


材料科学文献是服役性能构效关系知识的主要载体。随着文献数量呈指数式增长,研究人员越来越难以通过人工检索获取助力高性能材料研发的高价值信息,且这种获取方式伴随着主观性和知识局限性等消极影响。因此,如何快速从文本中自动获取高价值信息是材料文本挖掘研究亟需解决的关键问题[1]。
命名实体识别(named entity recognition,NER)技术是信息提取的一个子任务,其目标是在文本中定位并分类预先定义的命名实体类别。因其在自动挖掘文本数据中关键信息的能力而被广泛应用于电池材料[2]、固态化学材料[3]、金属氧化物[4]以及无机材料[5]等领域。材料NER识别工作主要采用传统的NER方法(即基于规则和词典[6,7]、基于统计学的方法[8,9])和基于深度学习的NER方法(如基于卷积神经网络[10]、循环神经网络[11]、双向长短期记忆网络[12]和Transformer[13]等方法)。例如,Kuniyoshi等[14]基于序列标注和启发式规则自动识别和提取隐藏在科学文献中的材料合成过程,识别精度达到0.887。这些工作体现了传统NER方法所具有的高识别准确性,但其需要依赖专家经验,且对于训练数据中未出现的实体和特征组合识别效果不佳,因此不利于模型扩展和泛化。而基于深度学习的NER方法则能够有效缓解这些问题。例如,Kim等[4]利用Word2Vec词嵌入模型表示从1902~2018年间的50万份摘要中发掘出隐含领域知识并成功预测出尚未被发现的高性能新型热电材料。进一步,该团队还通过双向长短期记忆网络(Bi-directional long short-term memory,Bi-LSTM)和条件随机场(conditional random field,CRF)模型从327万篇材料科学文献摘要中提取出8000多万个命名实体。本课题组[15]提出了基于命名实体识别与文本数据增强的自动描述符识别方法,旨在从文本数据中实现嵌入领域知识的数据增强以及从粗粒度至细粒度对任务相关的描述符进行筛选,并在NASICON型固态电解质中得到很好的应用。
目前,NER在高温合金文献挖掘研究中仍处于起步阶段。例如,Sasidhar等[16]利用过程感知深度神经网络(DNN)模型整合耐腐蚀合金加工过程和电化学测试方法的文本数据,以及合金组成和环境测试参数的数值数据,成功对新设计的合金和测试条件进行坑蚀电位预测;Wang等[6]开发的材料数据提取工具基于预定义规则和启发式文本多关系提取算法实现,从14425篇文献中提取出2531个γ′相溶解温度、密度、固相和液相线温度等钴基高温合金成分和性能数据,且与真实数据间的相对误差仅为0.81%;本课题组[17]提出了基于文本挖掘框架的知识发现方法,从来源时效性、发表权威性和作者学术地位等多维度角度对科学摘要的可信度进行量化,设计了8种描述镍基单晶高温合金的实体类型和领域词典,实现了从科学文摘中进行精准命名实体识别,最终通过分析获得了镍基单晶高温合金中重要化学成分的含量。然而,现有的基于深度学习的方法通常需要大量标注语料数据进行训练,且在处理跨领域任务时会因难以识别专业术语而迁移效果不佳。同时,其识别效果依赖于监督语料数据的质量[18~20],使得数据集构建方式至关重要。因此,如何在领域知识的指导下[21,22]构建适用于镍基单晶高温合金的高质量有标注语料数据,并据此构建针对性的深度学习NER方法是亟需解决的难点问题。
因此,本工作提出基于语义特征融合的深度学习命名实体识别(SF-NER)方法,以准确提取镍基单晶高温合金材料文本中的实体。首先,在领域知识指导下,预定义了8种材料实体类型,并结合人工标注与基于领域词典的远程标注方法,构建了高质量的镍基单晶高温合金标注语料。其次,为准确捕捉特定材料术语,提出融合独热编码(One-Hot encoding)和字节对编码(BPE)表示的词表征方式,并耦合Bi-LSTM和CRF模型对句子序列进行建模和标签预测。然后,基于子词向量对材料实体进行同义词对齐,并结合文献可信度和词频-逆文档频率(TF-IDF)对统一后的实体进行重要度分析。最后,在领域专家指导下,通过对比高重要度的实体和材料机器学习研究中已使用的描述符,验证该方法对于挖掘材料描述符的有效性,从而为机器学习建模推荐合适的特征。该方法可以加速从文本中发现镍基单晶高温合金材料知识并有望推广至其他材料领域。
1 方法
基于SF-NER方法进行镍基单晶高温合金文献挖掘及应用流程如图1所示。首先,以镍基单晶高温合金材料文献摘要文本为基础,经过文本预处理、实体类型标注、BIO标注(其中“B”表示实体的开头(Begin),“I”表示实体的中间部分(Inside),“O”表示非实体(Outside))和实体标签优化等步骤,构建适用于NER任务的高质量文本数据集;基于此,训练融合语义特征的Bi-LSTM-CRF模型,耦合One-Hot[23]与BPE编码[24]对材料领域文本进行特征融合的向量化表示,并通过Bi-LSTM和CRF模型对语句序列进行标签预测,利用子词级特征对同义实体进行对齐,从而得到镍基单晶高温合金材料实体集;最后,以镍基单晶高温合金材料描述符挖掘与推荐为例,探索本文方法在材料领域研究中的应用,即结合文献可信度[17]和TF-IDF方法[25]对统一后的实体进行重要度分析,并在材料领域专家指导下进行机器学习建模用描述符推荐,从而达到对镍基单晶高温合金材料的构效关系知识的挖掘与应用。
图1
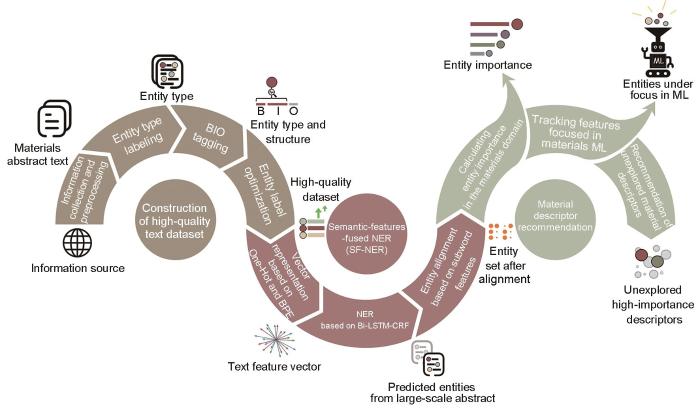
图1
基于语义特征融合的深度学习命名实体识别(SF-NER)方法的镍基单晶高温合金文献挖掘及应用流程图
Fig.1
Diagram for literature mining and field application of nickel-based single crystal superalloys using the SF-NER (BPE—byte-pair encoding, NER—named entity recognition, ML—machine learning, CRF—conditional random field, B—the beginning of an entity (Begin), I—the inside of an entity (Inside), O—outside of an entity (Outside))
1.1 高质量文本数据集构建
高质量的材料文本数据集是实现高精度材料文本挖掘的基础。因此,本工作首先开展了适用于镍基单晶高温合金材料NER任务的高质量科学文本数据集构建研究。具体包含3个阶段:材料科学文献信息采集与预处理、基于预定义实体类型的材料文本标注和融合领域知识的材料实体标签优化。
在材料科学文献信息采集与预处理阶段,以“nickel base single crystal superalloy”及其同义短语为检索主题,从Web of Science数据库中收集了631篇摘要,并采用NLTK (Natural Language Toolkit)[26]工具对摘要文本进行分词和词性标注以完成预处理。
定义1:材料实体类型= <APL, CMT, CMP, CNT, FAT, PRO, PRP, STE>。其中APL、CMT、CMP、CNT、FAT、PRO、PRP、STE分别代表应用(Application)、表征(Characterization)、成分(Composition)、条件(Condition)、特征(Feature)、加工(Processing)、属性(Property)和结构(Structure),是用来描述和表达材料信息的特殊术语。
在融合领域知识的材料实体标签优化阶段,针对基于人工标注的方法存在标注不一致与标签不均衡的问题,本工作采用基于领域词典的远程监督标注方法[17]自动化地对摘要文本再次进行标注。该方法由词典中的领域知识驱动,能够捕捉材料特征明显的实体。进一步,在领域专家的指导下整合2种标注结果不一致的部分,从而确保标注数据的准确性和覆盖率,提升标注数据的质量。最终,形成了基于人工标注的文本数据集A_ManualLabeling和优化后的高质量文本数据集A_DomainDictionary。详细信息见补充材料表S2。
1.2 融合语义特征的Bi-LSTM-CRF命名实体识别
1.2.1 基于One-Hot与BPE的材料文本向量表示
One-Hot编码通过将每个单词映射为一个高维稀疏向量实现词表示,其中向量的维度与词汇表的规模相等,且仅有一个元素为1,其余为0。这种表示方法直观简洁,但在处理大规模语料库时容易导致维度灾难。BPE编码采用子词级别的策略,通过迭代合并语料库中频繁出现的字符序列生成子词,并将材料文本表示为这些子词的序列,有效缓解了未登录词和稀有词问题,同时降低了向量的维度。
为了兼顾One-Hot编码的离散特性和BPE编码的词级别的表示优势,本工作提出一种融合策略。具体而言,每个单词首先通过One-Hot编码转换为高维稀疏向量。然后,使用BPE编码对单词进行子词分解,并将每个子词映射为固定维度的向量。最后,通过拼接单词的One-Hot向量与其子词向量,形成融合词向量。这种融合向量不仅捕捉了单词的语法和语义信息,还增强了模型对未登录词和稀有词的处理能力,从而提升命名实体识别的准确性。材料文本向量融合过程如式(
式中,
1.2.2 基于Bi-LSTM-CRF的命名实体识别
为缓解机器学习在执行跨领域任务时迁移效果不佳的问题,本工作采用基于深度学习的命名实体识别方法Bi-LSTM-CRF进行实体标签预测。Bi-LSTM-CRF模型是一种常用于序列标注任务的深度学习模型。该模型结合Bi-LSTM和CRF模型,旨在通过学习上下文信息和标记序列之间的依赖关系来提高序列标注的性能。
首先,使用Bi-LSTM网络学习材料文本序列在前后2个方向上的信息。将融合One-Hot与BPE 2种编码形式的词向量输入到Bi-LSTM中,通过双向遍历文本序列同时捕捉到单词前后的上下文信息。然后,将2个方向上的序列处理结果进行拼接。其中,Bi-LSTM在t时刻隐藏层状态
式中,
其次,利用CRF模型对Bi-LSTM层的输出进行解码,计算最优的标签序列。CRF考虑了序列中相邻标签之间的依赖关系,可以有效地捕获标签之间的转移特征,并通过联合概率分布对标签序列进行全局归一化,从而提高序列标注的准确性。假设给定输入序列的Bi-LSTM输出序列为h = (h1, h2,…, hT ),其中
式中, W 是权重矩阵;
最后,句子
式中,
图2
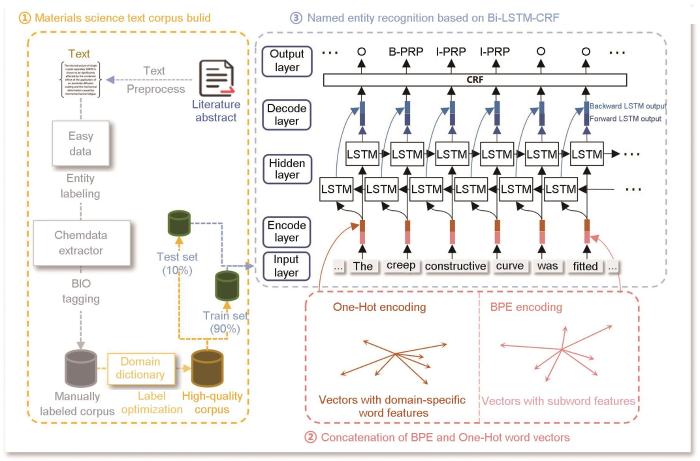
图2
基于双向长短期记忆网络-条件随机场(Bi-LSTM-CRF)模型的材料命名实体识别框架
Fig.2
Material named entity recognition framework for Bi-LSTM-CRF (Bi-LSTM—bi-directional long short term memory, PRP—property)
1.2.3 基于子词特征的材料实体统一
在镍基单晶高温合金领域,统一术语的多样表达形式和书写习惯是一项关键任务。为有效合并同义实体,本工作采用基于BPE的方法,该方法通过深入分析材料实体词的子词特征,有助于识别实体间的共性,进而实现同义实体的有效合并。具体而言,首先通过BPE编码生成每个实体的嵌入向量,以捕捉实体的语义特征。然后,通过计算实体嵌入向量间的余弦相似度,评估实体间的语义相似性。进一步,基于设定的相似度阈值,判断是否将2个实体归类为同一类别。最后,采用并查集数据结构处理实体集群的合并与查询操作,通过并查集中的“查找”和“合并”功能,将相似度超过阈值的实体合并至同一集群,完成实体统一。该方法的流程如补充材料算法S2所示。
2 实验
2.1 实验设置
本工作模型的参数设置详见补充材料表S3。为了对比不同模型的性能,采用准确率(Precision)、召回率(Recall)及F1值(F1-score)作为评价指标,计算过程如式(
2.2 实验结果与分析
2.2.1 SF-NER模型性能验证
表1 不同模型在数据集A_DomainDictionary上的准确率、召回率和F1值
Table 1
| Model | Precision | Recall | F1-score |
|---|---|---|---|
| BERT-Bi-GRU-CRF | 0.57 | 0.62 | 0.60 |
| Bi-LSTM(Glove)-CRF | 0.80 | 0.81 | 0.80 |
| Bi-LSTM(OneHot)-CRF | 0.81 | 0.81 | 0.81 |
| Bi-LSTM(OneHot-Glove)-CRF | 0.82 | 0.83 | 0.82 |
| SF-NER | 0.84 | 0.84 | 0.84 |
在表1中,SF-NER模型在准确率、召回率和F1值上均优于BERT-Bi-GRU-CRF模型,达到了84%,证明了Bi-LSTM-CRF在处理镍基单晶高温合金材料文本数据集上的有效性,这归因于Bi-LSTM能够有效捕捉输入序列的上下文语义特征,而以Encoder为基础的BERT模型在执行特定领域任务时高度依赖于其预训练过程,且相较于传统深度学习模型而言,在适应下游任务时对数据量的要求更高。此外,通过特征编码消融实验,本工作探讨了编码策略对模型性能的影响。由于BPE编码词向量无法单独应用于材料NER模型,采用Glove[30]编码模型作为平替。通过比较Bi-LSTM(OneHot-Glove)-CRF模型与仅使用Glove或One-Hot的Bi-LSTM-CRF模型表现,发现前者在各项指标上均表现更佳,从而验证了词向量融合策略的有效性。进一步地,SF-NER相较于Bi-LSTM(OneHot-Glove)-CRF模型在准确率、召回率和F1值上均提升了2%左右。这是因为融合BPE和One-Hot的表征方法能够表示子词级别的词向量,使得Bi-LSTM网络充分学到特定领域词特征,从而提升模型对文本标签的学习和预测能力。
图3
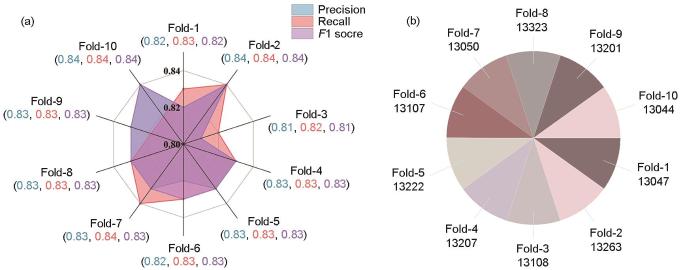
图3
SF-NER模型在数据集A_DomainDictionary上的十折交叉验证结果
Fig.3
Ten-fold cross-validation results of the SF-NER on dataset A_DomainDictionary
(a) performance of SF-NER during ten-fold cross-validation
(b) number of word entities recognized by SF-NER during ten-fold cross-validation
2.2.2 数据集质量验证
为了评估基于领域词典的远程标注方法对于文本数据集质量方面的提升效果,对比了不同模型在数据集A_ManualLabeling以及A_DomainDictionary上的表现,实验结果如表2所示。结果显示,所有模型在质量优化后的数据集A_DomainDictionary上的表现显著优于在人工标注数据集A_ManualLabeling上的表现。特别是在基准模型BERT-Bi-GRU-CRF上,F1差值高达0.16。这表明,A_DomainDictionary数据集具备更高的质量;结合领域知识驱动的远程标注方法能够有效构建高质量材料文本数据集,从而显著提高模型的预测性能。
表2 不同模型在2个数据集上的表现(F1值)
Table 2
| Model | A_ManualLabeling | A_DomainDictionary |
|---|---|---|
| BERT-Bi-GRU-CRF | 0.44 | 0.60 |
| Bi-LSTM(Glove)-CRF | 0.75 | 0.80 |
| Bi-LSTM(OneHot-BPE)-CRF | 0.78 | 0.84 |
2.2.3 材料实体识别结果分析
进一步分析SF-NER模型对不同类型实体的识别效果,其表现如图4所示。其中,SF-NER模型对于“Condition”类实体的识别效果最好,F1值达到80%;而对于“Feature”类实体的识别效果最差,F1值仅有32%,这一表现主要源于“Feature”类型实体在文本中的边界模糊性。例如,“single-crystal”作为独立实体或与“alloy”结合形成“sing-crystal alloy”均可被视作为正确识别,但此类边界模糊性增加了识别的不确定性,从而影响了模型对于该类别实体的识别效果。为了避免这种影响,可考虑更严格地定义“Feature”类型实体的边界。
图4
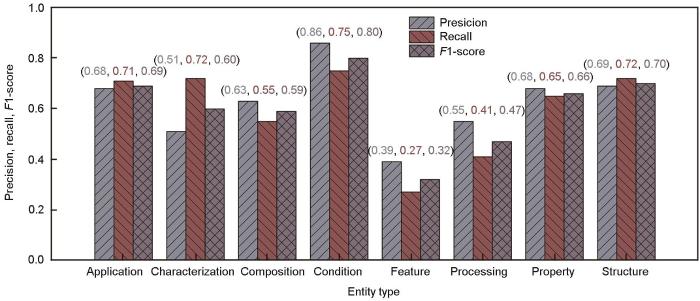
图4
SF-NER模型对不同类型实体的识别准确率、召回率和F1值
Fig.4
Precision, recall, and F1-score of the SF-NER model for different-type entities
3 应用探索
本工作将可用描述符的挖掘与推荐作为应用实例用于验证SF-NER方法进行知识挖掘的有效性。具体地,首先采用SF-NER模型从大规模摘要文本中抽取实体,并结合文献可信度评估方法和TF-IDF方法计算实体的重要度;其次,将实体的重要度作为推荐系数,并进行推荐系数排名与描述符推荐。最终,在材料领域专家的指导下,对具有高重要度的实体进行影响力分析,探讨此类实体对镍基单晶高温合金研究的促进作用。
3.1 实体重要度计算
为了提供描述符推荐所需的数据基础,采用2.1节中所述的数据采集方法,从Web of Science数据库中收集了1996年~2024年1月期间的5020篇有关镍基单晶高温合金材料的科学文献摘要,并对其进行预处理,以形成大规模的待挖掘摘要文本库。然后,使用2.1节中基于631篇摘要构建的高质量文本数据集训练SF-NER模型,用以从待挖掘的摘要文本库中识别材料实体,并对所识别的实体进行实体统一处理。最后,结合文献可信度评估方法与TF-IDF技术,对SF-NER模型识别出的实体进行重要度(IE)计算。其计算公式如
式中,
3.2 基于重要度的描述符推荐
为了探究影响镍基单晶高温合金材料性能的关键因素,本工作进行了描述符推荐研究。首先,据补充材料表S4可知,在8个实体类型中,“Characterization”、“Composition”、“Processing”、“Property”和“Structure”类型的实体多为粗粒度可推广的实体。因此,为了获得抽象且可用性强的描述符,本工作将推荐描述符的候选来源范围限定在上述5类实体中。
接着,以重要度作为推荐系数,从各类型实体中选取推荐系数不低于0.19的共385个实体作为推荐描述符。同时,在材料领域专家的指导下,从22篇基于机器学习的镍基单晶高温合金材料构效关系研究文献中统计出95个已用于机器学习建模的描述符,具体如补充材料表S5所示。为研究各类型描述符的推荐程度及其在机器学习建模中的实际应用情况,对各类型的描述符以推荐系数进行降序排序,并统计了本工作推荐的385个描述符与95个已用于机器学习建模的描述符之间的重叠情况,如图5所示(部分展示)。通过对比发现,这95个描述符中有高达82个(图中红色叶子节点)为本工作推荐的描述符,且在各类型描述符中均排名靠前。这些描述符是能够有效预测和分析影响镍基单晶高温合金服役性能的关键因素,其高被推荐率及推荐高排名验证了本方法可以有效地为机器学习建模推荐描述符。
图5
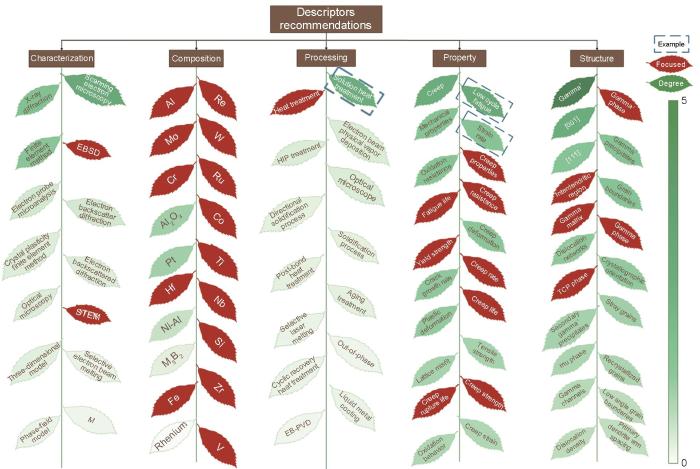
图5
推荐的描述符及已被材料机器学习关注的实体(部分展示)
Fig.5
Recommended descriptor importance ranking and entities already focused on in materials machine learning (partial display) (HIP—hot isostatic pressing, TCP—topologically close-packed phases, EB-PVD—electron beam-physical vapor deposition, SRZ—secondary reaction zone, IDZ—interdiffusion zone)
此外,图中排名较高(图中绿色叶子的颜色深浅及叶子高低对应推荐系数高低)的绿色叶子节点指代的描述符虽不在82个已用于机器学习建模的描述符之中,但其仍具备高重要度,其具体重要度数值见补充材料表S6,有为未来材料机器学习建模所用的潜力。例如,在图5虚线框住的示例中,重要度为1.9的“strain rate”(应变率)实体,其可能对合金材料的塑性和断裂行为的预测有帮助。因为高应变率通常会导致材料内部应力集中和变形局部化现象加剧,从而降低材料的塑性变形能力和抗断裂能力。实体重要度为2.62的“solution heat treatment” (固溶热处理) 是一种通过控制合金在高温下固溶体的形成和溶解来改善材料性能的热处理工艺。固溶热处理过程中的参数可能是用于预测合金材料硬度的潜在因子,因为在固溶热处理过程中,合金中的固溶体溶解均匀,随后通过快速冷却或固溶体再结晶,可以获得细小、均匀的晶粒结构,从而显著提高了材料的硬度。类似地,实体重要度为2.94的“low cycle fatigue” (低周疲劳) 指材料在较低的应变振幅下经历的疲劳过程。低周疲劳数据可能利于对合金材料残余寿命的精确预测,因为在低应变振幅下,重复加载会逐渐积累微观损伤和位错,导致材料强度和耐久性下降,同时增加疲劳裂纹形成的风险,进一步缩短材料的残余寿命。
综上所述,本研究可以从海量材料科学文本中自动获取潜在的高重要度描述符。材料专家可从中遴选并加工出可信、可靠的描述符作为机器学习建模的输入特征,有望进一步推动对镍基单晶高温合金服役性能与复杂微观内禀特性的深入挖掘。
4 结论
(1) 提出基于语义特征融合的深度学习命名实体识别方法SF-NER。融合One-Hot和BPE的词表征方式以捕捉关键领域术语语义,并设计Bi-LSTM-CRF模型准确识别目标实体类型。该方法在高质量镍基单晶高温合金语料库上对8类材料实体识别的F1值达到0.84,优于其他基于深度学习的NER方法。
(2) 构建了面向镍基单晶高温合金的高质量语料库。定义了应用、表征、成分、条件、形貌、工艺、性能、结构等8种材料实体类型,利用基于领域词典的高质量材料科学文本挖掘数据集构建方法从631篇镍基单晶高温合金材料摘要中标注了涵盖8类材料实体类型的19405个实体。
(3) 在领域专家指导下从5020篇镍基单晶高温合金材料摘要文本中挖掘并推荐出精准刻画“材料成分、工艺、组织、性能、服役行为”构效关系的高重要度描述符,有望进一步推动对镍基单晶高温合金服役性能构效关系的深入挖掘。研究人员可根据实际需求对实体类型进行更新与调整,以确保模型能够准确捕捉领域的实体类别信息,从而实现本工作方法有效扩展至其他材料领域的知识发现。
文中补充材料可通过以下网址查看:
参考文献
Applying data-driven machine learning to studying electrochemical energy storage materials
[J].
数据驱动的机器学习在电化学储能材料研究中的应用
[J].
储能电池的关键是材料。继实验观测、理论研究和计算模拟之后,数据驱动的机器学习具有快速捕捉材料成分-结构-工艺-性能间复杂构效关系的优势,有望为电化学储能材料的研发提供新的范式。本文从结构化和非结构化数据驱动两方面,系统评述了机器学习在电化学储能材料研究中的最新进展。全面概括了可用于电化学储能材料机器学习的国内外材料数据库,分析了其数据的收集、共享和质量检测存在的问题;重点阐述了电化学储能材料中机器学习的工作流程和应用,包括结构化数据驱动下数据收集、特征工程和机器学习建模以及图形、表征图像和文献文本这类非结构化数据驱动下的模型构建和应用。进一步,厘清电化学储能材料领域机器学习面临的三大矛盾且给出对策,即高维度与小样本数据的矛盾与协调、模型复杂性与易用性的矛盾与统一、模型学习结果与专家经验的矛盾与融合,并提出构建“领域知识嵌入的机器学习方法”有望调和这些矛盾。本文将为机器学习在电化学储能材料设计和性能优化中的应用提供参考。
What can text mining tell us about lithium-ion battery researchers' habits?
[J].
Text mining for processing conditions of solid-state battery electrolytes
[J].
Materials synthesis insights from scientific literature via text extraction and machine learning
[J].
Semi-supervised machine-learning classification of materials synthesis procedures
[J].
Automated pipeline for superalloy data by text mining
[J].
ChemicalTagger: A tool for semantic text-mining in chemistry
[J].
tmChem: A high performance approach for chemical named entity recognition and normalization
[J].
Virtual screening of inorganic materials synthesis parameters with deep learning
[J].
Backpropagation applied to handwritten zip code recognition
[J].
A learning algorithm for continually running fully recurrent neural networks
[J].
Long short-term memory
[J].Learning to store information over extended time intervals by recurrent backpropagation takes a very long time, mostly because of insufficient, decaying error backflow. We briefly review Hochreiter's (1991) analysis of this problem, then address it by introducing a novel, efficient, gradient-based method called long short-term memory (LSTM). Truncating the gradient where this does not do harm, LSTM can learn to bridge minimal time lags in excess of 1000 discrete-time steps by enforcing constant error flow through constant error carousels within special units. Multiplicative gate units learn to open and close access to the constant error flow. LSTM is local in space and time; its computational complexity per time step and weight is O(1). Our experiments with artificial data involve local, distributed, real-valued, and noisy pattern representations. In comparisons with real-time recurrent learning, back propagation through time, recurrent cascade correlation, Elman nets, and neural sequence chunking, LSTM leads to many more successful runs, and learns much faster. LSTM also solves complex, artificial long-time-lag tasks that have never been solved by previous recurrent network algorithms.
Attention is all you need
[A].
Annotating and extracting synthesis process of all-solid-state batteries from scientific literature
[A].
An automatic descriptors recognizer customized for materials science literature
[J].
Enhancing corrosion-resistant alloy design through natural language processing and deep learning
[J].
Domain knowledge discovery from abstracts of scientific literature on nickel-based single crystal superalloys
[J].
A high-quality dataset construction method for text mining in materials science
[J].
高质量的材料科学文本挖掘数据集构建方法
[J].
A data quality and quantity governance for machine learning in materials science
[J].
面向材料领域机器学习的数据质量治理
[J].
Data quantity governance for machine learning in materials science
[J].
Machine learning embedded with materials domain knowledge
[J].
材料领域知识嵌入的机器学习
[J].
Detection method on data accuracy incorporating materials domain knowledge
[J].Due to the characteristics of small samples, high dimensions, and much noise, materials data often produce inconsistent results with those obtained from domain experts when used for machine learning modeling. For the whole process of machine learning, developing machine learning models embedding materials domain knowledge is a solution to this problem. The accuracy of materials data directly affects the reliability of data-driven materials performance prediction. Here, a data accuracy detection method incorporating materials domain knowledge is proposed by focusing on the data preprocessing stage in the machine learning application process. Firstly, a materials domain knowledge database is constructed based on the knowledge from materials experts. Secondly, it is coordinated with the data-driven data accuracy detection method to perform single-dimensional data accuracy detection based on the rule for value of descriptors, multi-dimensional data correlation detection based on the rule for correlation of descriptors, and full-dimensional data reliable detection based on multi-dimensional similar sample identification strategy from both data and domain knowledge perspectives. For the anomalous data identified at each stage, they are corrected by incorporating the materials domain knowledge. Furthermore, domain knowledge is incorporated into the whole process of the data accuracy detection method to ensure high accuracy of the dataset from the initial stage. Finally, experiments on the NASICON-type solid electrolyte activation energy prediction dataset demonstrate that this method can effectively identify anomalous data and make reasonable corrections. Compared with the original dataset, the prediction accuracy of all six machine learning models based on the revised dataset is improved to different degrees, among which R2 achieves a 33% improvement on the optimal model.
融合材料领域知识的数据准确性检测方法
[J].材料数据由于小样本、高维度、噪音大等特性, 用于机器学习建模时常常会产生与领域专家认知不一致的结果。面向机器学习全流程, 开发材料领域知识嵌入的机器学习模型是解决这一问题的有效途径。材料数据的准确性直接影响了数据驱动的材料性能预测的可靠性。本研究针对机器学习应用过程中的数据预处理阶段, 提出了融合材料领域知识的数据准确性检测方法。该方法首先结合材料专家认知构建了材料领域知识库。然后, 将其与数据驱动的数据准确性检测方法结合, 从数据和领域知识两个角度对材料数据集进行基于描述符取值规则的单维度数据正确性检测、基于描述符相关性规则的多维度数据相关性检测以及基于多维相似样本识别策略的全维度数据可靠性检测。对于每一阶段识别出的异常数据, 结合材料领域知识进行修正, 并将领域知识融入到数据准确性检测方法的全过程以确保数据集从初始阶段就具有较高准确性。最后该方法在NASICON型固态电解质激活能预测数据集上的实验结果表明: 本研究提出的方法可以有效识别异常数据并进行合理修正。与原始数据集相比, 基于修正数据集的6种机器学习模型的预测精度都有不同程度的提升。其中, 在最优模型上R<sup>2</sup>提升了33%。
A primer on neural network models for natural language processing
[J].
Natural language processing (almost) from scratch
[J].
A statistical interpretation of term specificity and its application in retrieval
[J].
NLTK: The natural language toolkit
[A].
Natural language processing: an introduction
[J].To provide an overview and tutorial of natural language processing (NLP) and modern NLP-system design.This tutorial targets the medical informatics generalist who has limited acquaintance with the principles behind NLP and/or limited knowledge of the current state of the art.We describe the historical evolution of NLP, and summarize common NLP sub-problems in this extensive field. We then provide a synopsis of selected highlights of medical NLP efforts. After providing a brief description of common machine-learning approaches that are being used for diverse NLP sub-problems, we discuss how modern NLP architectures are designed, with a summary of the Apache Foundation's Unstructured Information Management Architecture. We finally consider possible future directions for NLP, and reflect on the possible impact of IBM Watson on the medical field.
Error bounds for convolutional codes and an asymptotically optimum decoding algorithm
[J].
BERT-BIGRU-CRF: A novel entity relationship extraction model
[A].
GloVe: Global vectors for word representation
[A].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}