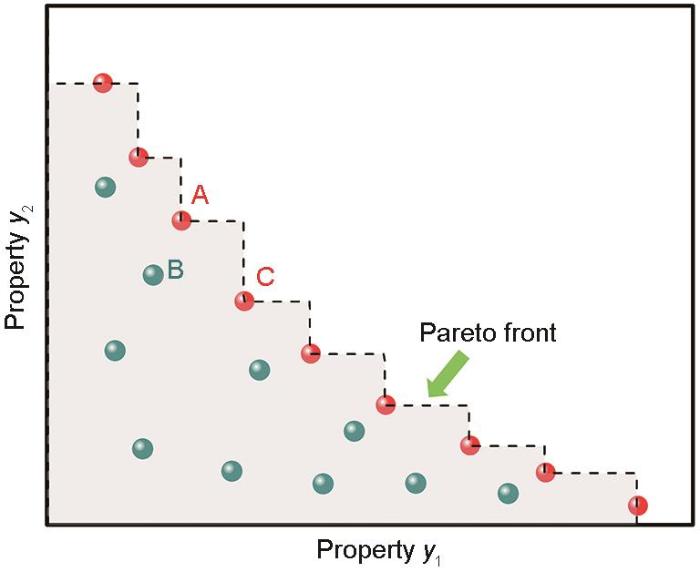
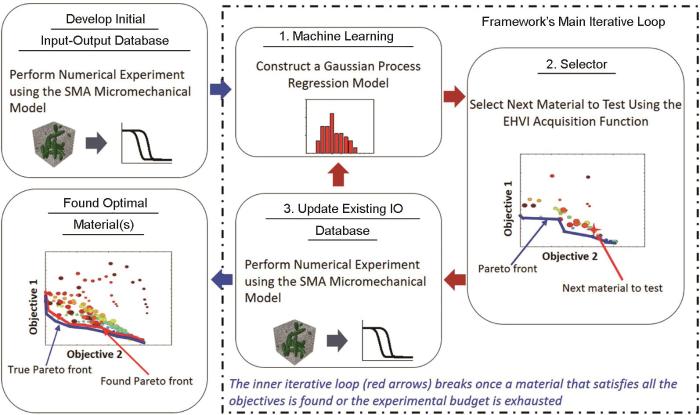
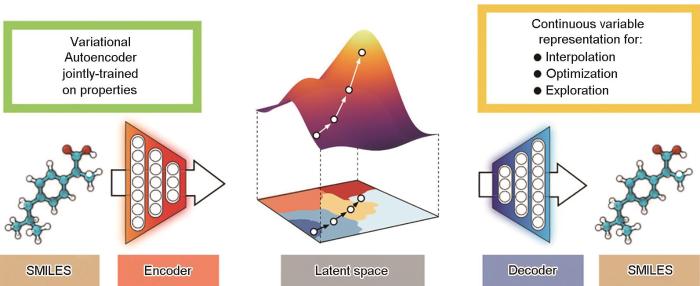
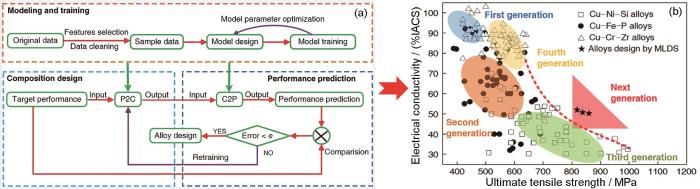

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}